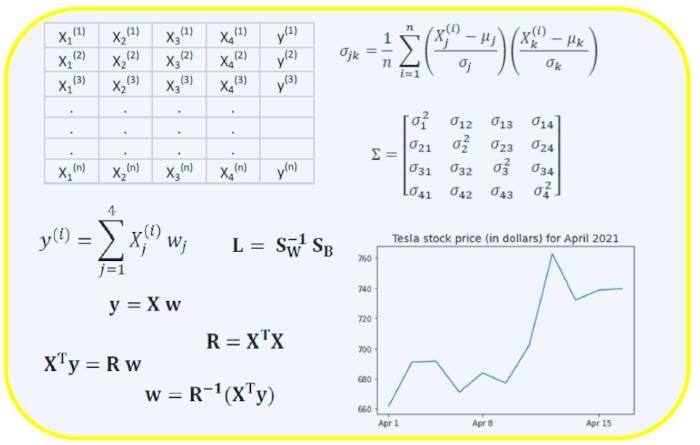
В новых версиях Python аннотации типов получают всё большую поддержку, всё чаще и чаще используются в библиотеках, фреймворках, и проектах на Python. Помимо дополнительной документированности кода, аннотации типов позволяют таким инструментам, как mypy, статически произвести дополнительные проверки корректности программы и выявить возможные ошибки в коде. В этой статье пойдет речь об одной, как мне кажется, интересной теме, касающейся статической проверки типов в Python – протоколах, или как сказано в PEP-544, статической утиной типизации.