Вычисление значения многочлена в точке является одной из простейших классических задач программирования.
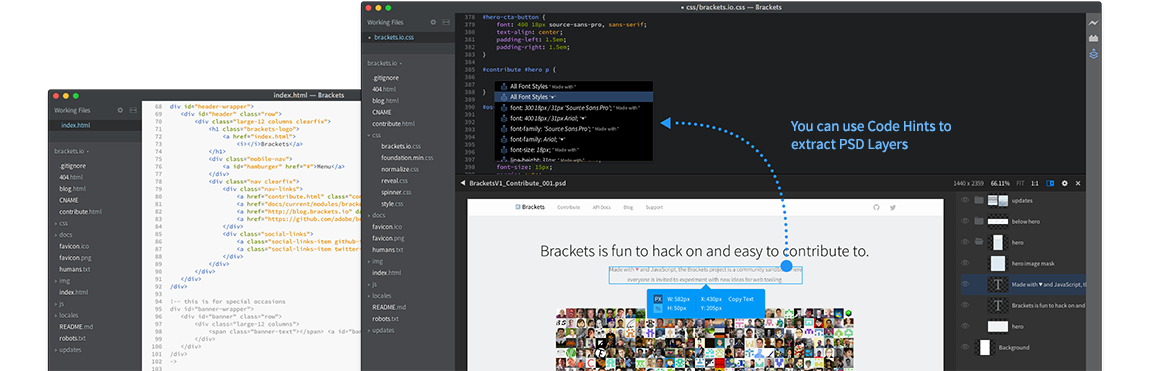
При проведении различного рода вычислений часто приходится определять значения многочленов при заданных значениях аргументов. Часто приближенное вычисление функций сводится к вычислению аппроксимирующих многочленов.
Рядового читателя Хабрахабр нельзя назвать неискушенным в применении всяческих извращений. Каждый второй скажет, что многочлен надо вычислять по правилу Горнера. Но всегда есть маленькое «но», всегда ли схема Горнера является самой эффективной?

При проведении различного рода вычислений часто приходится определять значения многочленов при заданных значениях аргументов. Часто приближенное вычисление функций сводится к вычислению аппроксимирующих многочленов.
Рядового читателя Хабрахабр нельзя назвать неискушенным в применении всяческих извращений. Каждый второй скажет, что многочлен надо вычислять по правилу Горнера. Но всегда есть маленькое «но», всегда ли схема Горнера является самой эффективной?




 «Программирование без эго» — перевод понятия
«Программирование без эго» — перевод понятия