
Знаете, что самое раздражающее в A/B тестах? Это ожидание результатов.
А что, если можно ускорить процесс и получить нужные данные быстрее? Сегодня расскажу, как разогнать A/B тесты, чтобы не терять время зря и быстрее получать результаты.

Аналитик
Знаете, что самое раздражающее в A/B тестах? Это ожидание результатов.
А что, если можно ускорить процесс и получить нужные данные быстрее? Сегодня расскажу, как разогнать A/B тесты, чтобы не терять время зря и быстрее получать результаты.

Логические операции играют важную роль в программировании. Они используются для создания условных конструкций и составления сложных алгоритмов. В Python для проведения логических операций используются логические операторы:
not — логическое отрицание
and — логическое умножение
or — логическое сложение
В этой статье мы поговорим о неочевидных деталях и скрытых особенностях работы логических операторов в Python.

В данной статье мы рассмотрим, как бакетизация может существенно ускорить вычисления и представим график зависимости отношения времени на расчеты p-value без бакетизации к времени на расчеты с бакетизацией.


Большая подборка для аналитиков данных, продуктовых аналитиков, веб аналитиков, маркетинговых аналитиков и особенно тех, кто хочет ими стать. От автора Telegram-канала «Аналитика и Growth mind-set».
Но прежде несколько важных моментов:

Это затмение называют "Великим Американским Затмением". Можно догадаться почему. Зона его видимости — североамериканский континент. За незначительным исключением, нигде на суше, кроме США, Канады, Мексики и нескольких стран центральной Америки, затмение не видно.
Да — в зоне видимости будет еще акватория Тихого и Атлантического океанов, ряд островов расположенных в них, Гренландия и самый краешек северной Европы — совсем уже на излете (во время захода Солнца и в очень малых фазах). Но если говорить о полосе полной фазы, в которой для наблюдателей Солнце затмится Луною совершенно, наступят густые сумерки, и на небе вспыхнут самые яркие звезды и планеты, то она коснется лишь трех стран: Мексики, США и Канады.

Всем привет! Случались ли у вас ситуации, когда количество DAG’ов в вашем Airflow переваливает за 800 и увеличивается на 10-20 DAG’ов в неделю? Согласен, звучит страшно, чувствуешь себя тем героем из Subway Surfers… А теперь представьте, что эта платформа является единой точкой входа для всех аналитиков из различных команд и DAG’и пишут более 50 различных специалистов. Подкосились ноги, холодный пот и желание уйти из IT?
Не спешите паниковать, под катом я расскажу о том, как контролировать потребление ресурсов DAG’ов Airflow для предупреждения неоптимально написанных DAG’ов и борьбы с ними.
Меня зовут Давид Хоперия, я Data Engineer в департаменте данных Ozon.Fintech и моим основным инструментом является Apache Airflow, поэтому настало время углубиться в детали его работы.

Поскольку блокировки интернета в РФ в последние недели и месяцы многократно активизировались, а маразм все крепчает и крепчает, стоит еще раз поднять тему обхода этих самых блокировок (и делаем ставки, через сколько дней на эту статью доброжелатели напишут донос в РКН чтобы ограничить к ней доступ на территории страны).
Вы, наверняка, помните отличный цикл статей на Хабре в прошлом году от пользователя MiraclePtr, который рассказывал о разных методах блокировок, о разных методах обхода блокировок, о разных клиентах и серверах для обходов блокировок, и о разных способах их настройки (раз, два, три, четыре, пять, шесть, семь, восемь, десять, десять, и вроде были еще другие), и можете спросить, а зачем еще одна? Есть две основные причины для этого.
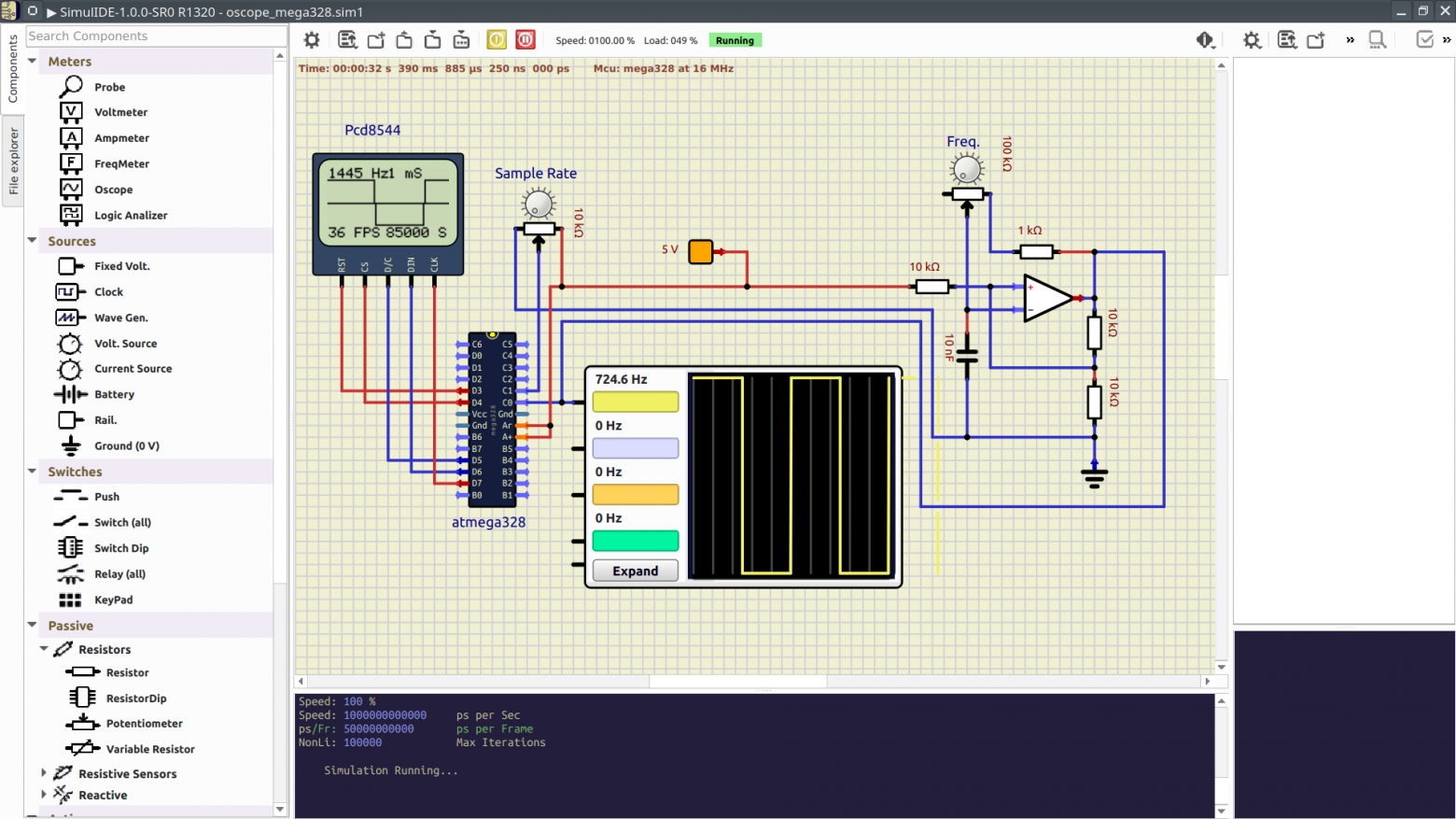
В этой заметке я решил рассказать о SimulIDE. Это относительно новое программное средство с открытым исходном кодом, предназначенное для моделирования 8-битных микроконтроллеров семейств AVR и PIC, а также прочих электронных схем. По интерфейсу SimulIDE напоминает Proteus. SimulIDE кроссплатформенный и работает под Linux, Windows и Mac. Далее будут рассмотрены основные возможности этого симулятора и рассказано о моих личных впечатлениях от работы с данной программой.

Приветствую!
Stan - это библиотека на C++, предназначенная для байесовского моделирования и вывода. Она использует сэмплер NUTS, чтобы создавать апостериорные симуляции модели, основываясь на заданных пользователем моделях и данных. Так же Stan может использовать алгоритм оптимизации LBFGS для максимизации целевой функции, к примеру как логарифмическое правдоподобие.
Для облегчения работы с Stan из языка программирования R доступен пакет rstan, который предоставляет интерфейс R для Stan.
Сегодня мы и рассмотрим этот пакет.

Привет, Хабр!
Параллельные вычисления – подход к проектированию и выполнению программ, который позволяет ускорить обработку данных и вычисления, используя множество процессоров или ядер процессора одновременно.
В ЯП R паралельное выполнение также имеет свои варианты реализации. Рассмотрим их в статье.
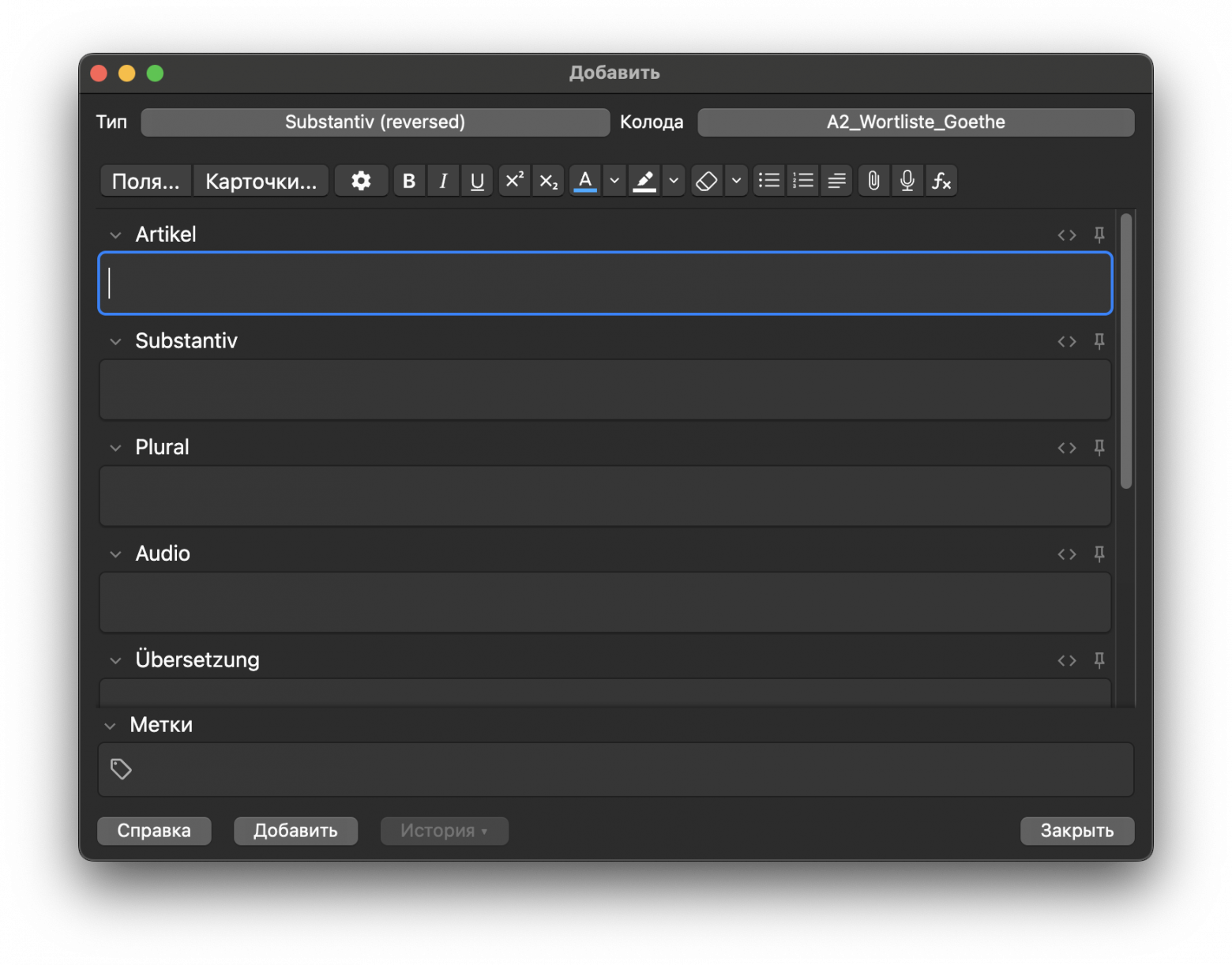
Я захотел продолжить некогда заброшенное изучение немецкого языка. Долгое время на просторах интернета слышал мнение, что карточки Anki – чуть ли не самый лучший способ изучение языка, и решил, собственно, посмотреть что к чему. Рекомендации YouTube привели меня к интересному видео, где автор рассказывает о своем шаблоне карточек с немецкими словами. Автор не желал публиковать свою колоду, и не найдя аналогов среди публичных колод, я принялся делать свое. Конечно же не вручную.
Для этой задачи использую LLM (Large Language Models - например, chatGPT или opensouce модели) для внутренних задач (а-ля поиск или вопрос-ответную систему по необходимым данным).
Я пишу на языке R и также увлекаюсь NLP (надеюсь, я не один такой). Но есть сложности из-за того, что основной язык для LLM - это python. Соответственно, на R мало примеров и документации, поэтому приходится больше времени тратить, чтобы “переводить” с питона, но с другой стороны прокачиваюсь от этого.
Чтобы не городить свою инфраструктуру, есть уже готовые решения, чтобы быстро и удобно подключить и использовать. Это LangChain и LlamaIndex. Я обычно использую LangChain (дальше он и будет использоваться). Не могу сказать, что лучше, просто так повелось, что использую первое. Они написаны на питоне, но с помощью библиотеки reticulate всё работает и на R.
В первой части говорили про использование поиска и генерации ответа с помощью языковых моделей. В этой части рассмотрим память и агентов.


На Хабре регулярно публикуются зарплатные исследования сервисов для поиска работы. Данные одних основываются на зарплатах, которую предлагают работодатели в вакансиях. Другие же анализируют зарплаты, которые указали в анкетах сами IT-специалисты. Эти исследования учитывают зарплаты только внутри России, но с февраля 2022 года сотни тысяч айтишников России (и не только) уехали в другие страны. Многие из них нашли работу в новых странах, но кто-то продолжил работать на компанию из родной страны. Кроме того, эти исследования не учитывают важные, на наш взгляд, факторы: работает специалист удалённо или в офисе, оформлен ли трудовой договор или договор оказания услуг, и как от всего этого зависит зарплата. Так в коллективе профсоюза родилась идея провести собственное исследование состояния рынка труда и зарплат в IT.


Современный мир насыщен данными, анализ информации становится критически важным инструментом для принятия обоснованных решений. Однако просто иметь данные не достаточно – необходимо извлечь из них ценную информацию. В этом процессе статистические тесты и проверка гипотез играют важнейшую роль. Они позволяют нам сделать выводы на основе данных, опираясь на строгие методы анализа, и тем самым способствуют принятию обоснованных решений.
Статистические тесты – это мощный инструмент, который позволяет провести объективную оценку данных и проверить гипотезы, основанные на этой информации. Они позволяют определить, насколько вероятно, что наблюдаемые различия или закономерности случайны, а не реально существующие в популяции. Статистические тесты позволяют избежать ошибок и предоставляют научно обоснованный подход к анализу данных.

Периодически возникают задачи в R, которые просты по своей сути, но не очевидны для тех, кто только начинает свой путь.
Представим, что в нашей организации каждый последний понедельник месяца происходит учет товара. В эти дни нет продаж. И мы бы хотели учесть это в наших прогнозах. Стоит вопрос: как в данных "выловить" эти понедельники, не используя function.

В Python списковые включения (и генераторы списков) — замечательные механизмы, способные серьёзно упрощать программный код. Правда, чаще всего их используют в форме, предусматривающей наличие единственного цикла for и, возможно, одного условия if. И это всё. Но если попытаться немного вникнуть в эту тему, то окажется, что у списковых включений Python имеется гораздо больше возможностей, чем можно подумать, возможностей, разобравшись с которыми, можно, по меньшей мере, кое-чему научиться.