В последние годы большие языковые модели (large language model, LLM) совершили революцию в мире искусственного интеллекта, став фундаментом для множества различных сфер, от чат-ботов до генерации контента. Однако такой прогресс несёт с собой и новые сложности; в частности, разработчикам нужно обеспечить оптимальность и этичность моделей. При выполнении этой задачи критически важны бенчмарки, представляющие собой стандартизированные способы численного измерения и сравнения моделей ИИ с целью обеспечения согласованности, надёжности и справедливости. В условиях быстрого развития LLM возможности бенчмарков тоже существенно расширились.
В этом посте мы представим подробный каталог бенчмарков, разбитый на категории по сложности, динамике, целям оценки, спецификациям конечных задач и типам рисков. Понимание их различий поможет вам разобраться в бенчмарках LLM в условиях их стремительного развития.

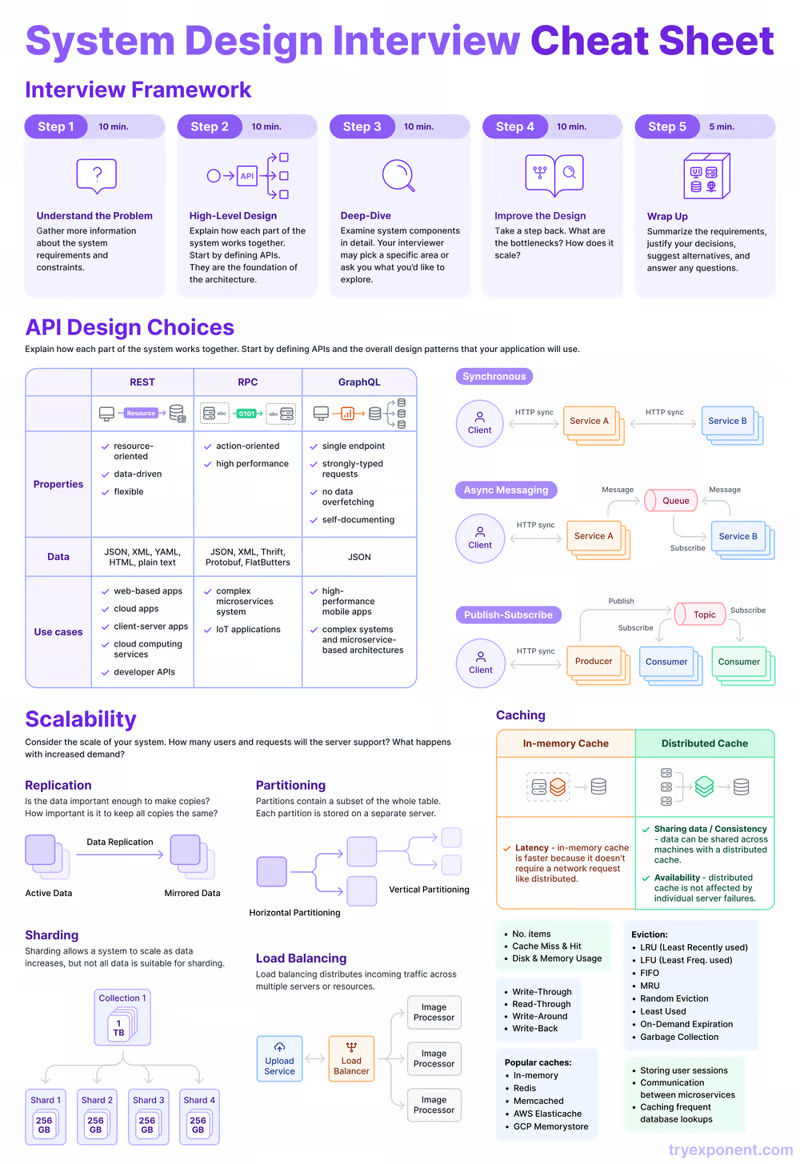
 Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.
Привет, меня зовут Костя Кардаманов, я работаю в отделе технологий разработки Яндекса. Обычно такой же фразой я приветствую и кандидатов на собеседовании. А сегодня я хотел бы рассказать вам, как и зачем мы проводим интервью по дизайну систем с бэкенд-разработчиками. Сразу скажу: для фронтендеров, мобильных разработчиков и ML-инженеров подобный тип собеседований применим слабо, так что эти специальности мы здесь обсуждать не будем.