
Эта работа является заключением пятилетнего марафона по поиску самого быстрого способа нахождения минимального точного решения для задачи коммивояжёра в общем виде.
Тут я хочу подытожить все опробованные подходы и выбрать лучший по моему мнению.

Java Developer, Open Source Contributor
Эта работа является заключением пятилетнего марафона по поиску самого быстрого способа нахождения минимального точного решения для задачи коммивояжёра в общем виде.
Тут я хочу подытожить все опробованные подходы и выбрать лучший по моему мнению.


Всех категорический приветствую. Буквально первого августа, прямо в ночь, стал у меня жутко лагать YouTube. Естественно, мне это сильно не понравилось. Ну, что же, давайте разбираться, почему и как это исправить в условиях моей личной сети.
Что случилось?
Хорошо описано произошедшее здесь, на Хабре. Если совсем кратко, своими словами - во время установки SSL соединения в открытом виде домен передается к которому мы подключаемся(так называемое SNI). И если это googlevideo.com то начинают твориться "интересные вещи". Можно проверить это локально коммандами из статьи.
$ curl https://speedtest.selectel.ru/100MB -o/dev/null

При сборке квадрокоптеров и других БПЛА обычно используют готовую плату полетного контроллера, содержащую все необходимые датчики и периферию, и готовую полетную прошивку, например, Betaflight, ArduPilot или PX4. Полетный контроллер управляет моторами квадрокоптера и обеспечивает стабильный полет.
Занимаясь БПЛА с 2016 года, я решил разобраться в устройстве полетных контроллеров максимально глубоко и создать квадрокоптер с нуля, не используя готовый полетный контроллер и готовый софт. Спустя долгое время разработки мне удалось это сделать. Я написал прошивку с максимально простым исходным кодом и выложил ее на GitHub. В этой статье я расскажу о теории и практике разработки полетного софта для квадрокоптера и проиллюстрирую это на примере своего дрона на базе микроконтроллера ESP32, который можно увидеть на картинке выше.
Работаете с распределенными системами или только пытаетесь к ним подобраться? Проектировать такие системы с нуля бывает сложно и страшно: чтобы учесть все нюансы, нужен определенный багаж знаний.
На помощь приходит Reactive Manifesto — документ, который обобщил опыт целого ряда компаний по созданию распределенных систем. Манифест формулирует главные принципы, на которые стоит опираться на этапе проектирования и эксплуатации таких систем.
Меня зовут Андрей Василевский, я системный архитектор в Lamoda Tech. В этой статье я на примерах из своей работы покажу, как применять Reactive Manifesto на практике. Статья будет полезна тем, кто только начал изучать распределенные системы, хочет закрепить теорию или тем, кто хочет структурировать проектирование микросервисов в своей компании.

С момента выхода первой статьи «Attention is All You Need» я с жадностью и любопытством, присущими любому исследователю, пытаюсь углубиться во все особенности и свойства моделей на базе архитектуры трансформер. Но, если честно, я до сих пор не понимаю, как они работают и почему так хорошо обучаются. Очень хочу разобраться, в чём же причина такой эффективности этих моделей, и есть ли предел их возможностей?
Такому изучению трансформеров «под микроскопом» и посвящена наша научная работа, только что представленная на конференции EACL 2024, которая проходила на Мальте — «The Shape of Learning: Anisotropy and Intrinsic Dimensions in Transformer-Based Models». В этой работе мы сфокусировались на наблюдении за пространством эмбеддингов (активаций) на промежуточных слоях по мере обучения больших и маленьких языковых моделей (LM).

Общеизвестно, что PostgreSQL - крайне эффективная СУБД с богатой функциональностью. При этом не секрет, что PostgreSQL масштабируется только вертикально и её производительность ограничена возможностями одного сервера.
Написано много хороших постов, в которых сравнивают архитектуру монолитных и распределенных СУБД. К сожалению, обычно авторы ограничиваются теоретическим сравнением и не приводят конкретные цифры. Данный пост же наоборот основан на эмпирическом исследовании с использованием бенчмарка TPC-C, который является промышленным стандартом для оценки производительности транзакционных СУБД (On-Line Transaction Processing, OLTP).
Мы расскажем, когда именно одного Postgres'a становится мало, и какие возможны компромиссы между производительностью и надежностью. Для тех, кто не готов к компромиссам, мы покажем, что могут предложить такие распределенные СУБД, как CockroachDB и YDB.

Специальная теория относительности - удивительная теория, которая опровергла многие представления о мире, в которых человечество не сомневалось всю историю своего существования.
Многие слышали про волшебства вроде замедления времени, сокращения длины, относительности одновременности, парадокса близнецов и т.д., но мало кто понимает почему так происходит.
В этой статье я хочу наглядно показать, что все это проще, чем кажется на первый взгляд.
Для иллюстраций я написал интерактивный визуализатор СТО, работающий в браузере. Ссылка на него и исходники проекта в конце статьи.


В статье я поделюсь, как интегрировать ChatGPT для ревью пулл-реквестов на GitHub без покупок иностранных номеров, карт и различных ВПНов, используя, GitHub Actions

В этом посте мы расскажем о примере дедлока в TPC-C для PostgreSQL, причиной которого является исключительно переход на виртуальные потоки Java 21 - и никаких проблем обедающих философов.

Привет, Хабр! Я разработчик в Институте Системного Программирования РАН, занимаюсь разработкой статического анализатора Svace. Недавно я столкнулся с задачей самостоятельной загрузки классов в JVM, что оказалось непросто, потому что в проекте мы используем модули Java.
Модули появились в Java, начиная с версии 9. Прошло уже несколько лет, но если попытаться найти актуальную информацию о связи модулей и загрузчиков классов, её придётся собирать по крупицам. В статье я поделюсь своим опытом изучения вопроса самостоятельной (и автоматической) загрузки классов с помощью кастомного загрузчика, а также разберу примеры, описывающие большинство случаев загрузки, постараюсь их объяснить.
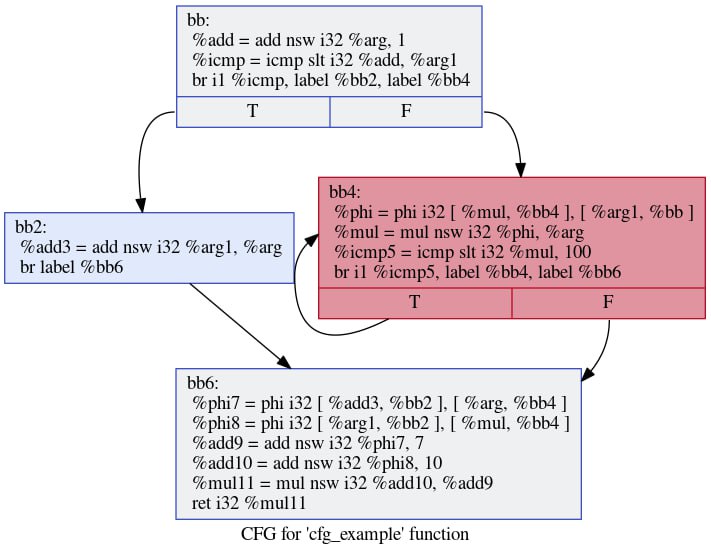
Всем привет. Сегодня я хотел бы поговорить об устройстве современных оптимизирующих компиляторов. Я никогда не публиковался на Хабре ранее, но надеюсь, что мне удастся написать серию статей, которая просуммирует мой опыт в этой области.
Коротко обо мне. Меня зовут Макс, и так получилось, что я вот уже 10 лет, почти с самого начала своей карьеры, занимаюсь оптимизирующими компиляторами. Я начинал в Intel, потом перешёл в Azul Systems, год провёл в Cadence и вернулся обратно, всё это время занимаясь компиляторными оптимизациями для Java, C++ и нейросетевых моделей. На момент написания статьи у меня чуть за 900 патчей в LLVM, большинство из них посвящено цикловым оптимизациям.
За это время я провёл десятки собеседований на позиции как интернов, так и инженеров сеньорного уровня, и довольно часто люди, приходя на эти собеседования, многих вещей не знают или знают поверхностно. И я подумал: а мог бы я написать такой цикл статей, чтобы человек, прочитав их, узнал бы всю ту базу, которая, на мой собственный взгляд, необходимо начинающему компиляторному инженеру? Очень бы хотелось, чтобы новичку в этой области можно бы было дать один (относительно небольшой по объёму) набор текстов, чтобы он получил оттуда всё необходимое для старта. Это не перевод, текст оригинальный, поэтому в нём могут быть ошибки и неточности, которые я буду рад исправить, если вы мне их укажете.
Итак, поехали.

Статей о работе с PostgreSQL и её преимуществах достаточно много, но не всегда из них понятно, как следить за состоянием базы и метриками, влияющими на её оптимальную работу. В статье подробно рассмотрим SQL-запросы, которые помогут вам отслеживать эти показатели и просто могут быть полезны как пользователю.

В этой статье я расскажу вам о том, как мы в Ozon оптимизируем базовый поиск: как у нас выстроены процессы, как найти бутылочное горлышко, конкретные рекомендации по написанию горячего кода, реальные примеры значимых оптимизаций и что делать, когда все низко висящие фрукты уже сорваны, а хочется ещё.

Привет, Хабровчане!
JVM работает как хорошо отлаженный механизм, автоматически распределяя и освобождая память. Это и есть суть Garbage Collection. Это процесс, который автоматически находит и удаляет объекты, которые больше не используются вашим приложением. Благодаря этому, разработчики могут сосредоточиться на логике приложения, не беспокоясь о ручном управлении памятью.
Знание того, как работает GC и JVM, необходимо каждому Java-разработчику. Правильное управление ресурсами напрямую влияет на производительность и стабильность приложений.

Периодически сталкиваюсь с однотипными задачами вида "показать TOP-N позиций на каждом из вложенных интервалов некоторого периода".
Это может быть "5 лучших по успеваемости студентов в каждом семестре за последний учебный год", или "помесячная динамика позиции 10 наиболее продающихся товаров", или, как у нас в сервисе визуализации PostgreSQL-планов explain.tensor.ru, "3 наиболее активных страны за каждый день":