Помните, в школе всегда были этакие «всезнайки»? Каким-то образом, вне зависимости от предмета, им удавалось увязывать в голове разрозненные блоки информации и приходить к пониманию вопроса.
Я привел этот пример потому, что, по-моему, он хорошо отражает будущее компаний: им приходится становиться «всезнайками» от бизнеса. Сейчас, благодаря Hadoop и другим технологиям так называемых Больших данных, компании могут рассматривать до недавнего времени разрозненную информацию как единое целое. Вообразите, что это может означать. Авиалинии будут знать, когда ценный для них клиент сталкивался с неприятностями в момент вылета, и, благодаря этому, постараются улучшить обслуживание во время обратного полета. Медики смогут увязывать разрозненные виды информации, такие как результаты МРТ, показатели давления, данные о фибрилляции предсердий для предсказания возможности инфаркта или инсульта.
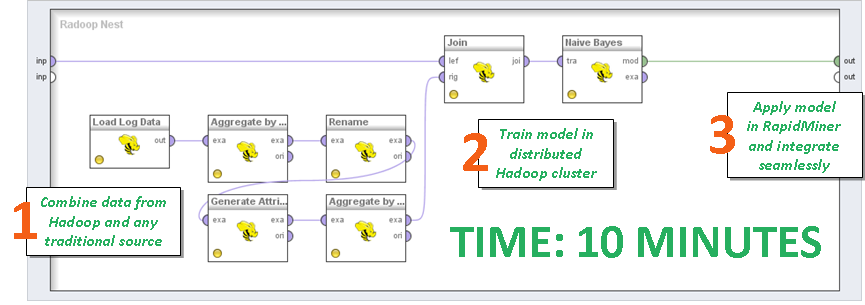
Речь идет не только об объемах данных – а именно это приходит в голову большинству при упоминании о Больших данных. Напротив, главное в том, что между этими данными – вне зависимости от их типа и источника – скрыты крайне важные взаимосвязи, как, например, между информацией из колл-центра, данными по пользованию веб-сайтом и показателями продаж. Для меня разница в этих подходах существенна. Проще говоря, размер тут не имеет значения.