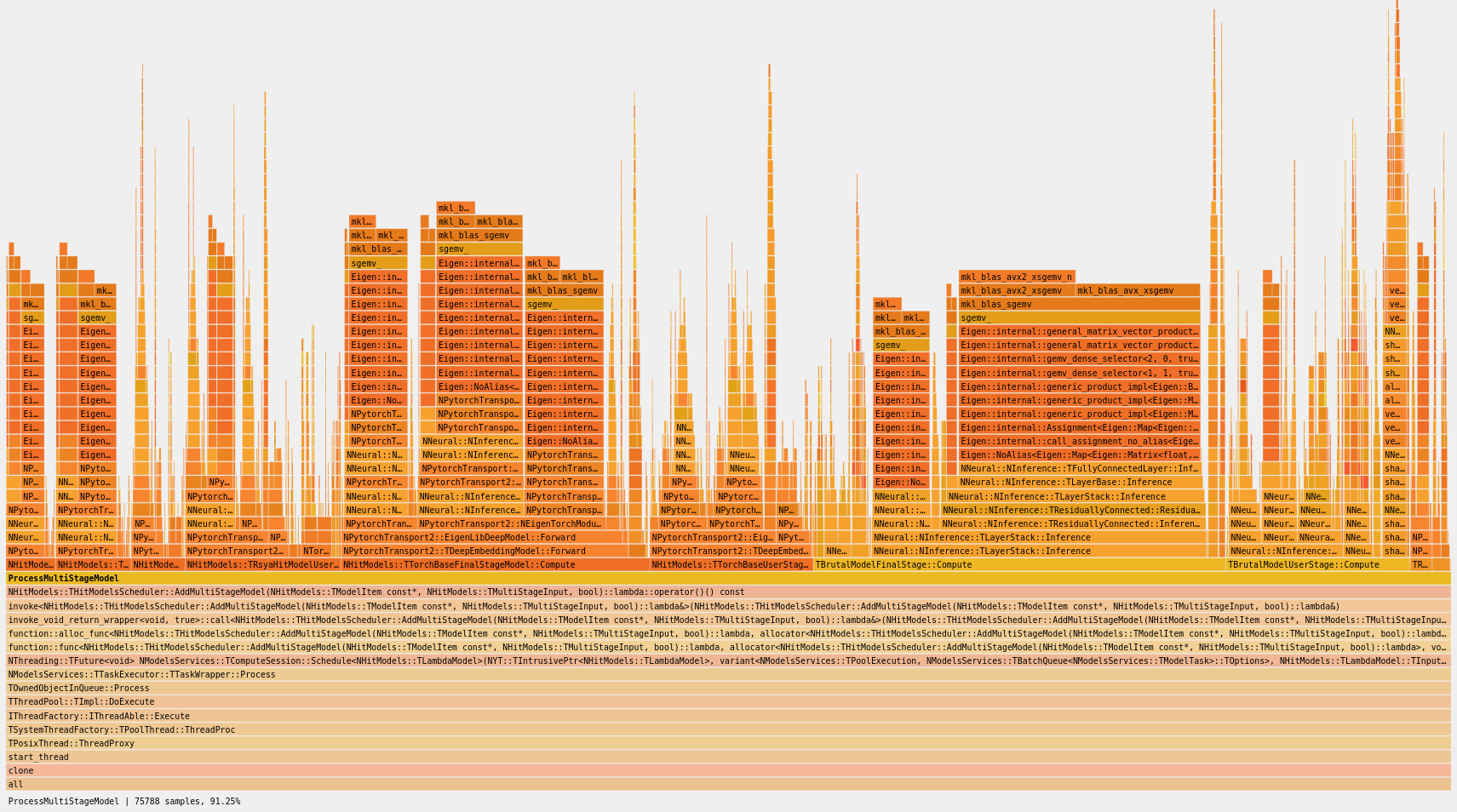
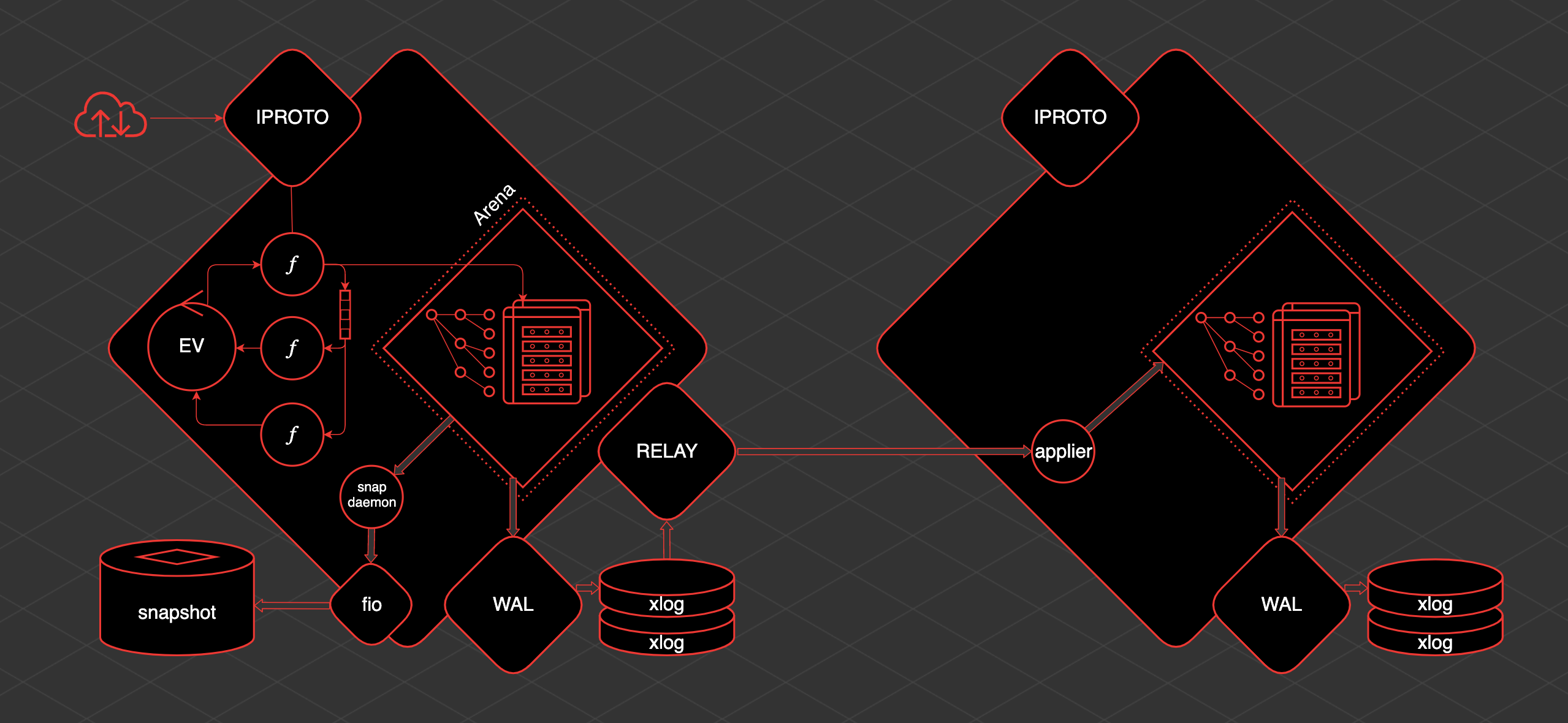
В настоящее время планировщик работы с ядрами ЦП, действующий в ядре Linux, предусматривает несколько режимов вытеснения. В этих режимах предлагается целый ряд компромиссов между временем отклика и пропускной способностью системы. Ещё в сентябре 2023 года развернулась дискуссия о работе планировщиков, в результате которой была выработана концепция «ленивого вытеснения». Данная концепция упрощает планирование задач в ядре, при этом улучшая результаты. Какое-то время эта работа протекала тихо, но затем ленивое вытеснение было заново реализовано Питером Зайлстрой в виде этой серии патчей. Притом, что сама концепция с виду работает хорошо, здесь ещё немало требуется доделывать.