
В последнее время в научных публикациях всё чаще упоминается алгоритм достижения консенсуса в распределенных системах под названием Paxos. Среди таких публикаций ряд работ сотрудников Google (Chubby, Megastore, Spanner) ранее уже частично освещенных на хабре, архитектуры систем WANdisco, Ceph и пр. В то же время, сам алгоритм Paxos считается сложным для понимания, хоть и основывается он на элементарных принципах.
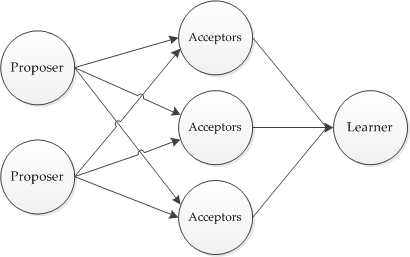
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.
В этой статье я постараюсь исправить эту ситуацию и рассказать об этом алгоритме понятным языком, как когда-то это попытался сделать автор алгоритма Лесли Лэмпорт.










 Приветствую бойцов невидимого бэкенда!
Приветствую бойцов невидимого бэкенда!