На небе только и разговоров, что о дизайн-системах и дизайн-токенах. Но информация представленная здесь строится исключительно на собственном опыте.
Поводом для написания такого гайда стала практика и упорядочивание всей этой информации в голове. Когда я начинал этот путь, то в русскоязычном сегменте было минимум информации и приходилось по крупицам собирать общие практики.
Сегодня я подвожу итог этой темы и суммирую добытые знания, попробовав составить ультимативный гайд по теме. Хотя бы для общего понимания процесса и наводки, в какую сторону копать для таких же жаждущих знаний.
Меня зовут Женя, я руководитель UX-направления в компании Usetech. На досуге веду телеграм-канал «Мамкин Дизайнер», где рассказываю о вот таких штуках.
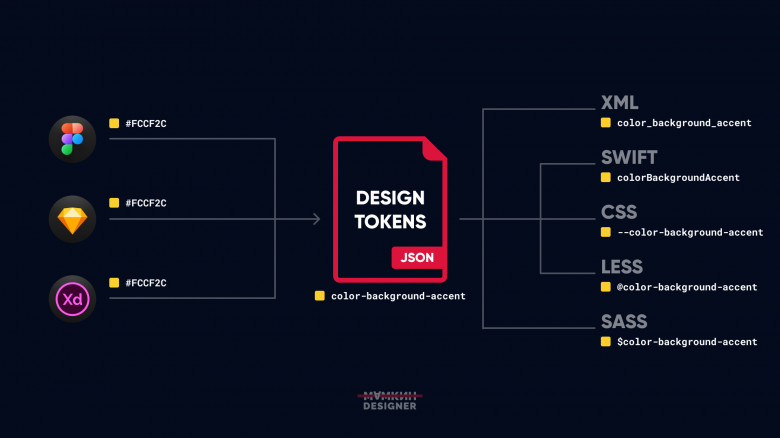
Я сам — дизайнер, но мне важно было понять, что такое дизайн-токены, как они работают, как компилируются из JSON и как помогают в работе.