Всем привет, на связи Елисеев Арсений. Сегодня расскажу, как разрабатывал модель классификатора для сервиса e-mail-рассылок Pochtaboy. Сам продукт находится еще в стадии тестирования, однако у него есть первые пользователи, на которых мы и проверим эффективность выбранной модели.

Глеб @snackTate
Пользователь
Классификация текстов в spaCy: пошаговая инструкция
Простой
5 мин

Вы узнаете, как реализовать классификатор текстов при помощи библиотеки spaCy, а также несколько полезных лайфхаков, которые помогут ускорить обработку данных.
Быстро, точно, градиентно: как наш подход к градиентному бустингу повышает эффективность моделей
11 мин
Туториал

Доброго времени суток, уважаемые читатели! Сегодня мы вновь рады приветствовать вас в увлекательном мире дата-сайентистов банка "Открытие". На связи Иван Кондраков, Константин Грушин и Станислав Арешин. Недавно мы поделились с вами нашим пайплайном разработки линейных моделей для решения задач бинарной классификации. Теперь же мы решили поведать о нашем опыте построения моделей градиентного бустинга. За последнее время команда проделала колоссальную работу: мы протестировали различные методы отбора факторов, нашли новые инсайты в данных, провели интересную (а, главное, полезную!) аналитическую работу и решили несколько Ad-hoc задач. Зовите всех к экранам, мы начинаем!
ML-пайплайн классических банковских моделей классификации
10 мин
Туториал

Всем привет! С вами на связи дата-сайентисты банка "Открытие" Иван Кондраков и Константин Грушин. В прошлой статье мы рассказывали про решение, которое позволило повысить эффективность в проверке гипотез для моделей. Если вы успели с ней ознакомиться, то уже знаете, что наша команда занимается разработкой и развитием пула моделей принятия решений о выдаче кредитных продуктов и банковских гарантий для малого и среднего бизнеса. Сегодня настало время поговорить с вами про пайплайн, который используется для разработки таких моделей. Мы построили достаточно много моделей, так что нам точно есть чем поделиться. К тому же существенный вклад в развитие такого универсального алгоритма внес каждый член команды.
Как интерпретировать предсказания моделей в SHAP
5 мин
Туториал
Одной из важнейших задач в сфере data science является не только построение модели, способной делать качественные предсказания, но и умение интерпретировать такие предсказания.
Если мы не просто знаем, что клиент склонен купить товар, но так же понимаем, что влияет на его покупку, мы сможем в будущем выстраивать стратегию компанию, направленную на повышение эффективности продаж.
Если мы не просто знаем, что клиент склонен купить товар, но так же понимаем, что влияет на его покупку, мы сможем в будущем выстраивать стратегию компанию, направленную на повышение эффективности продаж.
Открытый курс машинного обучения. Тема 6. Построение и отбор признаков
24 мин
Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать шаг в сторону и поговорить о подготовке данных для обучения модели. Известный принцип garbage in – garbage out на 100% применим к любой задаче машинного обучения; любой опытный аналитик может вспомнить примеры из практики, когда простая модель, обученная на качественно подготовленных данных, показала себя лучше хитроумного ансамбля, построенного на недостаточно чистых данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.

Алгоритм поиска ключевых словосочетаний «на пальцах». Анализируем новости
Средний
5 мин
Туториал
В современном мире объем данных в интернете постоянно растет с огромной скоростью. Возникает логичный вопрос: как ориентироваться в этом информационном потоке?
Чтобы упростить себе задачу поиска и обобщения информации IT-энтузиасты применяют технологии генеративно обученных чат-ботов. Наиболее широкое распространение получил ChatGPT. Яндекс, в свою очередь, добавил в браузер YandexGPT, который позволяет тезисно ознакомиться с содержанием страницы. Всё чаще вакансия Prompt-инженера начинает встречаться на hh и Хабр Карьере. Специалисты и чат-боты помогают конечному пользователю экономить время для поиска необходимой информации.
Но что делать, если возможности обратиться за помощью к подобным технологиям нет? Указанные выше языковые модели нельзя интегрировать в собственные проекты, сценариев их использования много, но они всё равно ограничены.
В статье мы расскажем, как (не без нейронных сетей) можно создать простой алгоритм на Python, который поможет извлекать ключевые слова из любого текста, тем самым избавляться от ненужной информации и автоматизировать процесс анализа материалов. Мы будем работать с русским текстом, а именно — с новостными постами. Поэтому в частном случае используются пакеты для обработки, поддерживающие именно русский язык. В том числе используются модели, обученные на корпусах текстов с новостной семантикой.
Функциональное программирование в Python: ежедневные рецепты
Средний
21 мин
Туториал
Как говорится, спроси пять программистов, что такое функциональное программирование, получишь шесть разных ответов. В целом это программирование через функции в их математическом понимании, то есть когда функция принимает что-то на вход и что-то возвращает на выходе, не меняя глобального состояния.
В своей команде — команде разработки инструментов для разработчиков под KasperskyOS — мы создаем разные интересные консольные утилиты, эмулятор, обеспечиваем интеграцию с IDE и так далее. И для этого мы используем разные языки — C++, C, TypeScript; но больше всего пишем на Python.

В этой статье, которая написана по следам моего выступления на конференции PiterPy, я обращаюсь к практикующим разработчикам — расскажу о том, какие функциональные приемы можно использовать в этом языке. Сконцентрируюсь на практике — на тех примерах, которые можно использовать уже буквально сейчас, не переписывая свой проект.
В своей команде — команде разработки инструментов для разработчиков под KasperskyOS — мы создаем разные интересные консольные утилиты, эмулятор, обеспечиваем интеграцию с IDE и так далее. И для этого мы используем разные языки — C++, C, TypeScript; но больше всего пишем на Python.
В этой статье, которая написана по следам моего выступления на конференции PiterPy, я обращаюсь к практикующим разработчикам — расскажу о том, какие функциональные приемы можно использовать в этом языке. Сконцентрируюсь на практике — на тех примерах, которые можно использовать уже буквально сейчас, не переписывая свой проект.
Apache Spark и PySpark для аналитика. Учимся читать и понимать план запроса в SparkUI
7 мин

Продолжаем выводить ваши знания о PySpark на новый уровень :) В этот раз расскажем, что такое план запроса, как его смотреть, и что делать, чтобы уточнить узкие места в расчётах.
Как начать в DL: книги и курсы
3 мин
Дайджест

What's up guys!
В этой статье мы поговорим о полезных материалах для изучения тем глубокого обучения и немного ИИ. В статье я дам список полезных ресурсов и немного советов по.
Яндекс Карты открывают крупнейший русскоязычный датасет отзывов на организации
6 мин

Сегодня мы хотим поделиться новостью для всех, кто занимается анализом данных в области лингвистики и машинного обучения. Яндекс выкладывает в открытый доступ крупнейший русскоязычный датасет отзывов об организациях, опубликованных на Яндекс Картах. Это 500 тысяч отзывов со всей России с января по июль 2023 года.
В этой статье я расскажу, чем полезны отзывы с точки зрения исследований, в чём особенность этого датасета, а также покажу примеры задач, которые можно решать с его помощью.
Другой GitHub: репозитории по Data Science, визуализации данных и глубокому обучению
6 мин

(с)
Гитхаб — это не просто площадка для хостинга и совместной разработки IT-проектов, но и огромная база знаний, составленная сотнями экспертов. К счастью, сервис предоставляет не просто инструменты для работы с открытым исходным кодом, но и качественные материалы для обучения. Мы выбрали некоторые популярные репозитории и отсортировали их по количеству звезд в порядке убывания.
Эта подборка поможет разобраться, на какие именно репозитории стоит обратить внимание, если вас интересует работа с данными и сфера глубокого обучения.
Бутстрап: швейцарский нож аналитика в A/B-тестах
Средний
9 мин
FAQ

Вам надоело каждый раз разбираться какую гипотезу, а главное с какими ограничениями к имеющимся данным проверяет бесчисленное множество статистических тестов?
Тогда бутстрап — это ваш выбор. Он не требует никаких параметрических предположений о данных или какой-либо нетривиальной математики и, вместе с тем, может быть применен к широкому спектру статистических оценок.
От логики и риторики до теории множеств и матанализа. Полезные материалы по Data Science и машинному обучению
Средний
21 мин
Мнение

Привет, Хабр! Меня все еще зовут Ефим, и я все еще MLOps-инженер в отделе Data- и ML-продуктов Selectel. В предыдущей статье я кратко рассказал про основные ресурсы, которые могут помочь начинающему специалисту ворваться в бурлящий котел Data Science. Но после выхода материала я понял, что задача систематизации знаний гораздо сложнее, чем казалось. Настолько, что проиллюстрировать ее можно только табличкой ниже:
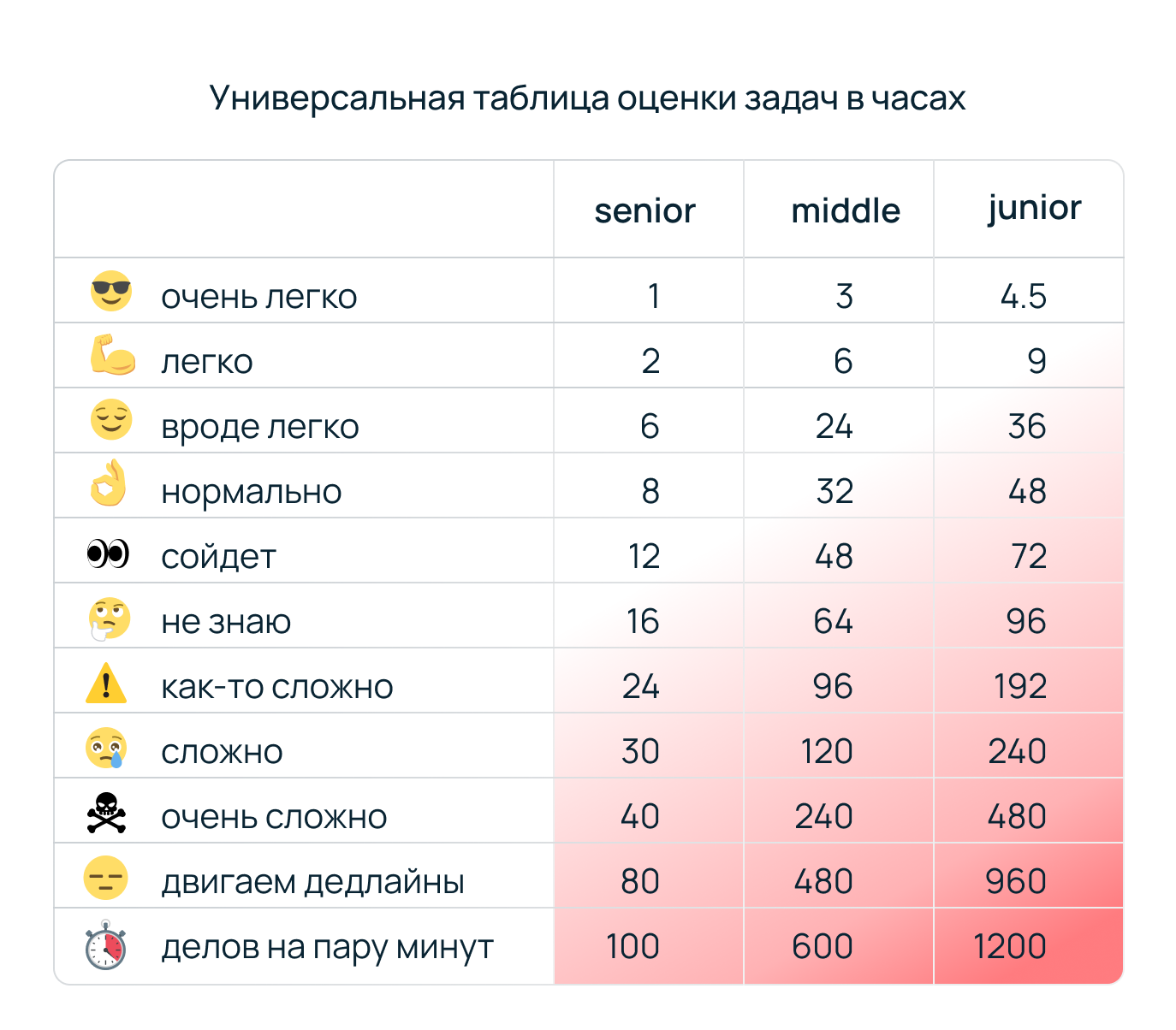
В этом тексте хочу исправиться: разбить знания по Data Science и машинному обучению на несколько теоретических блоков и дать больше полезных материалов. Подробности под катом!
Почему анализ ошибок – это начало разработки ML системы, а не конец?
20 мин
Мнение

Мы школа онлайн-образования, которая уже три года делает курсы по Data Science и разработке. Одна из наших целей – собрать коммьюнити классных специалистов и делиться крутыми и неочевидными знаниями. Так был рождён Симулятор ML – место, в котором начинающие и опытные специалисты решают задачи разной сложности, разрабатывают проекты в командах, осваивают новые инструменты, развивают продуктовое мышление и постоянно растут в профессии.
А, как это свойственно коммьюнити, горящему идеей, студенты и авторы хотят делиться своими инсайтами и открытиями, которые дадут свежий взгляд на устоявшиеся практики. Сегодня хотим поделиться статьей автора Симулятора ML Богдана Печёнкина о том, как лучше использовать анализ ошибок для разработки ML систем.
Пять книг про NLP, с которых можно начать
Простой
3 мин
Обзор

Всем привет! Меня зовут Валентин Малых, я — руководитель направления NLP-исследований в MTS AI, вот уже 6 лет я читаю курс по NLP. Он проходит на платформе ODS, а также в нескольких университетах. Каждый раз при запуске курса студенты спрашивают меня про книги, которые можно почитать на тему обработки естественного языка. Поскольку я все время отвечаю одно и то же, появилась идея сделать пост про мой список книг, заодно описав их.
Machine Learning: хорошая подборка книг для начинающего специалиста
4 мин

Книга, как раньше, так и сейчас, — основной источник знаний. Во всяком случае, один из основных. И читать книги нужно специалисту любого профиля и уровня. Сегодня публикуем относительно небольшую подборку книг для специалистов по машинному обучению. Как всегда, просьба: если у вас есть собственные предпочтения по книгам в этой отрасли, расскажите о них в комментариях.
Чему учат на курсах Data Science? Примеры задач для аналитика на фармрынке
Простой
3 мин
В заметке приведены некоторые актуальные аналитические задачи индустрии. С помощью этого списка вы можете оценить насколько вам может быть интересно учиться на DA/DS, а если у вас уже есть опыт, то обогатите свои знания задачами из фармацевтической отрасли.
Пережевывая Матрицу Несоответствий — Confusion Matrix
Простой
7 мин

Понятие Confusion Matrix является довольно простым в объяснении, но при этом начинающим Data Scientist-специалистам бывает порой нелегко разобраться в отношениях True Positive (TP), False Positive (FP), True Negative (TN), False Negative (FN) — кирпичиками, составляющими данную матрицу. Цель этой статьи познакомить читателя с альтернативным представлением Матрицы Ошибок. Данный способ, по мнению автора, является наиболее наивным методом графического восприятия самой Матрицы Несоответствий, не предполагающий запоминания самой таблицы матрицы. Данный подход позволит легко ориентироваться в выводах, основанных на комбинации элементов Confusion Matrix, глубже понять проблему дисбаланса классов в задачах классификации.
Шпаргалка по Seaborn. Делаем матрицы красивыми
Простой
8 мин
Туториал
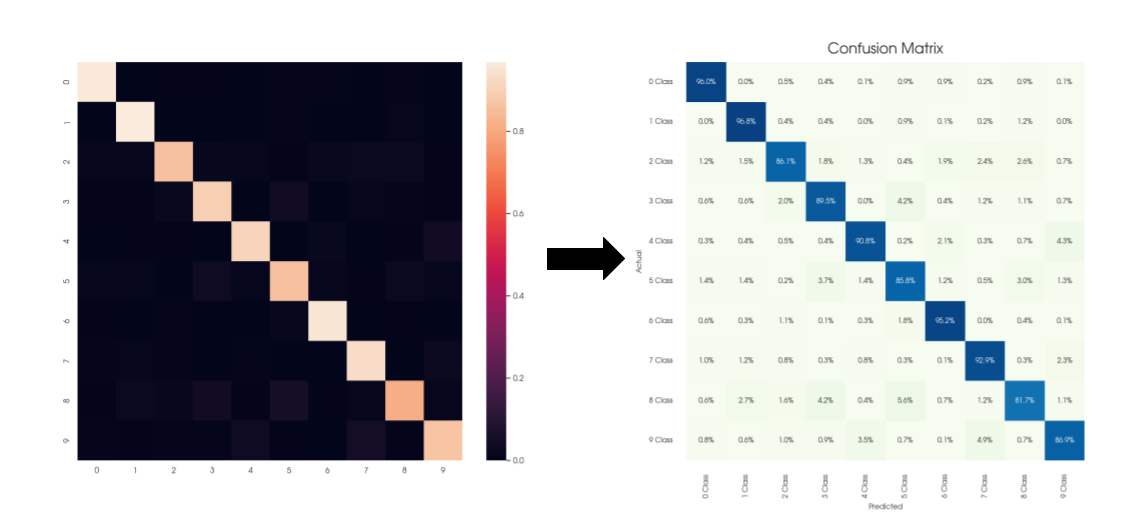
Привет, Хабр!
Часто в работе аналитика данных при подготовке очередного отчета или презентации, колоссальное количество времени уходит именно на графическую составляющую подготовки.
Ведь все хотят сделать отчет не только информативным, но и визуально привлекательным.
В этой статье мы разберем основные шаги, которые помогут сделать ваши матрицы стильными и продающими ваши результаты, используя лишь две основные библиотеки визуализации в Python - Seaborn и Matplotlib.