В тоннелях Boring Company, построенных, чтобы не было пробок, теперь пробки. Cybertruck не поедет до 2023 года Но все это мелкие проблемы по сравнению с тем, чем обещает стать Starlink. Это главный проект Илона Маска, который должен спонсировать SpaceX, и собрать достаточно денег, чтобы обеспечить полет на Марс. Но он может стать и самой большой ошибкой.
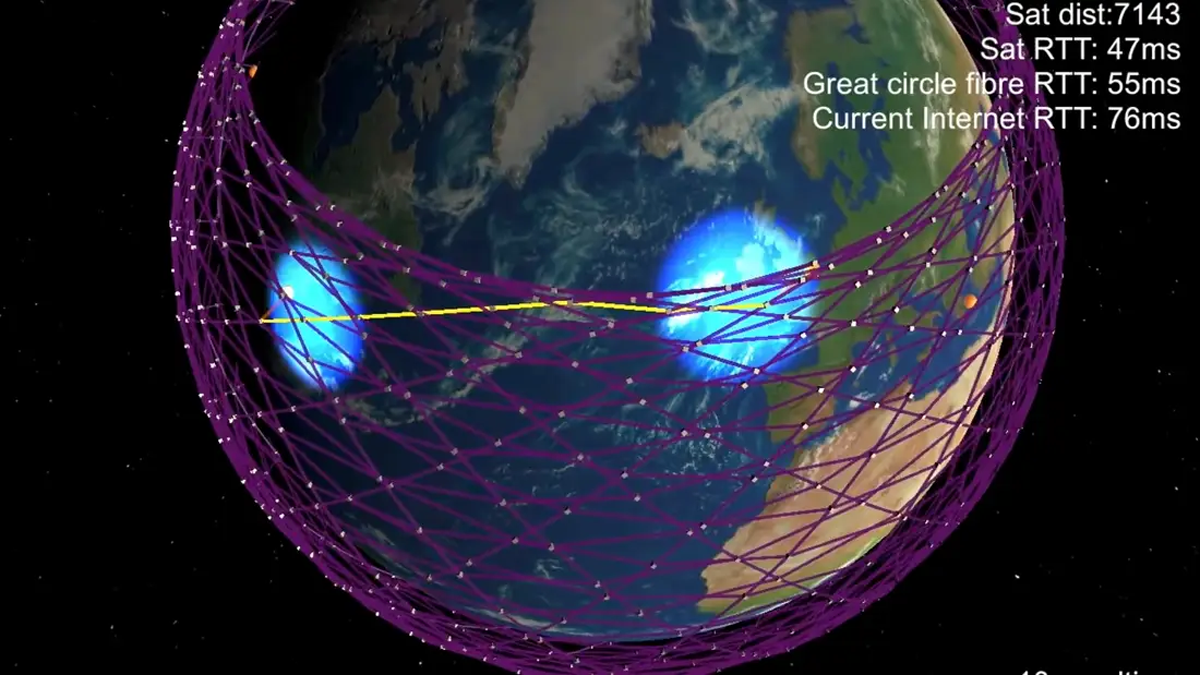
1500 спутников уже запущены и работают, 145 000 пользователей в США и Канаде уже довольны своим интернетом. Тем не менее верить в успех этого проекта, скорее всего, преждевременно. И даже более того: возможно, нам будет лучше, чтобы это будущее никогда не наступило.
Осторожно, в тексте много цифр. И, если вы продолжаете верить в Starlink, он может вас сильно разочаровать.