Nginx, однозначно, один из крутейших веб-серверов. Однако, будучи в меру простым, довольно расширяемым и производительным, он требует уважительного отношения к себе. Впрочем, это относится к почти любому ПО, от которого зависит безопасность и работоспособность сервиса. Признаюсь, нам нравится Nginx. В Яндексе он представлен огромным количеством инсталляций с разнообразной конфигурацией: от простых reverse proxy до полноценных приложений. Благодаря такому разнообразию у нас накопился некий опыт его [не]безопасного конфигурирования, которым мы хотим поделиться.
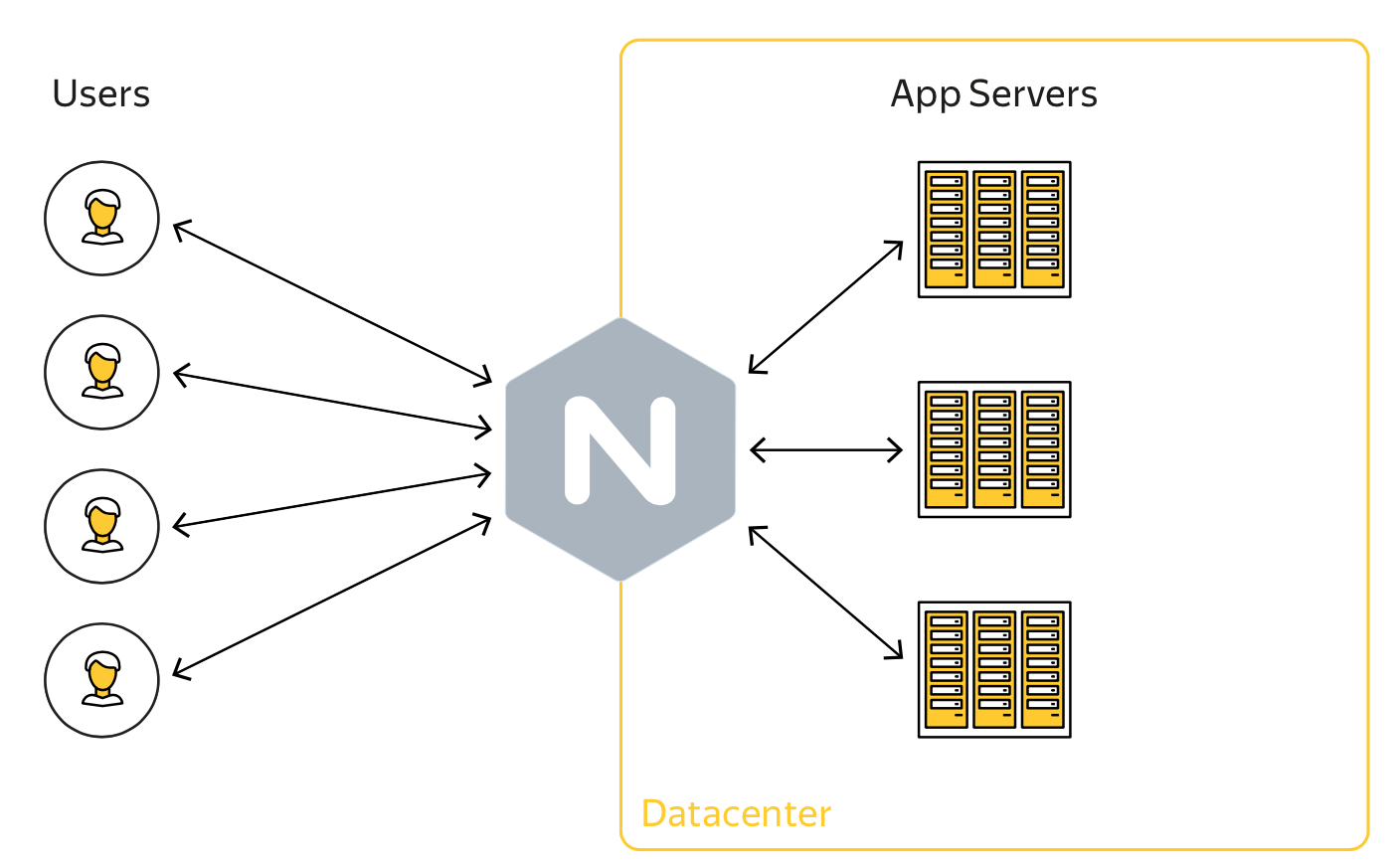
Но обо всем по порядку. Нас давно терзал вопрос безопасного конфигурирования Nginx, ведь он — полноправный кубик веб-приложения, а значит, и его конфигурация требует не меньшего контроля с нашей стороны, чем код самого приложения. В прошлом году нам стало очевидно, что этот процесс требует серьезной автоматизации. Так начался in-house проект Gixy, требования к которому мы обозначили следующим образом:
— быть простым;
— но расширяемым;
— с возможностью удобного встраивания в процессы тестирования;
— неплохо бы уметь резолвить инклюды;
— и работать с переменными;
— и про регулярные выражения не забыть.
Но обо всем по порядку. Нас давно терзал вопрос безопасного конфигурирования Nginx, ведь он — полноправный кубик веб-приложения, а значит, и его конфигурация требует не меньшего контроля с нашей стороны, чем код самого приложения. В прошлом году нам стало очевидно, что этот процесс требует серьезной автоматизации. Так начался in-house проект Gixy, требования к которому мы обозначили следующим образом:
— быть простым;
— но расширяемым;
— с возможностью удобного встраивания в процессы тестирования;
— неплохо бы уметь резолвить инклюды;
— и работать с переменными;
— и про регулярные выражения не забыть.





 В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы
В начале ноября в американском городе Иссакуа завершилась встреча международной рабочей группы