В статье рассматривается факторное моделирование с помощью метода факторизации на базе нейронной сети и алгоритма обратного распространения ошибки. Этот метод факторизации является альтернативой классическому факторному анализу. Данный метод был усовершенствован для проведения факторного вращения и получения интерпретируемого решения. Факторная структура, полученная с помощью данного метода факторизации, находятся в соответствии с результатами факторного моделирования посредством других методов.

Сергей Кокорин @kokorins
Пользователь
Обзор топологий глубоких сверточных нейронных сетей
18 мин
 Это будет длиннопост. Я давно хотел написать этот обзор, но sim0nsays меня опередил, и я решил выждать момент, например как появятся результаты ImageNet’а. Вот момент настал, но имаджнет не преподнес никаких сюрпризов, кроме того, что на первом месте по классификации находятся китайские эфэсбэшники. Их модель в лучших традициях кэгла является ансамблем нескольких моделей (Inception, ResNet, Inception ResNet) и обгоняет победителей прошлого всего на полпроцента (кстати, публикации еще нет, и есть мизерный шанс, что там реально что-то новое). Кстати, как видите из результатов имаджнета, что-то пошло не так с добавлением слоев, о чем свидетельствует рост в ширину архитектуры итоговой модели. Может, из нейросетей уже выжали все что можно? Или NVidia слишком задрала цены на GPU и тем самым тормозит развитие ИИ? Зима близко? В общем, на эти вопросы я тут не отвечу. Зато под катом вас ждет много картинок, слоев и танцев с бубном. Подразумевается, что вы уже знакомы с алгоритмом обратного распространения ошибки и понимаете, как работают основные строительные блоки сверточных нейронных сетей: свертки и пулинг.
Это будет длиннопост. Я давно хотел написать этот обзор, но sim0nsays меня опередил, и я решил выждать момент, например как появятся результаты ImageNet’а. Вот момент настал, но имаджнет не преподнес никаких сюрпризов, кроме того, что на первом месте по классификации находятся китайские эфэсбэшники. Их модель в лучших традициях кэгла является ансамблем нескольких моделей (Inception, ResNet, Inception ResNet) и обгоняет победителей прошлого всего на полпроцента (кстати, публикации еще нет, и есть мизерный шанс, что там реально что-то новое). Кстати, как видите из результатов имаджнета, что-то пошло не так с добавлением слоев, о чем свидетельствует рост в ширину архитектуры итоговой модели. Может, из нейросетей уже выжали все что можно? Или NVidia слишком задрала цены на GPU и тем самым тормозит развитие ИИ? Зима близко? В общем, на эти вопросы я тут не отвечу. Зато под катом вас ждет много картинок, слоев и танцев с бубном. Подразумевается, что вы уже знакомы с алгоритмом обратного распространения ошибки и понимаете, как работают основные строительные блоки сверточных нейронных сетей: свертки и пулинг.Алгоритм НСКО (алгоритм Хо-Кашьяпа)
1 мин
Зачастую, во время работы с нейронными сетями, перед нами встает задача в построении линейных решающих функций (ЛРФ) для разделения классов, содержащих наши образы.
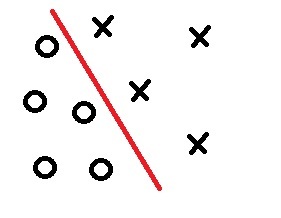
Рисунок 1. двумерный случай
Один из методов, позволяющих решить нашу проблему, это алгоритм наименьшей среднеквадратичной ошибки (НСКО алгоритм).
Интерес данный алгоритм представляет не только в том, что он помогает построить необходимые нам ЛРФ, а в том, что при возникновении ситуации, когда классы линейно неразделимы, мы можем построить ЛРФ, где ошибка неправильной классификации стремится к минимуму.
Рисунок 1. двумерный случай
Один из методов, позволяющих решить нашу проблему, это алгоритм наименьшей среднеквадратичной ошибки (НСКО алгоритм).
Интерес данный алгоритм представляет не только в том, что он помогает построить необходимые нам ЛРФ, а в том, что при возникновении ситуации, когда классы линейно неразделимы, мы можем построить ЛРФ, где ошибка неправильной классификации стремится к минимуму.
Dependency Injection с проверкой корректности на Scala средствами языка
5 мин
Хочу рассказать про свою небольшую библиотеку Dependency Injection на Scala. Проблема которую хотелось решить: возможность протестировать граф зависимостей до их реального конструирования и падать как можно раньше если что-то пошло не так, а также видеть в чем именно ошибка. Это именно то, чего не хватает в замечательной DI-библиотеке Scaldi. При этом хотелось сохранить внешнюю прозрачность синтаксиса и максимально обойтись средствами языка, а не усложнять и влезать в макросы.
Также хочу сразу обратить внимание что я концентрируюсь на DI через конструктор, как на самом простом и идиоматичном способе, не требующем изменений в реализацию классов.
Алгоритм визуализации сложных данных
9 мин
Туториал
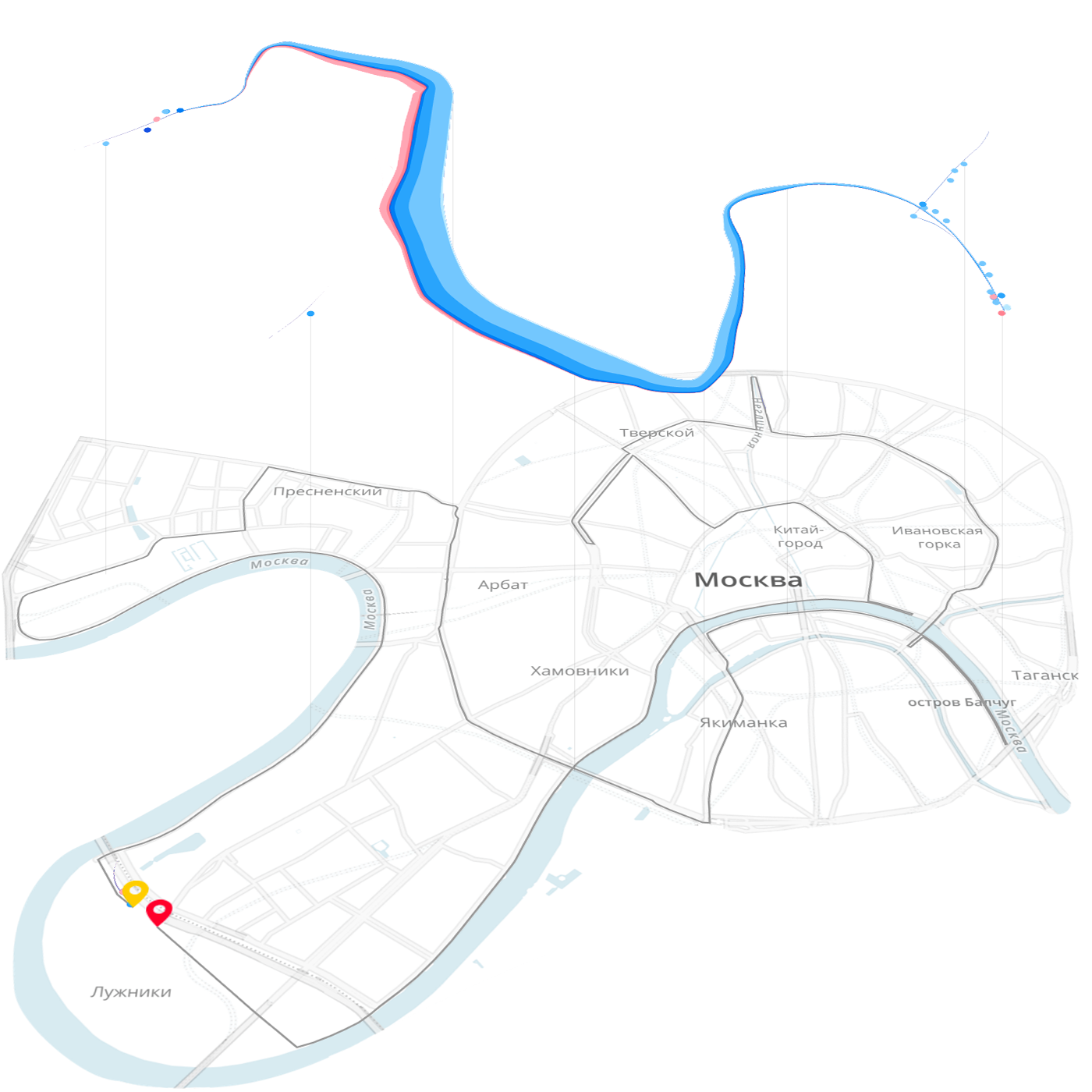
За три года существования Лаборатория данных выпустила около тридцати интерактивных визуализаций, в формате заказных, собственных проектов и бесплатных советов. Мы в лаборатории визуализируем финансовые и научные данные, данные городской транспортной сети, результаты забегов, эффективность маркетинговых кампаний и многое другое. Весной мы получили бронзовую медаль на престижной премии Malofiej 24 за визуализацию результатов Московского марафона.
Последние полгода я работаю над алгоритмом визуализации данных, который систематизирует этот опыт. Моя цель — дать рецепт, который позволит разложить любые данные по полочкам и решать задачи по визуализации данных также чётко и последовательно, как математические задачи. В математике не важно, складывать яблоки или рубли, распределять кроликов по ящикам или бюджеты на рекламные кампании — есть стандартные операции сложения, вычитания, деления и т.д. Я хочу создать универсальный алгоритм, который поможет визуализировать любые данные, при этом учитывает их смысл и уникальность.
Я хочу поделиться с читателями Хабра результатами своих исследований.
Последние полгода я работаю над алгоритмом визуализации данных, который систематизирует этот опыт. Моя цель — дать рецепт, который позволит разложить любые данные по полочкам и решать задачи по визуализации данных также чётко и последовательно, как математические задачи. В математике не важно, складывать яблоки или рубли, распределять кроликов по ящикам или бюджеты на рекламные кампании — есть стандартные операции сложения, вычитания, деления и т.д. Я хочу создать универсальный алгоритм, который поможет визуализировать любые данные, при этом учитывает их смысл и уникальность.
Я хочу поделиться с читателями Хабра результатами своих исследований.
Что такое свёрточная нейронная сеть
13 мин
Перевод

Введение
Свёрточные нейронные сети (СНС). Звучит как странное сочетание биологии и математики с примесью информатики, но как бы оно не звучало, эти сети — одни из самых влиятельных инноваций в области компьютерного зрения. Впервые нейронные сети привлекли всеобщее внимание в 2012 году, когда Алекс Крижевски благодаря им выиграл конкурс ImageNet (грубо говоря, это ежегодная олимпиада по машинному зрению), снизив рекорд ошибок классификации с 26% до 15%, что тогда стало прорывом. Сегодня глубинное обучения лежит в основе услуг многих компаний: Facebook использует нейронные сети для алгоритмов автоматического проставления тегов, Google — для поиска среди фотографий пользователя, Amazon — для генерации рекомендаций товаров, Pinterest — для персонализации домашней страницы пользователя, а Instagram — для поисковой инфраструктуры.
Но классический, и, возможно, самый популярный вариант использования сетей это обработка изображений. Давайте посмотрим, как СНС используются для классификации изображений.
Задача
Задача классификации изображений — это приём начального изображения и вывод его класса (кошка, собака и т.д.) или группы вероятных классов, которая лучше всего характеризует изображение. Для людей это один из первых навыков, который они начинают осваивать с рождения.

Джентельменский набор пакетов R для автоматизации бизнес-задач
3 мин
Продолжение предыдущих публикаций «Инструменты DataScience как альтернатива классической интеграции ИТ систем» и
«Экосистема R как инструмент для автоматизации бизнес-задач».
Настоящая статья является ответом на возникшие вопросы по пакетам R, которые полезны для реализации описанных подходов. Я ее рассматриваю исключительно как справочную информацию, и отправную точку для последующего детального изучения заинтересовавшимися, поскольку за каждым пакетом скрывается огромное пространство со своей философией и идеологией, математикой и путями развития.
Как правило, все пакеты (9109 штук на 07.09.2016) находятся в репозитории CRAN. Те, что по тем или иным причинам, пока не опубликованы в репозиторий, могут быть найдены на GitHub. Итак, кратким списком:
Диаграмма Вороного и её применения
25 мин
Доброго всем времени суток, уважаемые посетители сайта Хабрахабр. В данной статье я бы хотел рассказать вам о том, что такое диаграмма Вороного (изображена на картинке ниже), о различных алгоритмах её построения (за ") ,
, )") — пересечение полуплоскостей,
— пересечение полуплоскостей, )") — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).
— алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).

Также будет рассмотрено много интересных применений диаграммы и несколько любопытных фактов о ней. Будет интересно!
, — пересечение полуплоскостей, — алгоритм Форчуна) и некоторых тонкостях реализации (на языке C++).Также будет рассмотрено много интересных применений диаграммы и несколько любопытных фактов о ней. Будет интересно!
Правила внедрения TDD в старом проекте
12 мин
Статья «Скользящая ответственность паттерна Репозиторий» подняла несколько вопросов, на которые очень сложно дать ответ. Нужен ли репозиторий, если абстрагироваться от технических деталей полностью невозможно? На сколько сложным репозиторий может быть, чтобы его написание оставалось целесообразным? Ответ на эти вопросы различается в зависимости от акцента, который делается при разработке систем. Наверно, самый сложный вопрос: нужен ли, вообще, репозиторий? Проблема «текучей абстракции» и рост сложности кодирования с увеличением уровня абстракции не позволяют найти решение, которое удовлетворяло бы оба лагеря. Например, в репортинге intention design приводит к созданию большого числа методов для каждого фильтра и сортировки, а generic решение создает большой оверхед по кодированию. Продолжать можно бесконечно…
Для более полного представления я взглянул на проблему абстракций со стороны применения их в уже готовом коде, в legacy code. Репозиторий, в таком случае, нас интересует только, как инструмент для достижения качественного и безбажного кода. Конечно, этот паттерн — не единственное, что необходимо для применения TDD практик. Наевшись «невкусной еды» в нескольких больших проектах и наблюдая за тем, что работает, а что нет, я вывел для себя несколько правил, которые мне помогают следовать TDD практикам. С удовольствием выслушаю конструтктивную критику и иные приёмы внедрения TDD.
Для более полного представления я взглянул на проблему абстракций со стороны применения их в уже готовом коде, в legacy code. Репозиторий, в таком случае, нас интересует только, как инструмент для достижения качественного и безбажного кода. Конечно, этот паттерн — не единственное, что необходимо для применения TDD практик. Наевшись «невкусной еды» в нескольких больших проектах и наблюдая за тем, что работает, а что нет, я вывел для себя несколько правил, которые мне помогают следовать TDD практикам. С удовольствием выслушаю конструтктивную критику и иные приёмы внедрения TDD.
В тени случайного леса
7 мин
1. Вступление
Это небольшой рассказ о практических вопросах использования машинного обучения для масштабных статистических исследований различных данных в Интернет. Также будет затронута тема применения базовых методов математической статистики для анализа данных.
Математика на пальцах: давайте посчитаем хотя бы один ряд Фурье в уме
6 мин
Туториал
Нужно ли вам читать этот текст?
Давайте проверим. Прочтите следующее:
Тригонометрическим рядом Фурье функции называют функциональный ряд вида
где




Страшно, но всё же хочется понять, что это значит?
Значит, вам под кат. Постараюсь формул не использовать.
Подборка подкастов по программированию на русском и английском языках
7 мин
Всем привет! В этой статье собраны одни из лучших подкастов по программированию как на русском так и на английском языках, которые позволят вам быть всегда в курсе последних новостей.
Подкасты представляют собой звуковые файлы, которые можно слушать в любое время на вашем компьютере или другом устройстве (IPod, IPad, смартфон и т.д.). Это самый портативный способ потреблять контент и узнавать что-то новое. Популярность подкастов росла на протяжении многих лет и теперь они охватывают очень широкий круг вопросов.
И да, есть много интересных и популярных подкастов для разработчиков и программистов. Подкасты невероятно полезны, они будут держать вас в курсе всего что происходит в интересующей вас сфере, а также помогут вам развить более широкий взгляд на постоянно развивающуюся область информационных технологий.
Подкасты представляют собой звуковые файлы, которые можно слушать в любое время на вашем компьютере или другом устройстве (IPod, IPad, смартфон и т.д.). Это самый портативный способ потреблять контент и узнавать что-то новое. Популярность подкастов росла на протяжении многих лет и теперь они охватывают очень широкий круг вопросов.
И да, есть много интересных и популярных подкастов для разработчиков и программистов. Подкасты невероятно полезны, они будут держать вас в курсе всего что происходит в интересующей вас сфере, а также помогут вам развить более широкий взгляд на постоянно развивающуюся область информационных технологий.
Распределение ресурсов в больших кластерах высокой производительности. Лекция в Яндексе
30 мин
Большинство сложных задач с данными требуют немалого количества ресурсов. Поэтому почти у каждого дата-центра в мире не один, а множество клиентов — даже если все они выступают под общим брендом. Компаниям нужны мощности под самые разные сервисы и цели, да и в процессе достижения какой-нибудь одной из них приходится иметь дело с целым набором подзадач. Как дата-центру справиться с потоком желающих что-нибудь проанализировать или посчитать? Поступающие заказы на вычисления нужно выполнять в некотором порядке, стараясь никого не обделить ресурсами. Эта лекция — об основных методах распределения реальных задач на большом кластере. Способ, о котором рассказал Игнат Колесниченко, применяется для обслуживания почти всех сервисов Яндекса.
Игнат — руководитель одной из групп в нашей службе технологий распределенных вычислений. Окончил мехмат МГУ и Школу анализа данных, в Яндексе с 2009 года.
Под катом — подробная расшифровка лекции и слайды.
Игнат — руководитель одной из групп в нашей службе технологий распределенных вычислений. Окончил мехмат МГУ и Школу анализа данных, в Яндексе с 2009 года.
Под катом — подробная расшифровка лекции и слайды.
Классические паттерны проектирования на Scala
14 мин
Перевод
Об авторе:
Pavel Fatin работает над Scala plugin'ом для IntelliJ IDEA в JetBrains.
В этой статье будут представлены примеры того, как реализуются классические паттерны проектирования на Scala.
Содержание статьи составляет основу моего выступления на JavaDay конференции (слайды презентации).
Pavel Fatin работает над Scala plugin'ом для IntelliJ IDEA в JetBrains.
Введение
В этой статье будут представлены примеры того, как реализуются классические паттерны проектирования на Scala.
Содержание статьи составляет основу моего выступления на JavaDay конференции (слайды презентации).
Введение в понятие энтропии и ее многоликость
5 мин
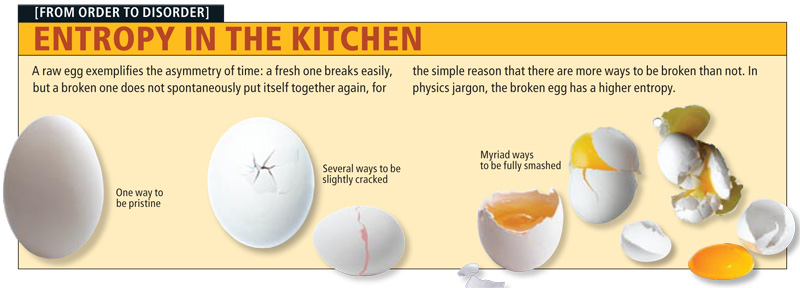
Как может показаться, анализ сигналов и данных — тема достаточно хорошо изученная и уже сотни раз проговоренная. Но есть в ней и некоторые провалы. В последние годы словом «энтропия» бросаются все кому не лень, толком и не понимая, о чем говорят. Хаос — да, беспорядок — да, в термодинамике используется — вроде тоже да, применительно к сигналам — и тут да. Хочется хотя бы немного прояснить этот момент и дать направление тем, кто захочет узнать чуть больше об энтропии. Поговорим об энтропийном анализе данных.
Spark Summit 2016: обзор и впечатления
10 мин

В июне прошло одно из самых крупных мероприятий мира в сфере big data и data science — Spark Summit 2016 в Сан-Франциско. Конференция собрала две с половиной тысячи человек, включая представителей крупнейших компаний (IBM, Intel, Apple, Netflix, Amazon, Baidu, Yahoo, Cloudera и так далее). Многие из них используют Apache Spark, включая контрибьюторов в open source и вендоров собственных разработок в big data/data science на базе Apache Spark.
Мы в Wrike активно используем Spark для задач аналитики, поэтому не могли упустить возможности из первых рук узнать, что происходит нового на этом рынке. С удовольствием делимся своими наблюдениями.
Сказ царя Салтана о потенциале лапласиана
9 мин
«Три девицы под окном пряли поздно вечерком.»

Ну как пряли. Не пряли, конечно, а лайкали другна друга. По условиям конкурса «мисс Салтан» девицы должны были выбрать меж собой лучшую.
«Какой-то странный конкурс», — беспокоились девицы. И это было правдой. По правилам конкурса вес лайка участника зависел от того, сколько лайков он получает от других. Что это значит, — никто из девиц до конца не понимал.
«Как все сложно», — тосковали девушки и подбадривали себя песней «Кабы я была царицей».
Вскоре «в светлицу вошел царь — стороны той государь» (показан на рисунке). «Во все время разговора...», — ну понятно в общем.
«Собираем лайки нежности — формируем матрицу смежности», — бодро срифмовал он.
Девицы-красавицы с именами Алена, Варвара и Софья засмущались, но лайки (из балалайки) передали.
Вот что там было:
Царь взял лайки, покрутил гайки, постучал по колесам, пошмыгал носом, причмокнул губами, поскрипел зубами, сгонял в палаты и объявил результаты.
Наибольший вес лайков (7 баллов) получила Софья, но титул «мисс Салтан» достался Алене (15 баллов).
После объявления результатов девицыбросились обратились к царю с просьбой рассказать,- откуда взялись эти странные цифры?
Ну как пряли. Не пряли, конечно, а лайкали друг
«Какой-то странный конкурс», — беспокоились девицы. И это было правдой. По правилам конкурса вес лайка участника зависел от того, сколько лайков он получает от других. Что это значит, — никто из девиц до конца не понимал.
«Как все сложно», — тосковали девушки и подбадривали себя песней «Кабы я была царицей».
Вскоре «в светлицу вошел царь — стороны той государь» (показан на рисунке). «Во все время разговора...», — ну понятно в общем.
«Собираем лайки нежности — формируем матрицу смежности», — бодро срифмовал он.
Девицы-красавицы с именами Алена, Варвара и Софья засмущались, но лайки (из балалайки) передали.
Вот что там было:
- Алена получила 1 лайк от Софьи и 2 лайка от Варвары.
- Варвара получила по лайку от Алены и Софьи.
- А Софья получила 2 лайка от Алены и 1 от Варвары.
Царь взял лайки, покрутил гайки, постучал по колесам, пошмыгал носом, причмокнул губами, поскрипел зубами, сгонял в палаты и объявил результаты.
Наибольший вес лайков (7 баллов) получила Софья, но титул «мисс Салтан» достался Алене (15 баллов).
Подробнее о матрице лайков
Для матрицы

вектор потенциалов равен (5, 4, 7), а вектор потоков — (15, 12, 14).
вектор потенциалов равен (5, 4, 7), а вектор потоков — (15, 12, 14).
После объявления результатов девицы
ScribeJava — даже ваша бабушка сможет работать с OAuth
10 мин

Именно этой фразой нас приветствует библиотека для работы с OAuth — ScribeJava (https://github.com/scribejava/scribejava). Если быть точнее, то фраза звучит так: “Who said OAuth/OAuth2 was difficult? Configuring ScribeJava is so easy your grandma can do it! check it out:”.
И это действительно похоже на правду:
OAuth20Service service = new ServiceBuilder().apiKey(clientId).apiSecret(clientSecret)
.callback("http://your.site.com/callback").grantType("authorization_code").build(HHApi.instance());
String authorizationUrl = service.getAuthorizationUrl();
OAuth2AccessToken accessToken = service.getAccessToken(code);
Готово! Этих трех строчек достаточно, чтобы начать делать OAuth запросы. А сам OAuth запрос можно будет сделать так:
OAuthRequest request = new OAuthRequest(Verb.GET, "https://api.hh.ru/me", service);
service.signRequest(accessToken, request);
String response = request.send().getBody();
Данные о пользователе у нас в руках (в переменной response). И ни капли понимания, как в деталях работает OAuth. Хотим асинхронные http-запросы? Нам хватит тех же трех строчек. Ниже рассмотрим это на примере.
Материал по работе с Apache Lucene и созданию простейшего нечёткого поиска
4 мин
Туториал
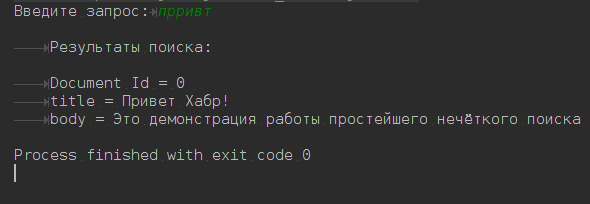 Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту.
Пост расcчитан на начинающих, на людей незнакомых с технологией Apache Lucene. В нем нет материала о том, как устроен Apache Lucene внутри, какие алгоритмы, структуры данных и методы использовались для создания фреймворка. Пост является обучающим материалом-тизером, написанным для того, чтобы показать, как организовать простейший нечёткий поиск по тексту. В качестве материала для обучения предоставлен код на github, сам пост в качестве документации и немного данных для тестирования поисковых запросов.
Список ресурсов по машинному обучению. Часть 1
3 мин
Перевод

Ранее мы говорили о разработке системы квантовой связи и о том, как из простых студентов готовят продвинутых программистов. Сегодня мы решилие еще раз (1, 2) взглянуть в сторону темы машинного обучения и привести адаптированную (источник) подборку полезных материалов, обсуждавшихся на Stack Overflow и Stack Exchange.