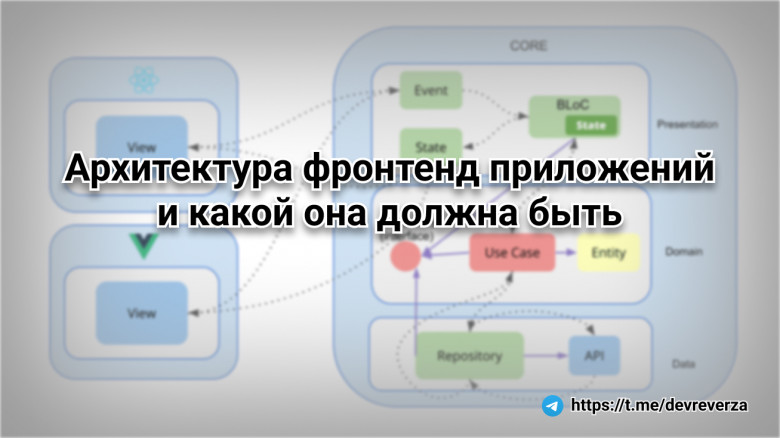
Говоря о качестве, обычно имеют ввиду некое соответствие требованиям. Часто под требованиями подразумевают те, что явно выдвинул заказчик, аналитик или кто-то другой, кто ставит задачи. Хуже, если они трактуются как неоспариваемые, и это неявно ведёт к самоцели — удовлетворить требования заказчика. Это часто происходит в аутсорсе, и такой фокус внимания негативно влияет на конечный результат — то, что видят и с чем работают пользователи.
Мы в SmartHead тоже занимаемся заказной разработкой, и я предлагаю рассматривать качество шире. Это не только про соответствие явно озвученным требованиям, но и про сами требования. Про дополнение явных требований своими, ориентированными не на потребности заказчика, а на удобство конечного пользователя. Пользовательский опыт, юзабилити, тексты в интерфейсе, отзывчивость, скорость релизов, их соответствие ожиданиям — всё это тоже относится к качеству.
Качество — это про «сделать классно» с точки зрения многих сторон: разработки, заказчика и конечного пользователя.
Как это сделать? Сложно. Начать стоит с формирования mindset на «встроенное» качество. Расскажу о принципах, которые могут помочь в этом.