Comments 718
Но ещё больше бесит, когда продукты, которые по своей сути должны являться mobile first не имеют нормального приложения на телефоне, а только планируют его сделать, особенно когда этот продукт для менеджера «в полях».
Меня одного бесит промотка статьи при открытии? Скачет все хрен знает как и куда. Зачем? На крайняк добавьте настройку, «проматывать при открытии». Уверен, 99% отключат шнягу эту. А то грузится статья с каментами, уже половину прочел, вдруг скачок вверх. Бред какой-то.
В то время, как почти везде перейти в начало страницы до этих же кнопок — одно/два нажатия.
А чего стоит вдоль и поперек перепиленная джаваскриптом textarea для набора комментария… Даже на моем i7 буквы при наборе комментария появляются с заметным отставанием при небольшой скорости набора. А если набирать быстро, то часть букв пропадет, а другая часть встанет не на свое место.Вот этот текст я был вынужден редактировать несколько раз из-за пропадания и перемешивания букв.
А на айпаде набрать ответ вообще невозможно из-за жутких тормозов в десятки секунд.
Но это же все неважно, правда, Boomburum ?
Чтобы тупил ввод конкретно на Хабре, такого не помню.
Единственно я не залогинен, мб это пропадает после логина?
1. открывать ссылки правой кнопкой мыши «открыть в новой вкладке»
2. надоедливое окно с регистрацией, которое закрывает весь экран можно парой кликов убрать в firefox в режиме инспектора. Просто ткнуть в него и удалить из дерева. Дальше можно про него забыть.
Веб версией после реги вполне позволяет…
Как я понимаю — они просто закрыты блоком весь экран и на этом успокоились. Просто возможно там остаётся иногда поверх него ещё какой-то блок, который клики перекрывает. Но почему это работает через раз и почему работают кнопки непонятно. Времени сейчас посмотреть нет :(
Что, и пост можно сделать? Видео залить, например? Это же дико неудобно, коллега делаешь видео в Premiere, закидываешь на телефон и только с него постишь. И ещё и отложенную запись просто так сделать нельзя…
В общем, автор был прав — это приложение ориентировано на тех, кто делится селфи.
Просто он недооценил коммерческое количество таких людей, ине учёл, что профессиональная аудитория как раз сумеет подстроиться ко всему.
Точно так же люди массово пользуются WhatsApp вместо Telegram, хотя там нельзя даже сообщение отредактировать, и ещё десяток полезных функций отсутствует. Зато он понятнее.
Меня тоже реально бесит что работаешь за ноутбуком или ПК и для того, чтобы «полноценно» пользоваться каким-то приложением с него (да пускай тем же самым Инстаграммом) нужно на ПК поставить эмулятор Андроид.Вас бы меньше это бесило, если бы на компьютере был бы предустановлен эмулятор андроид, позволяющий прозрачно запускать любые приложения из гугл-плей скажем? То есть качнул и запустил — без доп. плясок с бубном, но технически это был бы «инстаграм в эмуляторе», а не нативное приложение.
Вопрос не риторический, ответ правда интересен, особенно если подробный.
Делаете продукт — делайте для него нормальную веб-версию, по тому что браузер можно открыть на любой кофеварке.
Я не буду от каждого сервиса приложение ставить чтобы посмотреть что у вас там.
Интересно значит когда вэб браузерами ломали user experience в нормальных приложениях вы были за это а как браузеры прошли на свалку так против? ;)
Когда-то были удобные приложение "толстые клиенты" в которых были нормальные сочетания клавиш, последовательность выбора объектов, подогнанные расположение элементов (чтобы нужная информация была рядом), удобное редактирование, отсутствие потерь информации из-за нажатия f5 (или просто протухания сессии ;) ). Но нет модой стал web anywhere :) а теперь просто следующий шаг.
И ладно когда это Инстаграм, который изначально для плиток с камерой и их владельцев, так нет сейчас у нас справочные ресурсы под телефон с кнопками в пол экрана и свёрнуты и по умолчанию комментариями :)
Когда-то были удобные приложение «толстые клиенты» в которых были нормальные сочетания клавиш
Я, кстати, потому из аппаратных гипервизоров держусь за xen — у него есть отдельный клиент. А esxi и прочие proxmox уже только в браузере.
Интересно значит когда вэб браузерами ломали user experience в нормальных приложениях вы были за это а как браузеры прошли на свалку так против? ;)Смотря о каких приложениях идет речь.
Тяжелые проф. приложения типа графических редакторов, IDE, офисных пакетов должны быть полноценными приложениями с полноценным интерфейсом — так было и так есть.
А вот всякая информационная мелочевка с парой кнопок интерфейса прекрасно работает в браузере и не требует отдельного софта. Помнится в начале 2000-х у меня была куча всяких информационных приложений: карта города, справочник лекарств, и т.п. — сейчас все подобное доступно в Веб.
Я не буду от каждого сервиса приложение ставить чтобы посмотреть что у вас там.Спасибо. Неожиданный ответ.
Нам как старым десктопщикам привычнее как раз когда на десктопе можно поставить отдельную прогу для отдельной задачи. К онлайн мсоффису не привыкли до сих пор — пользуемся десктопным, долгое время на форумах предпочитали сидеть через оффлайн клиент — сейчас они просто вымерли все, до сих пор оффлайновым десктопным почтовым клиентом пользуемся и так далее.
а есть задачи которые надо сделать разово и забыть о них, вот тут веб однозначно в плюсе.
Время от времени попадаются ноуты (в основном — девичьи), на которых открыто неподдающееся никакому учету количество окон (не вкладок :) примерно трех разных браузеров (или всех, что есть на компе) — это как раз и есть «сделать разово» — но не забыть :)
Самое интересное — владельцы ноутов как-то ориентируются в этом лабиринте и ухитряются находить нужное.
Но вот установка обновлений с последующей перезагрузкой — для них настоящая боль :)
(ноуты никогда не выключаются, владельцы этой кнопкой не пользуются: открыл/закрыл и все дела :)
В нормальных десктопных программах используется концепция «открыл — поработал — сохранил и закрыл». В браузерах с этим есть определенные проблемы, что и приводит к описанным выше результатам.
Закладки людьми не используются, так как процесс создания закладки обычно сложнее процесса сохранения обычного документа.
Нажать на звездочку в адресной строке это сложнее нажатия иконки дискеты?
Да.
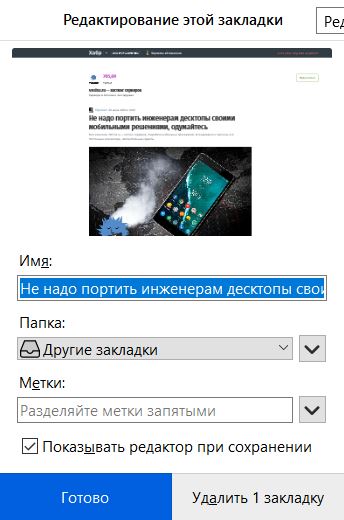
Пункт Папка: по дефолту — «Другие закладки»
Попытка сменить папку выводит на систему навигации по папкам, заметно отличающуюся от простой навигации по папкам файловой системы ОС.
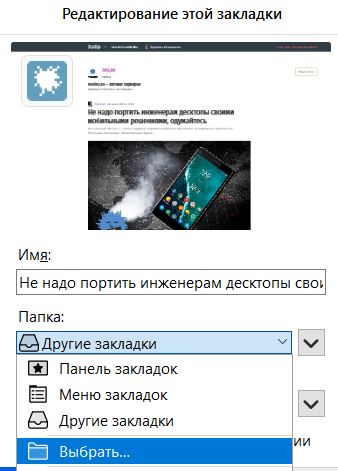
В результате у обычного пользователя возникают проблемы, приводящие к тому, что либо пользователь не может найти сделанную им закладку, либо все закладки сваливаются в одну кучу в папку «Другие закладки».
А попытка создать иерархию (с перемещением закладок туда-сюда) становится делом нетривиальным и весьма утомительным.
Плюс далеко не все пользователи слышали о функции облачной синхронизации данных в браузере — и тем более — умеют ей пользоваться.
И плюс плюс — пользователи пользуются несколькими разными браузерами на одном компьютере одновременно.
В результате имеем умножение сущностей сверх необходимого, и любая программа типа OneNote становится намного удобнее системы закладок в браузерах.
Я один перетаскиваю вкладку на панель закладок, которая вся в заранее созданных папках?
Все с этого начинают :) Я — не исключение.
Но потом возникают ситуации, когда компьютеры меняются по несколько раз в день.
Компьютеры с разными браузерами.
Чужие компьютеры, на которых что-то устанавливать и настраивать в собственных интересах нельзя.
В такой ситуации синхронизация вкладок через облако браузера теряет всякий смысл.
Намного проще зайти в уже упомянутый OneNote через тот же браузер и получить доступ ко всей своей коллекции ссылок (которая может быть весьма обширной- 16 блокнотов по темам, по десятку-полтора разделов в каждом блокноте, по сотне страниц в каждом разделе, десятки ссылок на каждой странице :)
А обычные пользователи пасуют уже при виде альтернативы в лице трех вариантов (см картинку выше):
«Другие закладки»
«Панель закладок»
«Меню закладок»
И еще один пункт «Другие закладки» (уже внутри пункта «Другие закладки» :)
Все, такого количества близких по смыслу вариантов — уже вполне достаточно для хаоса в голове обычного пользователя
Сколько ни читаю про подобные случаи, ни разу не сталкивался.
Преподаватель проводит занятия в компьютерных классах.
Одна пара у него в корпусе А, вторая, на другом факультете — в корпусе Б. Затем он едет проводить занятия в колледже — корпус В. При этом, в зависимости от расписания, компьютерные классы даже в пределах одного корпуса меняются.
В такой ситуации даже флешку в эти компы вставлять нельзя, это как в борделе… нет, это хуже чем в борделе — там хоть проверяют состояние здоровья время от времени…
Про командировки-конференции и прочее и речи нет.
Я бы не стал на таких ПК входить в какой либо аккаунт.
Я тоже предпочитаю использовать Continuum (не помню, в какой именно теме я вчера давал описание его использования, может быть и в этой)
Но не всегда есть время на подключение/отключение.
Поэтому используется специальная учетная запись, заточенная сугубо под конкретные задачи.
Если вы, например, закрыли, открыли (пока есть активный пункт восстановить сессию), снова закрыли (случайно) — оно не появится, сессия потеряна. В Firefox по крайней мере именно так.
Один раз так ошибившись можно напугаться настолько, что потом отказываться закрывать под любым предлогом.
У меня вот ни разу проблем с этой кнопкой не былоОшибка выжившего )
Не понимаю вообще, зачем эту страницу выводить. Просто нужно восстанавливать предыдущие вкладки по дефолтуВот лично я не люблю восстанавливать предыдущую сессию, потому что стараюсь держать открытыми только нужные именно сейчас вкладки.
Почта — тут уже кому как. В своё время, когда почта шла большим потоком, был большим поклонником the bat с его системой фильтров. Сейчас же количество почты резко уменьшилось, потому вполне хватает и веб-интерфейса с нормальным поиском.
А почта — у Gmail/GSuite не такая уж плохая система фильтров… настраиваемая через веб-клиент а не мобильные приложения. У всяких Zimbra оно тоже есть.
Тем более, что у меня есть оффлайновые приложения — так что облачным офисом вообще смысла пользоваться нет в повседневной жизни. Очень изредка с чужого компьютера запускается.
Я только это увидел — сразу закрыл и вернулся к google docs, хотя он меня и не полностью устраивает.
Заполнить форму — не проблема, регистрация на гугле тоже не одно поле заполнить.
А заполнять длиннющую (по нынешним временам) форму, чтобы просто попробовать какой-то сервис — данафигэтоникуданеупёрлось!
Если вообще есть.
Но пароли помнятся в каком-то менеджере паролей в минте и дальше уже хром с этим сам разбирается.
Поэтому войти под гугл (вк или где там я ещё зареген) аккаунт ещё проще: даже пароль не надо помнить.
А тут предлагают заполнить какую-то форму, придумать логин, пароль ещё там что-то.
Плохо идеологи платформы подумали.
Я, вон, даже на али покупаю под… не помню… ВК-аккаунтом что-ли.
А то каждый интернет магазин на SPA, торгующий спиннерами будет требовать уникальную, именно для себя регистрацию — смешно даже…
можно войти под аккаунтом других распространённых веб-сервисов.
Почему-то у меня во всех случаях, когда я пытаюсь войти под аккаунтом фэйсбука или гугла, оттуда дёргают только почту, а остальные данные требуют ввести дополнительно.
Просто. Заходите на двач и общаетесь, качаете картинки, видеоролики без смс и регистрации.
Если на свой сервер надо — есть ж community edition www.onlyoffice.com/ru/download.aspx (+гитхаб)
На стартовой странице уяснил, что штука платная, но есть триал на 180 дней.
ОК — ткнул «Попробовать в облаке» — увидел длинную форму — закрыл.
К вопросу о дезигнерах интерфейсов.
Это не дезингеры интерфейсов виноваты… это маркетологи хотят собрать с вас максимум инфы.
Босс придумал некую "анкету контагента" из 240 полей, включая чекбоксы. Потенциальный контрагент должен заполнить вот это всё только ради того, чтобы "попобовать" поработать с Газпромом в области ремонта спецтехники. Воевал-воевал с ним, да все бесполезно: бигдату босс хочет...
Так что вполне может статься, что вы еще не встечали по-настоящему длинных форм :)
Попытка отредактировать вордовый документ с track changes и комментариями вне MS Office разрушит этот документ с вероятностью 99%.
А это не такой оедкий кейс, и для аналитика, и для юриста.
Gmail и прочие: нормальных таблиц не вставишь, копипаст из Ворда не сделаешь.
Вот последний файл, который мне присылали для заполнения:
OnlyOffice: banshee.ms/public/screenshots/2020-07-30_072645.jpg — плющит, накладывая таблицы друг на друга.
ГуглОфис: banshee.ms/public/screenshots/2020-07-30_072925.jpg — наоборот, разносит на две страницы.
Office365 онлайновый: banshee.ms/public/screenshots/2020-07-30_073110.jpg — тоже разносит, как в гугле.
А вот так оно должно выглядеть: banshee.ms/public/screenshots/2020-07-30_073206.jpg (оффлайновый офис).
Лучшие результаты показывает оффлайновая либра — там только верхняя табличка чуть вправо уезжает, но это довольно легко исправляется.
Вот потому онлайновые офисные пакеты полноценного документооборота слабо подходят, если уж даже MS не может нормальную совместимость онлайн и оффлайн версий обеспечить.
это в первую очередь проблема конкретного документа сверстанного непонятно кем и непонятно как.
Нет, это не проблема документа. Это моя проблема. Ибо автор документа скажет «на моей стороне всё нормально», а прогибать большой МТС под маленького меня — без шансов.
Вот если вы сами большой, то маленьких окружающих можете прогибать хоть под либру, хоть под гуглодоки, хоть под лексикон досовский.
с юрлицами все зависит от наличия в штате хороших юристов, ну или одного хорошего юриста
Юристы первые, кто просит MS Office им купить, чтобы не возиться с форматированием. Плюс ещё они любят всякие истории редактирования и выноски ставить, а это между либрой и MSO ещё хуже переносится, чем таблички.
хуже всего, что весь этот зоопарк приложений оказывается просто обёрткой для взаимодействия через браузерные интерфейсы.
OK, закрываем сберприложение, следом открываем браузер на этом же телефоне, заходим в веб-интерфейс сбера и теперь платёжки можно подписывать на любые суммы! Але! Вы чего там в сбере накурились? :D
И это всё еще при том, что в сбер-приложение встроен анальный зонд имени кашпировского вирусы, типа, отлавливать, а браузеру доверяем слепо!
Насколько я помню, имея вашу симку и зная номер карты, можно просто установить приложение сбера и увести все ваши деньги.

Или вместе с ним отключится и смс информирование о состоянии счёта?

Но, кстати, да, пока пополняет и в ответ приходит «С 31.08 оплатить свой телефон через СМС-запрос можно будет, если подключена опция «СМС-платежи»».
Если отправить платёж на другой номер, то никакого ответа нет.
Если отправить USSD пополнение другого номера, то получаем ответ «Операция не выполнена. Для проведения ПЛАТЕЖА подключите опцию «СМС-платежи»».
Так что работает частично.Но через три дня заработает как надо.
Увы, гугаккаунт при заходе с другого IP начинает вымогать номер, и, если никакой номер не привязан, то принимает любой
У меня для этого есть специальная сим-карта, только для Гугла.
(и еще одна — для Микрософта :)
Хорошее, конечно, решение, но уж больно геморрное
Ничуть: двухсимочный смарт и мобильная точка доступа.
Точка доступа маленькая и легкая, плюс для меня необходимая.
(Плюс отдельная сменная карта для всех явных будущих спамеров :)
Ну, с двумя симками скрытие от гугла так себе.
Гугл всегда видит одну сим-карту.
При необходимости скрыть гугл о гугла используется третья сим карта, в мобильной точке доступа.
Первая же используется только для звонков.
Хотя у меня есть большие сомнения, что можно скрыть гугл от гугла в принципе — есть куча других факторов, кроме номера телефона.
С паролями у большинства пользователей творится полная лабуда.
Один пароль для всех ресурсов — это еще наименьшее из зол.
И конечно же учить пользователей паролям никто не стал
А это бесполезно.
Все равно человек пойдет по пути наименьшего сопротивления и, в конечном счете, выберет наименее трудозатратный вариант- либо простой пароль, либо бумажка на мониторе/файл с паролями на компе, либо один пароль для всех ресурсов.
Проверено многократно.
И конечно же учить пользователей паролям никто не сталА еще есть простой вариант, почему-то многим неочевидный.
Пользователь оценил риск инцидента и ожидаемый ущерб, признал его ничтожным, и использовал пароль «qwe123».
Но увы — аффтыри сервиса они же умнее — только strong password для форума с котиками! 16 знаков, прописные и строчные, цифры и спецсимволы, проверка по словарям, смена раз в месяц — Пентагон плачет в уголку :-)
Вот от паролей и ушли.
В Альфа- банке у меня при восстановлении утерянной симки перестало работать приложение.Они отслеживают номер симки, что на мой взгляд очень даже правильно… Злоумышленник при замене симки не сможет войти в мобильное приложение, потому что на новой симке номер будет другой… Позвонил оператору, объяснил ситуацию, ответил на кучу вопросов, и все заработало...
А если нет, то её достаточно вытащить из аппарата
А кто позволит вытаскивать симку из своего телефона?
Это очень заметная процедура, на глазах не сделаешь.
При этом я давно уже не замечал, что бы народ своими телефонами разбрасывался, сорри, люди даже в сортир идут с телефоном.
Потому как на телефоны сейчас много завязано — в том числе и сугубо личного, что понятно уже даже самым беспечным.
Сейчас смарт уже как связка ключей, и отношение тоже соответствующее.
А кто запретит вот тому гопнику с кирпичом, или вору, который уже украл устройство? А утеря?
При утере или краже, а так же и при грабеже- пострадавший всегда может блокировать свою сим-карту, либо у провайдера мобильной связи, либо на ресурсе, где используется этот номер.
Исключением является случай «сняли с бесчувственного тела, наконец — с трупа!» (с).
Но трупу уже в принципе все равно.
Ну так если у вас из телефона вытаскивают симку, то заодно из кошелька вытащат наличку и карточки. И, кажется, хорошо, если больше ничего не вытащат и вы своим ходом до полиции дойти сможете, и симка будет меньшей проблемой. Не?
Ну так если у вас из телефона вытаскивают симку, то заодно из кошелька вытащат наличку и карточки.
Был у нас случай, когда человек вечером поймал попутку и в конце пути сказал, что расплатится, сняв наличку с банкомата. Попросил остановится у ближайшего.
Его вывезли за город и запытали до смерти — узнавали пин-код.
Думаю человек имел в виду другое. есть необходимые отдельные приложения. калькулятор, фонарик, браузер, офис, плеер и т.д, а дальше пошел треш. Хочешь инсту — приложение, мордокнигу — приложение, контакт — приложение, хабр — приложение, 4pda — приложение, алиэкспресс — приложение.Это не другое по сути, это просто другая оценка того же самого.
Лично для нас это не треш, а наоборот неплохо, когда отдельные функции реализуются отдельным десктоп-приложением.
Та же почта. До сих пор предпочитаем десктоп-клиент, хотя все современные люди используют почту в браузере. Брокерское приложение — можно в браузере, но поставили десктопное. Для некоторых форумов до сих пор приложения используем десктопные, а не браузер. В вордпресс из ворда постим, а не с браузера.
Мы не говорим что это правильный подход, просто ну вот так вот — мы не перестроились на использование браузера, кто-то не перестроился на использование мобилы — каждому своё, ничего плохого в этом нет.
Плюс если так посмотреть, фактически браузер здесь выступает как условная виртуальная машина для запуска приложений. Поэтому…
МНОГО приложений для телефона имеют главную цель: показать как можно больше рекламы. В браузерах с этим давно разобрались с помощью ад-блокеров, поэтому злые маркетологи придумали отдельные приложения :)
Другой вопрос, что если бы вместо Android была бы мобильная OS-броузер, у которой нет различия между приложениями и вкладками, то может быть, это было бы и лучше.
Как пример (полагаю, что удачный) могу привести так называемые браузерные игры «Троецарствие» и «Танки онлайн». В первую давно играл, во второю иногда играю. В них можно играть в браузере, но не всегда удобно и иногда тормозит, но можно, зависит от мощности ПК и ширины канала. Официальный клиент игры это по сути браузер, но заточенный под один сайт (одно приложение). В целом вроде бы неплохо. У Битрикс24 так же новый клиент выглядит. Но у тех же Танков онлайн новая версия клиента это по сути эмулятор телефонной версии на ПК. Скачал, запустил, но лично мне не нравится визуально (за 7 лет игры привык к другому виду «гаража», «настроек» и т.п.).
Есть кейс ещё интереснее, называется "плохое качество мобильной связи в конкретном месте"...
Это плата за e2e шифрование без большой головной боли.
А так — большинству как-то пофиг на шифрование, если оно удобству использования мешает. Тем более, что я слышал про то, что в ваззапе нормального клиента пилят. Правда это было в прошлом году ещё, так что либо забросили, либо одно из двух.
И даже не с интернетом, а с той локалкой, в которой сидит комп.
В ТО вроде бы до сих пор флеш-версия рабочая, её можно через standalone player запустить. Как игрок с семилетним стажем вы, вероятно, про это знаете.
Меня бы бесило. Меня вообще бесят виртуальные машины, удаленные рабочие столы и прочее, потому что там не мое родное настроенное окружение, а черт знает что. И если приложение с предустановленным андроидом захочет авторизоваться в гугле, оно не откроет мой десктопный браузер, где я уже авторизовался. Ну, это возможно, но потребует поддержки со стороны гостевой ОС. И сколько еще точек взаимодействия придется проработать? И вот из кучи таких мелочей складывается адское неудобство.
А уж ели в каком-то разумном виде заработает хотя бы часть гуглосервисов — то это будет вполне себе победа, запустил полдесятка андроидо-приложений, каждое в своем окошке одновременно — лепота…
И подозреваю, куда-то в эту сторону мы в итоге и придем.
Даже жалко, что лайтовое железо, которое тащит по 10 часов не чихая Хром с кучей вкладок, связку эту по факту не тянет. В итоге нужен хромбук, но с железом полноценного лаптопа. И тут уже проще влепить убунту и перестать натягивать сову на глобус. Ну или разделить на два девайса — вот тут хром, вот тут хрень.
А у влепленной убунту будет минус — не столь удобная интеграция с приложениями android. Шашлык от KDE так и не появился, да и Anbox далеко не идеал. Ну и планшетного интерфейса нормального не будет.
И как оно сейчас? Я его тыкал, когда вышел, ничего толком не работало.
Все так же запутанно и требует большого бубна. Первый запуск все так же крышесносящ — о том как называются два демона на вики не пишут, но прилагают картинку о том что они существуют :-)Примерно как anbox сейчас делает
И как оно сейчас?
Правда появились отдельные «выжившие», которые скриптуют установку тех же opengapps… но не только лишь всякий может долйти до этого шага.
Мне для своего кода надо было, а штатный эмулятор бесит неимоверно. Можно было конечно использовать реальный телефон — но я как раз с графикой развлекался, на мелком экранчике как-то не очень.
Так что opengapps существует — и хорошо, если понадобится — попробую :-)
а есть версия от противного — samsung Dex
В случае с эплом, это просто бонус фича к арм макам, имхо
Такое ощущение, что Каталист приложения будут позиционироваться как полноценные маковсковские приложения с адаптацией UI конкретно для мака. К примеру, UISwitch превращается в checkbox (NSSwitchButton). И это будет работать как на arm, так и на x86-64
А вот запуск iOS апп на арме — альтернатива для тех, кто не хочет заморачиваться с портированием и будет просто работать.
— А давайте на мобильных устройствах напишем всё заново, там же всё другое! Ой нет, давайте интерфейс сделаем один на компе и на мобилке (привет майкрософт!), это же так удобно, когда у вас меню из здоровенных прямоугольников, на мобилке можно нажимать пальцем, а в монитор — головой. Эх нет, неудобно, давайте сделаем разные интерфейсы, вернём пуск. Идея! Надо вообще сделать одни и те же приложения и на мобилках и на рабочем столе. Сейчас мы вам ещё притащим 100500 игрушек «тапни чтобы перепрыгнуть какашку» с мобилок (привет Яблоки).
Работать с телефона/планшета можно если вместо работы из дома лежишь на пляже и в чатиках делаешь вид что работаешь :D
vdsina_m, а вы почему сделали фит с филпакартом? Он у вас типа рекламное лиуо или вроде этого, вы за рекламу ему платите или как?
Но это кстати круто — раз слог фила так легко детектится просто по куску текста — значит можно обучить нейросетку писать тексты в стиле Фила, а того — отправить писать код.
И почему вы считаете, что отправить Фила писать код будет хорошо? Насколько я понял из этой статьи и комментариев к ней, чем меньше он будет трогать клавиатуру, тем лучше.
Это, кстати, уже второй персонаж на Хабре за последний год, который пишет фанфики для программистов, а ему все хлопают.
Я вообще испытал когнитивный диссонанс
Когнити́вный диссона́нс — состояние психического дискомфорта индивида, вызванное столкновением в его сознании конфликтующих представлений (украл с вики).
Ну т.е. когда статью открыл — увидел что это ВДСина
ВДСина — провайдер впс-серваков и прочего подобного, официлальный российский, зарегестрированный в реестре распространителей информации, и по сообщениям их поддержки в чатике — без задней мысли готовый пускать майора на свое оборудование.
почему-то подумал что писал статью Фил.
Автор поста, fillpackart — знаменит на хабре тем, что пишет посты, провоцирующие волны споров, холиваров и прочего хорошего.
Потом подумал — «да не, это ВДСина, просто какой-то копирайтер с двача пишет в стиле Фила»
Два.ч — самая крупная и достаточно популярная среди школоты, студентоты и постаревших, но не потерявших молодецкой тяги к угару людей, русскоязычная «анонимная» имиджборда (форум с картинками без регистрации) — настолько крупная, что иногда на двач в качестве источника ссылаются всякие журналисты типа ленты.
Копирайтер с двача — человек, не имеющей вменяемого источника дохода, и пытающийся заработать выполняя задания на толоке и пописывая поганенького качества тексты на яндекс.дзен, в надежде на монетизацию. Очень часто работают за еду.
Но это кстати круто — раз слог фила так легко детектится
Детектится — распознается.
просто по куску текста — значит можно обучить нейросетку
Нейросетка — нейросеть, например GAN — Генеративно-состязательная сеть (англ. Generative adversarial network, сокращённо GAN) — алгоритм машинного обучения без учителя, построенный на комбинации из двух нейронных сетей, одна из которых (сеть G) генерирует образцы, а другая (сеть D) старается отличить правильные («подлинные») образцы от неправильных (wiki). По-сути, эта та штука, что стоит за проектами типа «thispersondoesntexist» и тысячами разных других.
Надеюсь стало яснее.
Скоро как у Татьяныча будет. Нейросетка будет писать тексты для забора.
Про удобную джира на мобилке улыбнуло
Всё нормально, меня уже убедили, что я болван (тупой)
А меня наоборот. Теоретически это мешает переделывать интерфейс в класс и обратно (главное роль типа в программе, а интерфейс это или класс — вторична). Практически, правда, я соблюдаю нейминг конвеншнс того места, где я оказался.
В Java, кстати, его и не делают, насколько я знаю. Тут вопрос не в том, нужен он или нет, вопрос в том, чтобы писать привычный для шарпистов код на C#. По крайней мере, меня убедили именно таким аргументом.
В Java его не ставят, потому что канонично оперировать именно объектом интерфейса, а не реализующим интерфейс классом (которые часто обозначаются суффиксом Impl, но это не обязательно).
Так и в C# тоже
Я предпочитаю префикс I, это куда нагляднее, чем инверсная логика «нет суффикса — интерфейс, есть суффикс Impl — реализация».
Не могу говорить за все языки, потому как их не знаю.
КМК, ставить префиксы имело смысл в языках без явного синтаксического разделения сущностей (Pascal, C, C++), но там, где семантическая роль выделена синтаксисом самого языка, дополнительное обозначение избыточно. Может еще кто-то кодит в блокноте, и ему/ей сложно искать в коде определение сущности — ну как бы штош...
Возникает вопрос, а почему важно знать интерфейс это или реализация? Ведь везде должны быть только интерфейсы, не?
Например чтобы на кодревью надавать по шапке тому кто поленился и вместо интерфейса использует класс :)
P.S. И да, кодревью далеко не всегда делается в IDE и поэтому удобнее когда интерфейс можно отличить от реализации просто по названию.
Например чтобы на кодревью надавать по шапке тому кто поленился и вместо интерфейса использует класс :)А зачем? Какая разница чем представлен тип — классом или интерфейсом? При условии, что речь не идет об АПИ какой-нибудь библиотеки, а о внутреннем коде.
Если это вот прямо совсем "внутренний код", то никакой. А если речь идёт хотя бы о разных проектах, то использование классов может создать определённые проблемы. Например лишние зависимости между отдельными проектами. Или даже перекрёстные ссылки.
С префиксами в имени такое заметнее. Особенно если ревьюишь не в IDE.
Нет. Префикс "I" или его отсутствие очень просто и быстро видно в самом APl.
И да, с интерфейсами можно тоже кучу глупостей наделать. Просто такая банальная вещь как naming conventions заметно облегчает жизнь отдельным людям в отдельных ситуациях.
Это не значит что все должны их использовать. И уж тем более не значит что всем надо использовать одни и те же. Но вот у нас такие и нам так удобнее.
Интерфейс — прилагательное, класс — существительное, метод — глагол ;)
Выделение интерфейса бывает неизбежным, например, для развязывания кольцевых зависимостей.
А Dependency Injection чем хуже?
Ничем, но это более внешнее требование по отношению к данному компоненту.
Ну, так-то интерфейс — сам по себе анти-паттерн, хотя бы потому, что нарушает SRP. External protocols — это интерфейс здорового человека, а охапка методов, которые каждая собака должна имплементировать, даже если это выходит за рамки разумного, — порождающих безумную копипасту и груду полуживых имплементаций — несомненное зло.
Использование интерфейсов — уже само по себе звоночек, но ведь создатели языков любят еще разрешить пустые интерфейсы, а это уже вообще за гранью здравого смысла (точнее, это признание в собственной некомпетентности).
Интерфейсы кажутся приемлемым решением только людям, которые вообще не способны в архитектуру.
У меня такое впечатление, что вы увидели слово-триггер и завелись на него. Иначе такой поток атаки на интерфейсы сложно объяснить. Но хорошо, попробуем разобрать детальнее, мне уже стало интересно:
Ну, так-то интерфейс — сам по себе анти-паттерн, хотя бы потому, что нарушает SRP.
Чем нарушает-то? Прошу подробностей.
External protocols — это интерфейс здорового человека,
External protocol в контексте ООП вообще не гуглится. Дайте расшифровку, что вы понимаете под этим. Если имеется в виду связь с другими компонентами через сетевые протоколы, то я не понимаю, зачем их тут вообще примешивать.
а охапка методов, которые каждая собака должна имплементировать, даже если это выходит за рамки разумного, — порождающих безумную копипасту и груду полуживых имплементаций — несомненное зло.
Красивый пассаж. Но я бы заменил "даже если" на "только если". То есть зло, если эти механизмы абсолютизируются там, где от них начинается усложнение (и та же копипаста).
Использование интерфейсов — уже само по себе звоночек
Чего именно звоночек-то?
но ведь создатели языков любят еще разрешить пустые интерфейсы, а это уже вообще за гранью здравого смысла (точнее, это признание в собственной некомпетентности).
Пометка, что определённый тип декларируется как обладающий определённым свойством. Конечно, было бы лучше дать возможность компилятору это вывести, но они ещё много лет не будут способны делать выводы только за пределами самых простейших. Если тут кто-то некомпетентен, то человечество в целом. И что, прикажете стреляться атомными бомбами?
Интерфейсы кажутся приемлемым решением только людям, которые вообще не способны в архитектуру.
Ваши альтернативные предложения — в студию. Только конструктивно.
Начну с середины, для связности.
External protocol в контексте ООП вообще не гуглится. Дайте расшифровку, что вы понимаете под этим.
Причем тут контекст ООП? Что в ООП такого особенного, что у него должны быть паттерны, идущие вразрез с не ООП? В Хаскеле это называется Type Class. В Эликсире — протокол. Полиморфизм без необходимости размазывать имплементацию по разным частям кода. Наиболее внятно принципы расписаны в гайдах по эликсиру.
нарушает SRP.
Чем нарушает-то? Прошу подробностей.
Давайте возьмем в качестве примера набивший оскомину Comparable. Сравнение — само по себе сущность, которая, кхм, отвечает за сравнение. SRP решение: описываем type class / protocol, который умеет сравнивать. Интерфейсное решение: каждый класс, который хочет уметь сравниваться, должен, видите ли, немного отвечать за сравнивание. Хотя он, вообще-то, модель User. Вы не видите тут нарушение SRP? С какой радости модель должна отвечать за данные, и еще немножко за сравнивание? А что если я хочу научить чужой класс сравниваться? Аспекты, рефлекшн, магия?
Чего именно звоночек-то?
Того, что люди ведутся на хайп и авторитет вместо здравого смысла.
Пометка, что определённый тип декларируется как обладающий определённым свойством.
Угу. А зачем? Вернемся к Comparable. Кому хорошо от того, что User знает, что он умеет сортироваться? Никому. Сущность «Сравнивание» должна уметь принять пару объектов типа User и либо вернуть -1 | 0 | 1, либо вежливо отказаться сравнивать несравнимое. Тогда и для чужих сущностей я смогу определить любой нужный мне «интерфейс» без хаков и магии.
Ваши альтернативные предложения — в студию.
Озвучил же уже: протоколы / тайпклассы и dependency injection.
Сравнение — само по себе сущность, которая, кхм, отвечает за сравнение. SRP решение: описываем type class / protocol, который умеет сравнивать. Интерфейсное решение: каждый класс, который хочет уметь сравниваться, должен, видите ли, немного отвечать за сравнивание.
И почему нет? Почему нельзя чтобы каждый класс сам решал как для него выглядит сравнение? Чем лучше если ваша сущность «Сравнивание» должна знать как выглядит сравнение для абсолютно всех существующих классов? И если в вашей ситуации мы добавляем новый класс, которые должен сравниваться, то мы должны лезть и менять вашу сущность «Сравнивание». И когда у какого-то класса вдруг почему то изменилось сравнение, то тоже самое — надо лезть в сущность «Сравнивание» и её менять. И при этом мы в теории можем сломать сравнение для уже существующих классов.
А теперь представьте себе что классы скажем пишу я, а сущность «Сравнивание» находится в вашей зоне отвественности(или вообще купленная библиотека). Или я пишу классы, пакую их в библиотеку и отсылаю клиенту у которого где-то там запускается сравнение и сущность «Сравнивание» он там пишет и изменяет сам. Или скажем у вас десять человек пишут классы и пользуются сравнением. Или сто. Или тысяча.
И что теперь делать когда нужно добавить новый сравниваемый класс? Каждый раз просить кого-то там изменить сущность «Сравнивание»?
А интерфейсом Comparable я пишу классы, которые его имплементируют, а кто хочет там просто берёт их и сравнивает так как я это задумал. И ему не надо ничего у себя там писать или менять или думать как вообще должны сравниваться мои классы.
Угу. А зачем? Вернемся к Comparable. Кому хорошо от того, что User знает, что он умеет сортироваться? Никому. Сущность «Сравнивание» должна уметь принять пару объектов типа User и либо вернуть -1 | 0 | 1, либо вежливо отказаться сравнивать несравнимое.
Угу, а потом ваш код великолепно компилируется, а во время исполнения ваша сущность «Сравнивание» начинает выдавать одну ошибку за другой.
Озвучил же уже: протоколы / тайпклассы и dependency injection.
И каким конкретно образом dependency injection должна заменять интефейсы?
И если в вашей ситуации мы добавляем новый класс, которые должен сравниваться, то мы должны лезть и менять вашу сущность «Сравнивание»?
Подозреваю, что речь идёт о подходе а-ля Rust, в котором будет (псевдокод)
... неважно где...
class Foo<T> {
внутренности класса
}
... где-то ближе ...
impl Compare for Foo<T> {
func less(a: & const T, b: & const T) {
...
}
}то есть оно не оформляется внутри типа и формальная сравниваемость не строится в зависимостях типа, а объявляется вне его.
Она может быть и сразу рядом с описанием типа, и добавлена кем-то со стороны, а увидит её компилятор или нет — зависит от того, какие объявления подключены к этому моменту, не хотим — не подключаем. Объявить Compare для чужого типа, не зная его названия — сложно, для всех сразу — невозможно, поэтому явный абьюз малореален.
Мне этот подход скорее нравится, хотя тут надо бы уточнить ряд особенностей — могу ли я, например, для производного класса запретить, наоборот, такую имплементацию, если ломаю её контракт?
И если в вашей ситуации мы добавляем новый класс, которые должен сравниваться, то мы должны лезть и менять вашу сущность «Сравнивание».
Стандартный полиморфизм по параметру X в impl Compare for X — решает эту проблему.
И когда у какого-то класса вдруг почему то изменилось сравнение, то тоже самое — надо лезть в сущность «Сравнивание» и её менять.
Если автор класса сразу рядом с классом поставил подобную имплементацию — это уже его ответственность.
Если кто-то другой снаружи такое придумал — то это его ответственность следить за особенностями того класса, в сущность которого он лезет своим сравнением.
Тут всё корректно, и даже конфликты должны решаться стандартными средствами их разрешения (давно подточенными под 100500 правил поиска лучшего соответствия при полиморфизме).
На самом деле это вполне естественный сдвиг по сравнению от явного объявления интерфейсов, когда вам надо определить какое-то свойство, которое автору соответствующих типов просто никак не было нужно.
Например, он сделал иерархию животных и выделил базовые свойства — рептилии, млекопитающие, птицы…
А мне нужно определить всех летающих: птицы, но не все; белки-летяги; летучие рыбы; рукокрылые. Я беру отдельный типаж FlyingAnimal и назначаю его применимость к заданным типам по иерархии (причём, если язык позволяет, включаю туда птиц, а потом исключаю страусов, эму, казуаров и дронтов).
В C++ строится подобное, но косвенно (через хаки типа std::enable_if, замусоривающие имя типа и закаменяющие применённое ABI). Во многих других языках и сейчас нельзя.
Другой вопрос, стоит ли от этого отказываться от интерфейсов в принципе. Наличие требования соответствия интерфейсу позволяет уже при компиляции типа (а не его использования) проверить, например, отсутствие реализации затребованного метода (название с опечаткой, сигнатура попутана — да мало ли что). Сейчас я не готов сказать, насколько хорошо решаются эти вопросы новыми подходами.
И ещё очень хорошо надо подумать над бинарной совместимостью. Если есть библиотека, в которую мы передаём просто указатель/ссылку/чтоугодно на Comparable, FlyingAnimal, etc., и её нельзя перекомпилировать под каждое применение — требуются решения, сходные с тем, как в Java для интерфейса, в C++ для базового класса при множественном наследовании...
Она может быть и сразу рядом с описанием типа, и добавлена кем-то со стороны
Но это всё равно уже не
Сущность «Сравнивание» должна уметь принять пару объектов типа User и либо вернуть -1 | 0 | 1, либо вежливо отказаться сравнивать несравнимое.
И опять же чтобы её написать надо знать либо внутренности класса, либое его интерфейс, либо ещё какое-то формальное описание этого класса. Без этого знания вы всё равно Compare не напишите.
Объявить Compare для чужого типа, не зная его названия — сложно, для всех сразу — невозможно, поэтому явный абьюз малореален.
На мой всзгляд проблема скорее не в абьюзе, а в возможной необходимости писать Compare для чужого типа, не зная его названия/содержания.
На самом деле это вполне естественный сдвиг по сравнению от явного объявления интерфейсов, когда вам надо определить какое-то свойство, которое автору соответствующих типов просто никак не было нужно.
Это совсем другая проблема и естественно интерфейсы вроде Comparable и не должны её решать.
На мой всзгляд проблема скорее не в абьюзе, а в возможной необходимости писать Compare для чужого типа, не зная его названия/содержания.
Compare как раз тут, да, слегка проблемный пример. Тип может и не экспортировать необходимые данные для сравнения. Мне кажется, с летающими получилось немного лучше.
Но совсем для неизвестных типов вроде ж никто такое и не пишет?
Это совсем другая проблема и естественно интерфейсы вроде Comparable и не должны её решать.
Тут тот момент, что при наличии таких типажей/протоколов/you_name_it может оказаться, что интерфейсы в классическом виде и не нужны...
То есть в такой ситуации вам нужна какая-то форма «договора», которого будут придерживаться обе стороны. И для меня как раз вот это в первую очередь и является интерфейсом. А как там эти интерфейсы реализованны в отдельных ЯП/фреймворках/ситуациях и какие они там ещё дополнительные функции могут нести это на мой взгляд уже вторично.
А как там эти интерфейсы реализованны в отдельных ЯП/фреймворках/ситуациях и какие они там ещё дополнительные функции могут нести это на мой взгляд уже вторично.
Ну а вся ветка дискуссии как раз посвящена тем особенностям, которые для вас тут вторичны :) но далеко не так в том случае, когда это начинает влиять на реализацию.
Я его не распарсил, а ответить хочется.
:)))
Ну вот буквально в соседнем комментарии. Мне нужен типаж "летающие животные" (предположим игру, где персонаж может улететь от врага через пропасть).
Я знаю, что 99% птиц летают и это осилят (даже какая-нибудь курица, хоть она и не любит летать). Но есть нелетающие: персонаж-страус этого не осилит.
И у меня иерархия типов. Я могу всем птицам раздельно ставить пометку "этот летает", но если я где-то пропущу, пойдут жалобы на нелетающих астрильдов. А могу исключить только мелкие группы действительно нелетающих — но тогда я должен иметь возможность для каких-то типов выключать возможность, которая включена для их предковых типов.
В идеале я ожидаю что-то вроде:
impl Flying for Bird {
// неважно что, важен факт разрешения impl Flying
}
#[prohibited] impl Flying for Ostrich {
}Если такого нет, я или помечаю каждую подветку птиц раздельно (задолбаться и с ошибками), или должен рисовать что-то типа:
impl FlyingCheck for * {
func Flies() bool { return false; }
}
impl FlyingCheck for Bird {
func Flies() bool { return true; }
}
impl FlyingCheck for Ostrich {
func Flies() bool { return false; }
}но при этом проверка усложняется до
impl EscapeByFly for T
when FlyingCheck[T] and T.Flies()
{ ... }
и мы впадаем в C++ с его проблемой, что чтобы скомпилировать, нужно интерпретировать какое-то подмножество языка и во время компиляции проверять constexprʼы.
Ну, вот, жду ответа :)
Но какова связь между Bird и Ostrich? В расте (насколько я знаю) нет наследования типов, поэтому у вас будет просто отдельный тип Bird и отдельный тип Ostrich, с которым ваш Bird никак не может быть связан.
Я упомянул, что у нас иерархия типов. И Ostrich — подкласс (неважно, насколько дальний) для Bird. От Rust здесь только условный стиль.
Ну вот вы это проблемой считаете, а куча людей в том же хаскель-комьюнити (включая меня) спят и видят, как бы сделать это возможным со всеми этими зависимыми типами.
Не понял, что тут "это", расшифруете?
Ну нельзя же просто рассматривать стиль, чтобы и тайпклассы были, и ООП-наследование. Получится скала какая-то, а там своих костылей дофига.
Я не говорю про тайпклассы в вашем понимании — из-за нулевого опыта в подобных языках я уверен, что то, что я понимаю под этим термином на основании просто прочтения публичных док, будет принципиально отличаться от того, что вы видите.
В том же C++ я вполне могу определить, в согласовании со стандартными правилами разрешения полиморфизма, или функцию, которая параметризована типом и вернёт true для Bird, но false для Animal и Ostrich; или структуру, в которой будет функция со свойством; и компилятор будет обязан разобрать такие константные функции и разрешить или запретить соответствующее воздействие:
#include <cstdio>
#include <type_traits>
using namespace std;
struct Animal {
};
struct Chordatum : Animal {
};
struct Bird : Chordatum {
};
struct Struthionida : Bird {
};
struct Ostrich : Struthionida {
};
template<typename> struct is_flying_helper : public false_type {};
template<> struct is_flying_helper<Animal> : public false_type {};
template<> struct is_flying_helper<Bird> : public true_type {};
template<> struct is_flying_helper<Ostrich> : public false_type {};
template<typename Tp> struct is_flying
: public is_flying_helper<typename remove_cv<Tp>::type>::type
{};
template<typename Tp>
typename std::enable_if<is_flying<Tp>::value>::type
makeItFly(Tp&)
{
printf("It flies!\n");
}
int main() {
//printf("%d\n", is_flying<Animal>::value);
Bird animal;
makeItFly(animal);
}
поиграйтесь с типами в main, чтобы убедиться в отказе компиляции при несоответствии требованиям.
Но то, как оно выглядит внутри — вместе со всем C++ — как китайские ёлочные игрушки: не радует.
(Ваш боевой походный комплект экспериментальных языков (а для моего мирка даже Haskell входит пока что туда же), впрочем, не радует с другой стороны.)
И ему не надо ничего у себя там писать или менять или думать как вообще должны сравниваться мои классы.
Кстати, вот это как раз очень часто неадекватно именно потому, что сравнение может быть для разных целей заметно по-разному — тут я согласен скорее с коллегой chapuza@. Методы стандартных библиотек, которые используют сравнение (как сортировка или хранение в дереве), по умолчанию используют некоторый штатный компаратор, но дают переопределение для своих целей — и это неспроста (и не только для изменения на обратный порядок).
Возьмите, например, даты. Для списка дней рождений нам надо сравнивать, выкинув год из учёта.
Встроенное сравнение обычно предназначено обеспечивать только что неидентичные объекты неравны.
Если вам нужны несколько видов сравнения для одного класса, то вам нужно либо несколько интерфейсов для кажой из целей, либо действительно уже использовать «внешнее» сравнение. Для этого в C# существует тот же IComparer интефейс. И этот самый IComparer тоже понимают/поддeрживают большинство библиотек.
Но в подавляющем большинстве случаев хватает одного IComparable.
Причем тут контекст ООП? Что в ООП такого особенного, что у него должны быть паттерны, идущие вразрез с не ООП?
Я разве сказал про обязанность таких паттернов? :) Я сказал, в каком контексте пытался гуглить термин, потому что он явно не из общеизвестных. Вы заводитесь там, где просто не нужно.
Давайте возьмем в качестве примера набивший оскомину Comparable. Сравнение — само по себе сущность, которая, кхм, отвечает за сравнение. SRP решение: описываем type class / protocol, который умеет сравнивать.
Понятно. Тут я согласен с облегчением из-за типажей, но на SRP это не тянет, пока возможность определения свойства должна присутствовать как минимум рядом с определением класса. От того, что вы формально выносите эту роль наружу, только формальные признаки и меняются.
Такой же результат можно было получить, потребовав, например, явного задания имени интерфейса в названии каждой определяемой функции.
Сущность «Сравнивание» должна уметь принять пару объектов типа User и либо вернуть -1 | 0 | 1, либо вежливо отказаться сравнивать несравнимое.
И вы получаете на этом большее нарушение — необходимость выдать этой самой Comparable в доступ (хотя она определена снаружи) внутренности объекта, которые вполне могут быть приватными. Что, friend-ы объявлять?
Вы заводитесь там, где просто не нужно.
Когда я завожусь, я надеваю цилиндр и прыгаю до потолка. Это не тот случай, поверьте :)
От того, что вы формально выносите эту роль наружу, только формальные признаки и меняются.
Отнюдь. Я не выношу «роль» наружу. Я предлагаю писать код так, чтобы модель отвечала за свойства модели, а сравниватель —за сравнение. Сериализатор — за сериализацию. И так далее.
Еще ярчайший пример: Object.hashCode() — как только я захочу в хэшмапе использовать в качестве ключей разные объекты — мне придется идти и смотреть на реализацию самих объектов, а не тайп-класса.
Ну и, я все-таки настаиваю, что вынесение разных ролей за пределы одной сущности — это и есть краеугольный камень SRP.
необходимость выдать этой самой Comparable в доступ (хотя она определена снаружи) внутренности объекта, которые вполне могут быть приватными. Что, friend-ы объявлять?
Изящно, но мимо. Сортировка по чему-то такому, что недоступно извне — за гранью разумного. Это как сортировать Objectы. Не бывает такого, что мне нужно отсортировать по какому-то признаку, но получить доступ к этому признаку мне нельзя, это нежизнеспособный пример.
Ну и это… Вот представьте, что мне втемяшилось сравнивать яблоки и столы. В какой класс: «Apple» или «Table» мне положить правильный компаратор?
А с чего вы решили что Comparable должен применяться для сравнения разных классов между собой? Он отвечает за сравнение объектов одного класса.
Но давайте другой пример. Скажем я пишу ORM, которой будут пользоваться какие-то неизвестные мне люди для каких-то своих неизвестных мне нужд. То есть они просто берут какие-то свои классы, а мой ORM генерирует из них таблицы в базе данных и сам целиком отвечает за работу БД.
И скажем мне чтобы решить использовать Insert или Update надо знать есть у меня уже где-то этот объект или он новый. Для этого мне нужна какая-то функциональность, которая банально сравнивает два объекта произвольного класса и говорит мне идентичны они с точки зрения бизнес-логики или нет. Я такое всегда решал через интерфейс IEquatable. Как вы предлагаете такое решать без интерфейсов?
А с чего вы решили что Comparable должен применяться для сравнения разных классов между собой? Он отвечает за сравнение объектов одного класса.Ну с того, например, что чуть-чуть разбираюсь в CS.
public interface Comparable<T>→ This interface imposes a total ordering on the objects of each class that implements it. — Java8
public int CompareTo(object obj) { if (obj == null) return 1;— .NET
От микрософтов я ничего внятного в документации и не ждал, но поправьте меня, если я ошибаюсь: сравнение с null вот прямо в первом же примере.
И скажем мне чтобы решить использовать Insert или Update надо знать есть у меня уже где-то этот объект или он новый.
Погуглите Upsert, эта проблема решена в XIX веке.
сравнивает два объекта произвольного класса и говорит мне идентичны они с точки зрения бизнес-логики или нет
Я такое всегда решал через интерфейс IEquatable.
Круто, что вам разрешили изменить код, к которому вы даже теоретически доступа не имеете. Либо вы можете обязать ваших пользователей написать вам пол-библиотеки за вас — и тогда вариантов масса. Либо нет — и тогда у вас нет гарантии, что IEquatable имплементирован хоть кем-то вообще.
От микрософтов я ничего внятного в документации и не ждал, но поправьте меня, если я ошибаюсь: сравнение с null вот прямо в первом же примере.
null в шарпах это не отдельный класс. Это грубо говоря просто «пустая ссылка». Более того там ниже по тексту:
This interface is implemented by types whose values can be ordered or sorted. It requires that implementing types define a single method, CompareTo(Object), that indicates whether the position of the current instance in the sort order is before, after, or the same as a second object of the same type.
Погуглите Upsert, эта проблема решена в XIX веке.
Допустим мой ORM должен работать и с базами данных, которые такое не поддерживают. Да и вообще это гипотетический пример для того чтобы показать целый класс проблем.
Круто, что вам разрешили изменить код, к которому вы даже теоретически доступа не имеете.
Кто и где мне разрешил менять какой-то код? Я вообще ничей код менять не собираюсь. Я пишу свою собственную ORM и ставлю условие что для того чтобы использовать с ней какой-то класс, то этот класс должен имплементировать интерфейс IEquatable.
Либо вы можете обязать ваших пользователей написать вам пол-библиотеки за вас — и тогда вариантов масса.
Они вообще не должны за меня ничего писать. Они должны сами для себя решить как должны сравниваться на идентичность их собственные классы.
Может им достаточно одного id для сравнения. А может у них id композитные. А может у них как id вообще используется какой-то их собственный класс. Или им для идентичности необходимо чтобы абсолютно все поля были идентичны.
Откуда я должен это знать когда я пишу своё ORM?
Этот комментарий стал выстрелом в голову самому себе. Я не вижу смысла продолжать что-то объяснять людям, которые в соседних предложениях пишут буквально следующее:
Я [...] ставлю условие что для того чтобы использовать с ней какой-то класс, то этот класс должен имплементировать интерфейс IEquatable.
Они вообще не должны за меня ничего писать.
Ну так а в чём конкретно претензии? Особенно если учитывать что предложенные вами альтернативы с инъекциями и DP имеют точно ту же проблематику.
Они не имеют этой проблематики. И я примерно пятьсот раз это уже повторил и расписал, с примерами, которые вы просто не понимаете.
Претензий никаких нет вообще.
А если вы вашу имплементацию финализировали, отдали кому-то и этот кто-то хочет добавить сравнение для каких-то своих новых классов при помощи инъекции или DP, то он это точно так же должен делать сам. Или вы предлагаете ему в такой ситуации обращаться к вам и ждать пока вы найдёте время сделать это сами?
Так что конкретно в данном аспекте разницы нет ровно никакой.
А с чего вы решили что Comparable должен применяться для сравнения разных классов между собой? Он отвечает за сравнение объектов одного класса.
То есть даже с производным классом сравнить нельзя? По-моему, это чрезмерное ограничение.
Это очень толсто.
Вы мне лично сами пару месяцев тому — демонстрировали мощь хаскеля на примере сортировки разных типов; лень ссылку искать.
Я ожидаю, что если у меня есть дни рождения, национальные праздники, график отпусков и выдачи зарплат, имеющих между собой общего — только то, что они все привязаны к дате — мне дадут их отсортировать по дате.
Kanut вон выше пишет, что в шарпе мне даже не удастся изобрести специальный интерфейс, чтобы сравнивать по нему, все равно придется построить God-объект, который будет сортировать разношерстные коллекции.
В джаве, слава Гослингу, мне хотя бы дадут объявить IHavingDate с методом getDate, и я смогу их отсортировать, если ни одна из имплементаций не забудет про него.
Kanut вон выше пишет, что в шарпе мне даже не удастся изобрести специальный интерфейс, чтобы сравнивать по нему, все равно придется построить God-объект, который будет сортировать разношерстные коллекции.
На самом деле не совсем так. В теории вы можете написать интрефейс IGodComparable, который будет сравнивать любые классы, которые имплементируют интефейc ISpecialComparable. Просто мне сложно представить зачем это нужно.
Любые в зависимости от задачи.
Вот у меня есть например 3 подвида таймеров: однократные, многократные с интервалом между стартами и многократные с интервалом между работами. Но для сравнения мне нужно только время ближайшего старта.
То есть в теории можно сравнивать разные объекты до тех пор пока они все либо имеют один базовый класс, либо имплементируют один общий интерфейс.
Но вот именно IComparable и именно с абсолютно произвольными классами работать не будет.
То есть в теории можно сравнивать разные объекты до тех пор пока они все либо имеют один базовый класс, либо имплементируют один общий интерфейс.
В какой теории? В теории ущербных языков программирования?
Перечитайте самое начало этого треда: интерфейсы — тупиковая ветвь эволюции, придумавшим их людям должно быть стыдно. Они приносят проблемы на ровном месте, нарушают основные работающие принципы CS и вообще бессмысленны со всех точек зрения, кроме «я умею только в один энтерпрайзный язык, и тут так, поэтому это хорошо».
Вы же даже сами чуть ниже расписываетесь в том, что интерфейс не нужен:
К счастью для этого у отдельных классов/типов есть CompareTo [...].В какой теории? В теории ущербных языков программирования?
В теории, обсуждая ситуацию, имеющуюся на данный момент в C#.
Перечитайте самое начало этого треда: интерфейсы — тупиковая ветвь эволюции, придумавшим их людям должно быть стыдно
Я вот пока вижу с вашей стороны кучу критики интеpфейсов, но так и не увидел ни одного конкретного ответа на поставленные мною вопросы. И вариaнтов «безинтерфейсных» решений озвученных мною проблем я от вас тоже пока не увидел.
Так что нет, на мой взгляд интерфейсы это не тупиковая ветвь эволюции. На мой взгляд это вы просто похоже в вашей работе не сталкиваетесь с проблемами, которые решаются при помощи интерфейсов.
Вы же даже сами чуть ниже расписываетесь в том, что интерфейс не нужен:
Это уже какая-то демагогия начинается. Естественно интерфейсы нужны не всегда и естественно не все проблемы решаются с помощью интерфейсов. Но это не значит что интерфейсы не нужны в принципе.
обсуждая ситуацию, имеющуюся на данный момент в C#
Если вы вдруг не обратили внимание, C# сюда принесли и здесь обсуждаете только вы.
так и не увидел ни одного конкретного ответа на поставленные мною вопросы
Потому что вы начали задавать вопросы в этой ветке после того, как я на них ответил вот тут. Там даже ссылка есть.
вариaнтов «безинтерфейсных» решений озвученных мною проблем я от вас тоже пока не увидел
Прям беда. Ваши «проблемы» — это не проблемы вообще, их можно решить и интерфейсом, и отдельным сортировщиком, и как угодно. Но только интерфейсный вариант заставляет пользователей вашего кода писать кучу им не нужного бойлерплейта, чтобы ваша библиотека была способна работать.
На мой взгляд это вы просто похоже в вашей работе не сталкиваетесь с проблемами, которые решаются при помощи интерфейсов.
Ваша правда; ибо таких задач нет. Точнее, не так: такие задачи появляются как искусственные ограничения, поставленные плохо спроектированным языком программирования. Я не пишу на языках, которые вынуждали бы меня постоянно чувствовать себя удаляющим гланды проктологом.
не все проблемы решаются с помощью интерфейсов
Тут ветка, в ветке контекст. Контекст — волею случая — интерфейс Comparable. Простейший, как амеба. Один, блин, метод. Но костылей вокруг пришлось понагородить — районную больницу можно было бы этими костылями обеспечить. ПростоComparambe, ComparambeСВывертом, CompareTo… Удивлен, что нет CompareFrom и CompareInstead.
А всего-то надо было: понять, что сравниваемость ортогональна физическим свойствам и вынести ее в отдельную сущность сбоку.
Если вы вдруг не обратили внимание, C# сюда принесли и здесь обсуждаете только вы.
Вообще-то нет. Про Comparable и, цитирую, «чуть-чуть разбираюсь в CS» начал совсем не я.
Потому что вы начали задавать вопросы в этой ветке после того, как я на них ответил вот тут. Там даже ссылка есть.
Это не отвечает на поставленные мною вопросы и не даёт решения для описаных мною примеров. И как раз поэтому я их вам и задал.
Ваша правда; ибо таких задач нет.
Ну давайте я ещё раз повоторю если вы что-то пропустили или не поняли:
Допустим я пишу библиотеку, которая должна отвечать за сортировку данных. Как мне без интерфейсов сделать так чтобы эта библиотека могла сортировать абсолютно любые сравниваемые типы данных? Причём даже те типы данных, которые появятся после окончания работы над этой библиотекой? И с ошибками во время компиляции, а не во время исполнения?
Тут ветка, в ветке контекст. Контекст — волею случая — интерфейс Comparable. Простейший, как амеба. Один, блин, метод.
Я не вижу здесъ «простейшего как амёба метода». Я вижу пожелания вроде того чтобы этот метод мог сравнивать между собой абсолютно любые типы данных. Чтобы он мог сравнивать по разному в зависимости от контекста. Чтобы он мог сравнивать даже те типы данных, которые пока ещё не существуют. И так далее и тому подобное.
Но если для вас это простейщий метод, то наверняка вам не составит труда показать имплементацию метода, который удовлетворяет хотя бы трём вышепречисленным условиям. На любом удобном вам языке и без интерфейсов.
И с ошибками во время компиляции, а не во время исполнения?
Ух ты, как мы прямо на лету ТЗ-то меняем, любо-дорого смотреть. А ничё, что не все языки — компилируемые?
Я вижу пожелания вроде того чтобы этот метод мог сравнивать между собой абсолютно любые типы данных.
Нет только те, которые хотят сравниваться. Ну да ладно, я и для любых могу (идея позаимствована у Армстронга и Вирдинга) — оператор сравнения работает из коробки для всех типов данных языка:
number < atom < reference < fun < port < pid < tuple < map < nil < list < bit stringДа, это не совсем то, чего вы ожидали. Ну ладно, давайте поближе к земле.
Чтобы он мог сравнивать по разному в зависимости от контекста
ruby, классическая Dependency Injection, пример из моего первого комментария.
def compare o1, o2, comparator = Comparator.def
comparator.(o1, o2)
endЧтобы он мог сравнивать даже те типы данных, которые пока ещё не существуют. И так далее и тому подобное.
Пример поизящнее: map-sort из elixir.
Инъекция кода, изменение AST.
defmodule User do
use Comparable, compare_to: fn
me, %User{} = user -> me.full_name < user.full_name
me, %{id: id} = other -> me.id < id
me, other -> me < other
end
...Ну и, наконец, протоколы.
defprotocol Comparable do
@doc "Returns a term that would be used to compare"
def term(data)
end
...
@spec sort(any(), any()) :: boolean()
def sort(e1, e2) do
case {Comparable.impl_for(e1), Comparable.impl_for(e2)} do
{nil, _} -> e1 < e2
{_, nil} -> e2 < e1
{c1, c2} -> c1.term(e1) < c2.term(e2)
end
endТеперь если какая-то сторонняя сущность пожелает участвовать в конкурсе, от автора потребуется имплементация одного метода из протокола, причем он может как сам ее написать, так и воспользоваться любой существующей.
Ах да, ошибки во время компиляции. Ну, эликсир компилируется, так что всегда пожалуйста: в последнем примере имплементация протокола будет такая:
@compile {:inline, sort: 2}
def sort(e1, e2) do
[e1, e2]
|> Enum.map(&Comparable.impl_for!(&1).term(&1))
|> Enum.reduce(&:</2)
end
Ух ты, как мы прямо на лету ТЗ-то меняем, любо-дорого смотреть. А ничё, что не все языки — компилируемые?
Почему же на лету. Это уже упоминалось в дискуссии. Вы пропустили?
Нет только те, которые хотят сравниваться. Ну да ладно, я и для любых могу (идея позаимствована у Армстронга и Вирдинга) — оператор сравнения работает из коробки для всех типов данных языка:
Меня не имнтересует сравнение для ограниченного набора типов данных. Меня интересует сравнение для вообще всех сравниваемых типов данных.
ruby, классическая Dependency Injection, пример из моего первого комментария.
Это здорово, но откуда ваш comparator знает как сравнивать эти самые о1 и о2? Откуда функция вызывающая comparator знает сколько у него входных параметров и какого типа результат? Это где-то описано или я могу в качестве comparator'a запихнуть всё что угодно?
Пример поизящнее: map-sort из elixir. Инъекция кода, изменение AST.
Откуда я знаю как должен выглядеть инъектируемый код? Сколько параметров он должен иметь? Что возвращать? Это где-то описано? Чем это описание принципиально отличается от интерфейса?
Меня не имнтересует сравнение для ограниченного набора типов данных. Меня интересует сравнение для вообще всех сравниваемых типов данных.
А это вообще все типы данных. Эрланг — функциональный язык, в нем нет «произвольных объектов». Интересует вас это, или нет (на самом деле это только демонстрирует ширину вашего кругозора), — мне фиолетово, не я просил примеров «на любом удобном вам языке и без интерфейсов».
Это уже упоминалось в дискуссии.
В дискуссии между кем и кем? Я не читаю побочные ветки, и вы совершенно не вправе ожидать от меня, что я стану тратить на это время.
откуда ваш comparator знает как сравнивать эти самые о1 и о2?
Вы его передаете при вызове метода. Передайте тот, который знает. А лучше, почитайте что-нибудь про DI в целом.
Откуда я знаю как должен выглядеть инъектируемый код?
Да вам это и не нужно, главное, что компилятор в курсе.
Что возвращать?
Код никому не обязан что-то возвращать.
Чем это описание принципиально отличается от интерфейса?
Тем, что оно — одно из великого множества вариантов, тем, что от модуля, который зовет use не требуется никаких имплементаций, тем, что весь бойлерплейт, если он есть, можно заинжектить.
А это вообще все типы данных. Эрланг — функциональный язык, в нем нет «произвольных объектов». Интересует вас это, или нет (на самом деле это только демонстрирует ширину вашего кругозора), — мне фиолетово, не я просил примеров «на любом удобном вам языке и без интерфейсов».
Это здорово. То есть если кому-то нужны эти самые произволные объекты, то он должен про них забыть только потому что вам не нравяться интерфейсы?
В дискуссии между кем и кем? Я не читаю побочные ветки, и вы совершенно не вправе ожидать от меня, что я стану тратить на это время.
Ну так а я дискутирую здесь не только с вами, но и с другими людьми.
Вы его передаете при вызове метода. Передайте тот, который знает. А лучше, почитайте что-нибудь про DI в целом.
То естъ вы точно так же предлагаете «скинуть половину работы на пользователя»? Подождите, но разве это не было одним из пунктов вашей критики в сторону решения с интерфейсами?
Откуда я знаю как должен выглядеть copmarator? что бдует если я передам функцию с тремя входными параметрами, которая возвращает boolean?
Да вам это и не нужно, главное, что компилятор в курсе.
В смысле мне это не нужно? Я могу инъкетировать абсолютно что угодно и ваш пример будет работать?
Ксатати а что будет если два человека инъектируют две разные имплементации для сравнения данных одного типа? Будет ошибка при компиляции? При выполнении? Будет использоваться первый или последний?
Код никому не обязан что-то возвращать.
Как тогда узнать результат сравнения?
Тем, что оно — одно из великого множества вариантов, тем, что от модуля, который зовет use не требуется никаких имплементаций, тем, что весь бойлерплейт, если он есть, можно заинжектить.
А у интерфейсов нет множества вариантов? Про абстрактные классы вы ничего не слышали? Инъекция в принципе не может работать вместе с интерфейсами?
П.С. И самое главное «простейшего метода» я так и не вижу. Я точно так же вижу достаточно сложную конструкцию, котороая точно так же сваливает кучу работы на пользователя. Да ещё и требует иъекций и/или DI.
Я не пишу на языках, которые вынуждали бы меня постоянно чувствовать себя удаляющим гланды проктологом.
То есть вы правда считаете, что иметь возможность хранить в каком-то одном списке сущности разных типов только на том основании, что у них всех есть атрибут "дата" — это нормально?
Я правда считаю (как и все нормальные люди, не ужаленные хайпом по строгой типизации), что хранить в каком-то одном списке сущности разных типов — абсолютно нормально, даже если у них вообще нет ничего общего.
Так же считают авторы всех column-based и NoSQL баз данных, ивентлогов, мессаджброкеров, любого GUI, включая браузеры, и вообще примерно всего в мире софта, которым люди пользуются, а не показывают на закрытых конференциях для избранных.
любого GUI
А с ним-то что?
С ним то, что любой простой layout — это список, который в подавляющем большинстве случаев умеет разные типы.
С ним то, что любой простой layout — это список, который в подавляющем большинстве случаев умеет разные типы.
Разные типы или абсолютно произвольные типы?
Потому что по моему опыту даже в GUI у всех типов в списке обычно есть либо базовый класс, либо общий интерфейс, либо хотя бы одни и те же методы/проперти.
Мне второй подход симпатичнее, хотя и с тайп-классами это не так убого, как с интерфейсами в ООП.
Ну да, я в курсе, что это можно имплементировать с нуля (причем вообще как угодно). И вообще, в этой конкретной ветке я (как это ни странно :)) вообще не гнал на типы, я всего лишь сказал, что хранить разные типы в списке — нормально.
Но тут, как обычно, выяснилось, что что такое «разные типы» — каждый понимал по своему: от радикального ООП от Kanut
по моему опыту даже в GUI у всех типов в списке обычно есть либо базовый класс, либо общий интерфейс
GTK, так, просто например, — написан на C. Там нет классов и интерфейсов.
до радикального type everything от вас
class Widget a => TextBox a where ...
class TextBox a => TextEdit a where ...А ведь почти все, например, системные утилиты в гуях — чуть ли не рефлекшеном ходят по свойствам того, что им попалось, и достают оттуда все подряд. Так в 95 венде делал EventLog (или как он там назывался) — так в современных линуксах делают графические оболочки для systemd. Чистая магия.
а есть сравнение того, что возвращает условная getStartTime.
Да. Но это как раз то, что нужно в данном случае.
Вы не сравниваете исходные объекты
Ну а для каких объектов может быть сравнение именно "исходных объектов", а не каких-то их проекций, или вообще левых сущностей? По-моему, оно остаётся таким только для целых чисел (и их проекций 1:1, вроде дат). Уже для плавучих мы имеем выбор между ordered/unordered и total.
А дальше? Точки? Можно упорядочивать по ax+by с любыми a и b, а можно ещё и проецировать на квадраты. Работников? По фамилии, имени, отчеству, номеру паспорта, ИНН, дате рождения, в любых комбинациях. Что дальше?
Вы знаете заметные классы (в смысле общего рассуждения) таких объектов, чтобы для них сравнение объектов "в себе" имело важный смысл и превосходило по значимости все альтернативные критерии сравнения?
Э-кхм…
— Верно, — сказал Чапаев, с силой проводя щеткой по спутанным конским волосам, — умею. А потом как дать из пулемета…
— Но мне кажется, — сказал я, — что я и могу.
— Попробуй.
— Хорошо, — сказал я. — Я тоже задам последовательность вопросов о местоположении.
— Задавай, задавай, — пробормотал Чапаев.
— Начнем по порядку. Вот вы расчесываете лошадь. А где находится эта лошадь?
Чапаев посмотрел на меня с изумлением.
— Ты что, Петька, совсем охренел?
— Прошу прощения?
— Вот она.
вот я определил сравнение. Тут — по x, тут — по y, а тут — по порядку установки на карту.
Вот оно, определено.
> или, ну, вот из моего текущего проекта
У меня не скоро будет время грок это всё вот на неосвоенном языке, поэтому, если хотите продолжения дискуссии не через пару месяцев, то расшифруйте.
вот я определил сравнение. Тут — по x, тут — по y, а тут — по порядку установки на карту.
Вот оно, определено.
Ну это же не порядок на самих объектах, а порядок на некоторой их проекции.
У меня не скоро будет время грок это всё вот на неосвоенном языке, поэтому, если хотите продолжения дискуссии не через пару месяцев, то расшифруйте.
Я не Дедфуд, но расшифрую. deriving Ord позволяет автоматически вывести порядок для типа, если для всех его составляющих определён порядок. Сам выводимый порядок является, условно говоря, лексикографическим: два значения этого типа сравниваются покомпонентно в порядке, перечисленном в определении типа.
С какой радости модель должна отвечать за данные, и еще немножко за сравнивание? А что если я хочу научить чужой класс сравниваться? Аспекты, рефлекшн, магия?Если сравнение целиком и полностью определяется данными (т.е. вы уверены, что не возникнет ситуации, когда изменение логики сравнение будет вызвано не изменениями данных), то интерфейс Comparable не нарушает SRP.
Если же есть значимая вероятность, что логика сравнения может поменяться не в связи с изменениями данных, то тут действительно будет нарушение SRP и лучше сделать отдельный Comparator.
Условно: Integer implements Comparable — это ОК. User implements Comparable — скорее всего не ок, т.к. велика вероятность что мы захотим в разных ситуациях сравнивать пользователей по разным полям, и даже сравнение по-умолчанию вполне может меняться без изменения данных.
Integer implements Comparable — это ОК
А потом я решу написать библиотеку, которая умеет неограниченный сверху BigInt, и она будет прекрасна, вот только сравнивать с встроенным Integer мне придется с привлечением бубна.
Я уже прямо чувствую, как в воздухе запахло перегрузкой операторов, кострами, каменными наконечниками стрел и пещерами.
То есть именно в случае с BigInteger именно этой проблемы у вас не будет:)
если мы говорим про Comparable из javaНет, в этой ветке мы говорим о том, что интерфейсы в целом, равно как и Comparable из java, — никому не нужная сущность, появившаяся оттого, что авторы языка плохо умели в проектирование языков.
Джаву и шарп я как раз приводил в пример костыльного, нерабочего решения, к тому же — нарушающего SRP. Если нужно уметь сравнивать объекты только одного типа — даже простой метод на объекте, формирующий то, что умеет сравниваться из коробки (беззнаковое целое, например) — был бы уместнее (и быстрее).
Но теперь я вижу, что у вас просто какое-то свое представление о SRP, ибо как можно аргументируя нарушения SRP ссылаться на рефлекшен, аспекты и перегрузку операторов я не понимаю. Это вообще ортогональные друг другу понятия.
2) Как параллельная разработка влияет? Если вы выделяете код в библиотеку и сторонняя команда её использует, то им нет разницы, SomeCoolManager — это интерфейс или класс. Это бы противоречило сути интерфейсов.
1) У вас ЯП не поддерживает моки классов?
Чтобы сделать мок класса этот класс сначала должен быть в наличии. И как бы если ещё в каких-нибудь юнит-тестах с мока работать более-менее удобно, то в остальных случая не особо.
Как параллельная разработка влияет? Если вы выделяете код в библиотеку и сторонняя команда её использует, то им нет разницы, SomeCoolManager — это интерфейс или класс. Это бы противоречило сути интерфейсов.
Как раз таки разница интерфейс или класс в таком случае очень большая. Потому что если у меня прописан класс, то я могу использовать только этот класс. А если прописан интерфейс, то я могу использовать любой класс его имплементирующий.
И проблема как раз в том что я могу «выделить интерфейс» но не дать никакой имплементации и стороняя команда уже может начинать имплементировать свои вещи ориентиpуясь на этот интерфейс. А я буду параллельно писать свою имплементацию под него.
Потому что если у меня прописан класс, то я могу использовать только этот класс. А если прописан интерфейс, то я могу использовать любой класс его имплементирующий.Это не имеет смысла в контексте существования SomeCoolManager и SomeCoolManagerImpl, который, судя по бессмысленному суффиксу Impl, принципиально единственный наследник интерфейса, кроме моков (но тесты не должны управлять кодом). У класса уже есть интерфейс. Вы можете использовать интерфейс класса SomeCoolManager невзирая на то, есть ли там под капотом имплементация или нет. Клиентский код от этого факта абстрагирован.
Я говорю о ЯП вроде C#, Java, PHP, где где субтипизация только явная. В более структурно-типизированных ЯП с интерфейсами-протоколами как Go, Typescript, это имеет больше смысла.
В остальном, это не особо резонирует с моим опытом. Возможно, в вашей среде это имеет больше смысла (в тех интерфейсах, которые отделяются от основного кода и используются другими). Но, по моим наблюдениям, многие уже издавна стали выделять интерфейсы из классов просто потому что использование интерфейсов вместо классов само по себе ведёт к большей гибкости. Скорее к иллюзии гибкости и бесполезной церемониальности.
Это не имеет смысла в контексте существования SomeCoolManager и SomeCoolManagerImpl, который, судя по бессмысленному суффиксу Impl, единственный наследник интерфейса.
Занчит возможно в данном конкретном случае интерфейс и не нужен. Я же вроде нигде не писал что интерфейсы нужны абсолютно везде и всегда.
Возможно, в вашей среде это имеет больше смысла (в тех интерфейсах, где смысл есть). Но по моим наблюдениям люди уже издавна стали выделять интерфейсы из классов просто потому что это использование интерфейсов сама по себе ведёт к большей гибкости.
Ну лично у меня «внутри» проектов/библиотек/модулей интерфейсы используются редко. Но тут каждый сам решает для себя что ему удобнее.
Банковское приложение
Калькулятор
Программа для распознавания растений
Мобильный планетарий
мой список
1./2./3./4. и 7. — да
Для создания заметок использую OneNote, он сейчас отлично синхронизируется с десктопной версией, а возможностей у него выше крыши.
Из неупомянутого — офис (в основном — просмотр документов), сканирование/распознавание, почта, калькулятор, мобильная точка доступа, читалка, погода, банковское приложение, фонарик и казуальные игры.
Калькулятор, фонарик и погода — согласен
По роду работы есть необходимость сканировать и распознавать фрагменты текста.
Наиболее удобный для этих целей инструмент — смартфон.
По востребованности у меня это фича номер один (после основных функций телефона, естественно :) А уже намного потом — калькулятор, фонарик и погода.
Я пользуюсь смартфоном чтобы писать сообщения (не дома), листать ленты в соцсетях, пока чего-нибудь жду (не дома), фоткать, слушать музыку в метро, вызывать всякие такси, изредка звонить. Для меня это по большей части именно коммуникационное устройство. Если я и делаю с него что-то другое, то только от безвыходности. Сама идея использования телефона дома, где у меня есть более подходящие устройства, мне кажется дикостью. Если у меня в телефоне не будет вайфая, я это даже не замечу.
Современные телефоны оптимизированы под юзкейсы, которых у меня просто нет.
Запускаю ютуб раз в полгода, когда кто-то что-то скидывает посмотреть.
Искренне не понимаю, как можно смотреть ютуб и сериалы с телефона, когда есть нормальный полноразмерный монитор.
на голове (и смартфон вставлен в них)
В слове "телевизор" много ошибок. Смотреть что-либо из видеоконтента гораздо удобнее с 1.5м+ телевизора.
это же пережиток прошлого — времени, когда IDE не умела их подсвечивать. Теперь умеет, префикс летит на свалку истории.нейминг должен быть нормальным без IDE, и тут дело не в телефонах
Что реально печалит — это попытка сэкономить на реальной разработке под десктоп под видом «унификации внешнего вида». Когда пытаешься установить десктопное приложение, и понимаешь, что то, что ты поставил — сбитое в кучку то самое мобильное приложение с минимумом функциональности, добитое Электроном с целью запуска на десктопе. Когда понимаешь, что полная функциональности и настроек различного уровня сложности понимания и кастомизации Панель управления, существовавшая в Windows с 1993 года, вымирает и заменяется свистоперделками из «Настроек», не имеющих и десятой части того уровня кастомизации, который был доступен раньше.
Да, порог вхождения в смартфоны и современные ПК понизился, и новая аудитория — уже не те энтузиасты, которые были готовы разбираться со всем подряд на протяжении 30 лет. Понимаю, что тренд на упрощение не просто так появился. Но общий подход «пользователь — дурак, мы сами за него все порешаем» уже лет 7-8 как заставляет меня грустить…
А еще — хотите оставить минимум функциональности, так оставляйте, хрен с вами. Но, черт побери, зачем, зачем на 4к экраны размером 28-32 дюйма тащить интерфейсные решения, принятые для 5.2'' смартфонов? Почему нельзя пользоваться API, обеспечивающими стандартный вид, соответствующий операционной системе?
Присел на лавочке в парке, повесил виртуальный монитор перед собой, раскладная клавиатура на колени и в бой.
, что через 10 лет мы будем надиктовывать код голосом.
Такие прогнозы делались с конца 90х, а воз и ныне там :)
При этом все что бы сейчас назвали компьютером/планшетом/etc — называется «AI» и имеет и голосовое управление (и часто только его), если вычислительный блок (возможно удаленный) реально мощный — то там далеко не Алиса по интеллекту.
На счёт кода не знаю, т.к. человек не машина, но мысленный набор плюс выделение кода по взгляду(для копирования/исправления), могут заметно поднять скорость работы.
А голосовое управление/набор текста уже сейчас показал свою без перспективность, как минимум в виду того что слышат другие.
вовсе нет. Просто программирование схлопнется к прокладкам типа ардуино и Qt. Выбираешь нужные лего-кирпичики, соединяешь — гарантированно работает. Программист станет, в сущности каменьщиком. Да, останутся любители "повырезать по дереву" но это только ради творчества.
В VR на природе действительно мало смысла, мне кажется, но на природе меньше стенок, в которые можно невзначай влететь носом. Вернее, до них расстояние дальше. И свежий воздух, неровная земля под ногами.
Но для VR это больше неудобства, а вот для AR — хлеб, ибо за него можно зацепиться и прятать монстров за деревьями. Или порталы шейперов рисовать. Но до этого пока прогресс не дошёл, увы. Может, лет через пять-десять начнёт выходить что-то более массовое.
Кстати, в Valve Index поддержку AR завезли под названием Passthrough. Ещё б его в Россию завезли...
Учитывая сколько денег они в это вбухали и их подход к пользователю, устройство может очень даже выстрелить.
VR тоже для бизнеса и развлечений. Но у него своя параллельная ветка развития.
Можете начинать приобщаться: https://github.com/SimulaVR/Simula
Не знаю, удобно ли тыкать пальцем в виртуальные кнопки AR, но в такой материал — вполне неплохо.
О, вы напомнили мне об отдельной боли в современных смартфонах. Когда телефоны были 3,2 — 4 дюйма, в андроиде дефолтные выезжающие шторки слева и функциональные кнопки приложений в верхней части экрана казались нормальным — ведь я мог дотягиваться до любой точки большим пальцем спокойно. Но когда смартфоны стали 6+ дюймов — неужели кому-то это кажется удобным (кроме, может быть, левшей))?
Зависит от руки и от телефона, но в общем-то можно.
У некоторых смартфонов с большими экранами есть даже "однорукие режимы" в том или ином виде.
А ведь каких-то 10 лет назад его 4,3 дюйма называли огромными и неповоротливыми
В 2000 году телефоны становились все меньше и меньше — и это считалось прогрессом.
Прогресс дошел до предела, при котором уже и держать аппарат стало неудобным, оттолкнулся от него и пошел в обратную сторону.
Возможно, прогресс идет по дуге, и через поколение начнется новый цикл миниатюризации :)
Да и начиналось то всё с реально огромных кирпичей.
Размер снова стал увеличиваться когда пошли фичафоны с графическими дисплеями, камерами. Сейчас размер диктуется исключительно дисплеем, уже и так все рамки порезали. Будет что-то в замену дисплею, тогда и может быть начнётся миниатюризация.
Хотя надо вспомнить ещё аккумулятор.
Будет что-то в замену дисплею
Возможно, телефон будущего будет напоминать предпоследний айпод шаффл? :-)

В 2001 году я купил в подарок человеку Samsung SGH-A400 — это был самый маленький телефон среди моих покупок.
(В те времена Нокия 7110 выглядела Гулливером в стране лилипутов)
Моя большая Motorola Timeport T280 была заменена на Motorola V60, затем последовал ряд компактных аппаратов до Nokia E51 включительно — цветные графические дисплеи уже были, но телефоны все еще оставались компактными.
И даже Nokia E66 (2008), как и HTC P5500, все еще оставались достаточно компактными.
А вот с 2009 года — понеслось, и первым аппаратом, пошедшим в рост, у меня стала Nokia N97…
Будет что-то в замену дисплею, тогда и может быть начнётся миниатюризация
Прогнозы — дело неблагодарное, особенно технические — но могу предположить, что будущие смарты обретут возможность проецирования изображения на любой будущий монитор/телевизор без каких либо особых усилий со стороны пользователя (и, конечно же, без проводов).
Равно как и возможность такого же по комфорту подключения клавы и мыши. При этом их мощность позволит их использовать вместо ПК, да и софт, возможно подтянется (у меня смарт с поддержкой Continuum, это была великолепная идея, правда, слегка опередившая свое время — док-станция там явно лишняя, да и с софтом проблемы).
И такие смарты снова станут компактными :)
Да, и по поводу «а как тогда читать/играть в транспорте?»- в каждую спинку сидения будет вмонтирован мониторчик дюймов в 12", с компенсацией тряски на дорожных ухабах :)
В 2000 году WAP уже был, но на размерах экранов это еще не отражалось.
WAP всё же был ещё довольно гиковской штукой в те времена. Хотя существовали вот такие аппараты:

Вся SMSка на 160 символов влезала на экран.
А насчёт самых маленьких да, как раз ими были раскладухи.
Хотя существовали вот такие аппараты:
Это еще на пути туда — от больших к маленьким.
В 2003 у меня был вот такой мотор:

Очень компактный. (Там даже фотокамера была тогда, когда ее нигде еще не было — реально первый серийный модульный телефон :)
Но при этой компактности — на его экране вполне можно было читать тексты.
Так не нужен такой дисплей. 3-4 дюйма с лихвой мне бы хватило.
Можно. iPhone SE например.
Если в WOT не играть и сцены не рендерить конечно.
Посмотрите на старые версии программ https://www.my-old-version.com, посмотрите на новые и просто ужаснитель, это вроде как прогресс, только совершенно наоборот. Была программа 3 MB, спустя 10 лет 3000 MB, только с меньшим функционалом и интерфейсом из 2 окон.
Я иногда смотрю на все это и говорю сам себе, ну как это возможно? И зачем? Были люди, были программисты… был старый добрый комбайн Winamp… а сейчас какая то простая поделка в веб браузере, которая ничего не умеет. Зато работает на всех платформах, в том числе на холодильнике и старальной машинке.
Но, черт побери, зачем, зачем на 4к экраны размером 28-32 дюйма тащить интерфейсные решения, принятые для 5.2'' смартфонов? Почему нельзя пользоваться API, обеспечивающими стандартный вид, соответствующий операционной
Так дешевле. А пользователи не особо пищат (и все равно пользуются)?
Я сказал — погодь, но это же пережиток прошлого — времени, когда IDE не умела их подсвечивать. Теперь умеет, префикс летит на свалку истории
Прям вижу как вас поддержали пользователи vim'ов, и прочие товарищи которым не нужны аугменты для понимания чего творится в их собственном коде. Не задумывались, что лид потому и лид, что понимает код без IDE смотря его с телефона?
Предлагаю заодно избавиться от ограничений текста по ширине, ведь IDE умеет его рисовать красиво даже в таком случае.
Я вообще мелкие экраны не люблю, какой смысл ужимать код в 80 строчек, когда монитор 28"?
И про vim/nano, консоль растягивается на любую ширину как захотите, вы ж не с ЭЛТ надеюсь, смотрите? :)
"Я вообще мелкие экраны не люблю, какой смысл ужимать код в 80 строчек, когда монитор 28"?"
Чтобы подшипники и сервоприводы в.глазах не уставали за 6 часов смотрения из стороны в сторону...
Очевидно — чтобы смотреть код в сплитах и sbs диффах в шрифтах от которых не вытекают глазки. Про 3-way merge я уже молчу, тут всё равно дисплей меньше 27" подходит плохо если хочется ещё какой-то контекст наблюдать.
Ох, это вообще первое, что меня отталкивает от C++
Что файл не открой — надо закрывать split-view, скакать между табами и пытаться держать «в кэше» SomeUniqueNamespace::VeryPowerfulClassName::ETC
Не все среды что-то дорисовывают. Атавизм ли это, или упражнение на подумать(и как записать и как почитать) это вопрос философский. По себе могу сказать, что последние n раз лазил по незнакомым кодовым базам даже не прикручивая к виму ни семантических подсветок (та самая автодорисовка буковки I) ни даже навигации по коду, хотя, оно всё есть и даже более чем сносно работает. А иногда и ужос ужос, прямо на житхабе получалось всё что нужно высмотреть:)
Учитывая, что код тех проектов писался профессионалами, я практически не заметил разницу, дискомфорта — точно не испытал. А если какой-то код на знакомом языке(что зачастую нынче редкость для многих представителей), плохо читается в таком виде, то он и в IDE хорошо читаться не будет особо долго.
Хм, я точно не в том ключе понял вашу изначальную мысль.
Я вот как на это смотрю — есть код, есть штуки которые к нему дорисовывают и докидывают дополнительную инфу. Код написанный тем кто видит всю эту "дополненную реальность" — зачастую читать намного сложнее без неё, чем код не полагающийся на инструменты отличные от текста и выразительных средств языка.
Это разница примерно такого уровня, как когда читаешь текст и видишь в нём ошибки, по сравнению с тем, когда пишешь текст в текстовом процессоре и ошибки подсвечиваются. С одной стороны — количество ошибок в тексте написанном в процессоре будет ниже, но это про ошибки контекста 1-2 абзаца. С другой стороны, грамотный человек со знанием языка — избежит большую часть локальных ошибок, и скорее всего — построит текст ощутимо лучше за границами контекста доступного инструментам, т.к. протезы пока-что не настолько совершенны.
Т.е. под аугментами я подразумеваю именно те инструменты и технологии, которые "позволяют неподготовленному человеку под 300кг веса бежать со скоростью хорошего спринтера".
Правда — тут непонятно где провести грань, например можно считать, что подсветка синтаксиса это такой же аугмент, как и интерактивные текстовые редакторы. Лично я для себя разграничиваю так — если мне сложно назвать незаброшенный авторами инструмент, где этот уровень поддержки не обеспечен — это можно уже принимать как данность, в противном случае это протез в стиле киберпанка.
В общем и целом тема в принципе лежит на опасной грани к философствованиям, и точно в области субъективных оценок. Я рассказал, что подразумеваю под аугментами, дальше конструктивный спор как построить не вижу если честно, т.к. могу как согласиться с вашими замечаниями, так и спорить:) Все мои субъективные оценки говорят, что кодовую базу написанную не в IDE(хотя бы ядро) читать и вообще поддерживать приятней, может это просто так попадалось, или приятней лично мне.
Единственное чего может добавить контекста к моим высказываниям это:
Я году в 2008-м тоже думал (и кое-где громко говорил), что интеллисенс для моего кода на плюсах — не нужен и от лукавого, и вот я сижу в виме и мне норм. А потом оказалось, что интеллисенс — это удобно. Автоматическая вставка нужного #include — удобно. Переход к определению символа или поиск всех его использований — это удобно (особенно со всякими там перегрузками, когда грепа не хватает). Это всё повышает мою продуктивность. Стал ли я от этого хуже как специалист? Вряд ли.
Я тут скорее с обратной стороны заходил, в том плане что как раз лет 5 назад ещё активно хвалил интелисенс и говорил старшим разработчикам(не в одной команде и не в одной компании) — вот вы дураки в своих блокнотах сидите:) На что они говорили — "ого, и правда крутая штука", однако — почему-то продолжали сидеть в блокнотах. Потом и я как-то плавно пересел — мне просто стало влом сначала настраивать, потом запускать(иногда), а потом и ставить ide, тем более к тому моменту мой вимовский конфиг стал более менее работоспособным после адаптаций на конфигах и одноразовых скриптах. Сейчас я иногда и части своего конфига перестаю использовать. Т.е. у меня какая-то обратная деградация происходит :) Стал ли я как специалист лучше? Хочется верить...
в инстаграме нельзя было регистрироваться с десктопа
Я useragent в браузере на десктопе поменял на мобильный и зарегистрировался.
До сих пор UA для инстаграма в Firefox стоит мобильный
user_pref("general.useragent.override.instagram.com", "Mozilla/5.0 (Linux; Android 6.0.1; SM-G532G Build/MMB29T) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.83 Mobile Safari/537.36");Можно фотографии публиковать, что вроде как с десктопа тоже «нельзя».
Можно просто открыть мобильную версию через консоль разработчика.
Да и объяснять родителям как пользоваться консолью разработчика — то ещё удовольствие.
Я столкнулся с проблемой, что не могу управлять своими банковскими делами, если забыл где-то телефон. Ну то есть, какого черта? Я сижу за своим компом, авторизованный и валидный, но мне нужен телефон, чтобы получить доступ к личному кабинету в банке.
Ну для банкинга «десктопные» или точнее «не смартфонные» варианты тоже есть. Просто обычно тогда надо ещё какой-то дополнительный «хард» покупать. Какие-нибудь security usb sticks или там smart card reader.
У меня одно время вот что-то вроде вот этого было:

У нас для онлайн-бэнкинга обязательна двухфакторная аутентификация. Причём смски и листы с TAN'ами определили как "потенциально опасные".
То есть сейчас надо либо смартфон, либо какой-то дополнительный хард.
Для входа в ЛК нужно смс… Во многих...
Попробуйте подключить систему быстрых платежей в Сбере или в Альфе.
у меня самсунг ноте 10.1 сижу на нём из-за стилуса.
очень удобная штука.
Когда мой Windows Mobile девайс с диагональю 3" приказал долго жить, и я перешел на какой-то Android с бОльшим экраном (4.7"), мне было неудобно. Я очень страдал без стилуса. Набор текста стал более удобным, чем на крошечном резистивном экране только когда купил 6" лопату.
У меня самсунговский планшет со стилусом. Вместо блокнота его постоянно использую. Ваших проблем из нулевых на нем не наблюдается.
Так что если хочешь запрыгнуть на следующий паровоз, прыгать надо сейчас.
Рано, пока что смарт-очки это громоздкий девайс с монохромным экраном 160х160, и про какой-то рынок софта говорить не приходится. С нейроинтерфейсами вообще довольно глухо.
Вот VR довольно перспективно, хотя ниша тоже довольно узкая.
Потому что есть вероятность, что какая-то фирма пилит революцию в гараже и скоро допилит. А мы смотрим что в магазине на полке стоит.Большой вопрос КОГДА допилит. Потому как жизнь человека весьма ограничена во времени, и делать ставку на то, что может выстрелить (а может и нет) лет через 20 очень рискованно.
Для примера: первые шлемы виртуальной реальности еще в 90-х были, причем не в единичных экземплярах у спец.служб, а уже в продаже. Прошло больше 20 лет, а МАССОВОЙ технология так пока и не стала.
Для примера: первые шлемы виртуальной реальности еще в 90-х были, причем не в единичных экземплярах у спец.служб, а уже в продаже. Прошло больше 20 лет, а МАССОВОЙ технология так пока и не стала.
До тех пор пока экран в этих шлемах не сможет конкурировать с нормальным монитором по пикселям — оно и не станет.
А оно не конкурирует и еще долго не.
Для массы такие шлемы не делают, т.к. вычислительные мощности типичного домашнего ПК не готовы к такому, не говоря уж про мобильный рынок.

- Системные требования: для комфортного vr нужны стабильные 90-120 FPS, иначе начнётся адова тошниловка.
- Малое количество нормального софта: для vr практически нет нормальных приложений, в которых бы можно было что-то полезное делать. В основном есть только игры, да и те в большинстве случаев кривые порты с десктопа, и под кривыми я имею ввиду кривизну геймплея. Ибо какой должен быть UX/UI для vr никто толком не понимает. Да и с делать приложения для vr банально сложнее.
- Низкая распространённость vr: кто-то не берет vr потому что дорого, кого-то отталкивает тошнота на этапе освоения, кто-то просто не находит интересующих его приложений, у кого-то тупо нет места под площадку под vr, а для кого-то vr физически тяжел, в конце концов, стоять и держать руки постоянно на весь совсем не тоже самое что сидеть в удобном кресле за десктопом
Как мне кажется, самая большая проблема — это вторая, если ее решить, то появятся и более дешевые шлемы, и менее требовательные к расположению датчики.
В общем, технология у нас уже есть, а вот понимания что и как с ней делать — нет.
Я не старый бубнящий дед, который не может принять, что все меняется. Потому что я блин прав. Со сложным и многофункциональным ПО лучше работать с десктопа.Нет, он старый бубнящий дед, который не представляет, что можно с пользой тратить время, когда вынужденно оторван от десктопа. Каждый раз, когда я вижу человека, который не представляет себя в иных ситуациях, кроме просиживания задницы перед монитором, это именно старый бубнящий дед.
И ладно бы этот старпёр создавал неудобства лишь себе, плохо то, что он, зачастую, создаёт их остальным.
Пример, в Википедии есть участник, который пишет классные статьи, но любит расставлять в них пояснения, всплывающие при наведении на текст курсора мыши. То, что у большей части читателей курсора нет, он не думает и не пытается поставить себя на их место, ведь у него самого курсор есть. Ещё он любит принудительно расставлять примечания к статьям в две колонки вместо того, чтобы позволить движку вычислять кол-во колонок исходя из размера экрана посетителя.
Есть и «обратное старпёрство» — «у меня на 4K-мониторе всё шикарно, а остальные пусть как хотят», когда человек использует слишком новую технологию, игнорируя тот факт, что большинство пользователей пока отстаёт.
Мне кажется, в первом случае это косяк самого движка, что он не предоставляет какого-то мобильного интерфейса к всплывающим подсказкам.
З.Ы. Ну и я правильно понимаю, что какой-то человек, который добровольно и бесплатно тратит свое время и силы на создание хорошего контента, но делает это как-то неправильно и неудобно вам? Такой добровольный труд (также, как Open Source и подобное) не обязан удовлетворять чьим-то хотелкам, даже если это некие "большинство пользователей". Этот человек не обязан быть экспертом по UI/UX и иметь представление о количестве аудитории, использующих те или иные девайсы.
Это неуважение как к читателям, так и к своим же коллегам. От человека не требуется быть спецом по дизайну. Требуется умение не вставать в позу «Я автор, поэтому буду писать красным по жёлтому и блокировать попытки сделать этот текст более читаемым».
Пример, в Википедии есть участник, который пишет классные статьи, но любит расставлять в них пояснения, всплывающие при наведении на текст курсора мыши.
И он всё правильно делает — это гораздо удобнее в нормальных интерфейсах, чем традиционный неудобный книжный подход со сносками внизу страницы или даже в конце документа. Вы же, если выбрали заведомо убогий интерфейс, так и требуйте с его авторов конвертации всплывающих в это ретроградство бумажных книжек, но нефиг прогрессивным людям запрещать. На xkcd всплывающие — вообще одна из фишек.
Деды, на самом деле — это пользователи мобил, поскольку тыкать пальцем в состоянии и обезьяна. Для творца и человека будущего подход нонешних мобил — прошлое.
На мобильных пользователей забьем, на слабовидящих и слепых тоже забьем, недостаточно они прогрессивны, чтобы читать текст Великого Автора. А нефиг быть слепым! Мне это напоминает, к сожалению, ситуацию с колясочниками в России. Люди, побывавшие, например, в Европе, удивляются, сколько там на улицах колясочников. А это не потому, что в России колясочников меньше. Это потому, что они дома сидят. Ведь если лестничные пролеты не оборудованы рельсами для коляски (я такие только на картинках видел, в наших хрущевках тут их нет, а колясочники есть), то хрен куда человек без посторонней помощи спустится. А творцам этих домов зашибись, у них ноги есть. И вообще, ногами ж удобнее, чем на коляске
лежит со смартфоном.
Отлично, старость передаёт обезьяне из будущего привет болезнями. В постели перед сном сёрфить вредно, ложиться спать следует иначе, любой врач подтвердит.
На мобильных пользователей забьем, на слабовидящих и слепых тоже забьем
Взаимоисключающие параграфы. Инвалидам мобилы как раз НЕ удобны — что может быть удобного на маленьком экране, который и слабовидящему видно плохо, и для слепого выпуклостей шрифта Брайля не имеет?..
Ответа же по существу по мобильным интерфейсам и сноскам не было, только нелепые ассоциации на инвалидов. Даже PALM со стилусом и то вменяемее был, чем предлагаемое "не забьем".
Взаимоисключающие параграфы. Инвалидам мобилы как раз НЕ удобны — что может быть удобного на маленьком экране, который и слабовидящему видно плохо, и для слепого выпуклостей шрифта Брайля не имеет?..Что-то вы только про инвалидов по зрению думаете. И совсем не думаете про людей частично парализованных.
Можете прикола ради посмотреть как это действительно работает в реальном мире.
Если серьезно, то и смартфон, и планшет, это устройства для потребления контента. Смотреть, читать, скроллить, не вопрос. Но попытаться набрать на нем хотя бы больше 3х предложений текста — мрак и ужас, все же анатомические ограничения homo sapiens никто не отменял. Даже на планшете с достаточно большим экраном я не могу набирать тексты также быстро, как вслепую на клавиатуре.
Ну а по сути верно, десктопы становятся нишевым устройством для профессионалов, просто полистать что-то планшета вполне хватает, для несложного текста или графики пойдет что-то типа Chromebook, десктоп остается для реально «тяжелых» задач с которыми ноутбук не справится. В казуальном рынке смартфоны рулят, а вот в офисах людей со смартфонами вместо лептопов ни разу не видел :)
Но попытаться набрать на нем хотя бы больше 3х предложений текста — мрак и ужас, все же анатомические ограничения homo sapiens никто не отменял.
Поэтому «племя младое, незнакомое» вовсю пользуется голосовым набором текста и вообще голосовыми сообщениями :)
В том же Android есть распознавание речи от гугла. Правда, не всегда хорошо работает, а знаки препинания приходится продитктовывать, словно в телеграмме.
Контактик умеет уже.
Вот удивительно, что голосовым набором мало кто пользуется. Есть на обеих платформах много лет, встроенный, кнопка с микрофончиком прямо в поле ввода — а вот нифига не зашёл.
Да — для инвалидов по зрению это критично.
Где-то в довольно узких нишах — тоже хорошо бы: я например автомобильному навигатору точку назначения задаю голосом, даже если прямо сейчас не нахожусь в движении, не управляю автомобилем.
А в остальном — ну зачем он нужен?
Находишься ты в общественном месте — будешь что-ли диктовать что-то в мессенжер?
Или сидишь в кабинете на работе — тоже будешь бубнить что-то, вместо того, чтобы набрать текст?
Но при этом все используют именно голосовые сообщения, хотя для получателя зачастую текст удобнее — опять же, сужу не по своему опыту, а по количеству жалоб на любителей голосовух. И при этом возможность превратить голос в текст есть прямо на входе, системная, гарантировано у всех. И довольно неплохо работающая.
Но ей не пользуются, более того (вот это уже пока гипотеза, проверенная только коридорно) — не знают или не замечают. Вот это — проблема. И локальные решения на уровне отдельных приложений её только усугубляют.
Печатаю 1000 знаков в минуту но такая… выходит…
Из личного опыта написания комментариев на Хабре (без голосового набора но с автозаменой) особенно с учётом отсутствия возможности редактировать в мобильной версии...
Как раз набором не пользуются. Хотя могли бы уже довольно давно. Во всяком случае для привет-пока на русском.
С другой стороны старпёрам и скобочки достаточно выразительны))), а молодёжи не то, что эмодзи, а уже стикеры подавай.
Получается, что голосовые сообщения это не просто текст, а ещё и звуковой "стикер" и решением тут будет не ещё более точное распознавание, а какой-то интерфейс субтитров с сохранением оригинальной записи.
вовсю пользуется голосовым набором текста и вообще голосовыми сообщениями :)
И потом в этом месиве сообщений хрен чё найдёшь: поиск-то не работает, а у неё, изволите ли видеть, ногти :/
Если вы его к ноутбуку подключает, то да. При прямом подключении к монитору такого быть не должно.
У меня клавиатура с trackpoint, которая подключается по Bluetooth — никаких лагов. На 4pda и reddit тоже про лаги не помню чтобы читал. Я так понял, что подключаете через хаб. По проводу или радио? Возможно дело в хабе или самих клавиатуре и мыши.
В моем случае декс работает и без подключения зарядки. Но мой "хаб" — только порт зарядки да hdmi. Возможно, у вас к нему много устройств подключено и тупо не хватает питания.
но был жутко разочарован уровнем самого софта.
Смотрел месяца 3 назад обзор на тему dex-подобных конвергенций, пока лидером выглядит как ни странно решение от huawei, несмотря на то, что его пиарят гораздо меньше чем решение от samsung.
Вообще мне нравится движуха которая сейчас происходит в проекте UBports. Похоже ребятки отошли от того, что canonical их выгнала на мороз. Так-что не исключенно, что всякие pinephones неожиданно быстрее окажутся для этого сценария использования более привлекательными. Это с прицелом на то, что гугл портировал flutter под gnu/linux, а snap по функционалу уже практически догнал андроидовские песочницы. Ну и другие мобильнориентированные проекты типа MaruOS и KDE Mobile тоже вполне себе живут поживают и даже продаются уже на реальных, и что важно — новых устройствах.
Вообще — сам в предвкушении когда вместо ноута можно будет мобилку полноценно прицепить. Хотя применительно к хедпосту это тот ещё оффтоп всё.
Вообще — сам в предвкушении когда вместо ноута можно будет мобилку полноценно прицепить. Хотя применительно к хедпосту это тот ещё оффтоп всё.
у меня были надежды на motorola atrix lapdock, потом планшетофоны от асус, потом Nextdock и всякие dex. Сейчас надежда на яблоки. Возможно они сделают что-то достойное.
Если честно, то мне больше нравится идея, что сам вычислительный модуль будет не в мобилке, а десктопе. Мобилка же будет в роли контейнера для данных. Что-то типа liveCD или запуска венды с флешки, но без ожидания загрузки и тд.
Смотрел месяца 3 назад обзор на тему dex-подобных конвергенций, пока лидером выглядит как ни странно решение от huawei, несмотря на то, что его пиарят гораздо меньше чем решение от samsung.
А можно ссылку? (и если есть собственный опыт — то комментарии). Интересно чем это EasyProjection так уж сильно лучше Dex?
Вот.
Даже на планшете с достаточно большим экраном я не могу набирать тексты также быстро, как вслепую на клавиатуре
А репортёры — могут. Посмотри любую прессуху: сидят и набирают :)
купил планшет с Windows 8. Честно попытался его использовать, разочаровался, купил к нему клаву с мышью, и превратил в ноутбук.
Windows 8 вообще, в целом, можно считать экспериментальным проектом — вполне рабочим, но заполненным множеством разных не до конца продуманных вещей.
Этакой предварительной версией 10.
В те времена я активно использовал 8, и тоже подумывал о планшете с ней.
Но то, что тогда было в продаже — на нормальный рабочий конфиг не тянуло.
Пока не появился Surface Pro, уже с 10.
И вот на нем все фичи, появившиеся в 8 — таки заработали.
А в остальном -я полностью разделяю точку зрения автора, но настроен куда менее пессимистично — даже самые упертые фанаты смартов пересаживаются за обычный ПК — как только появляется задача сделать что-то реально сложное.
Да и вообще вся десятка была шагом назад в данном плане.
Потом более-менее допилили, но не один год потратили.
Всё равно он и близко не подошёл к Metro FireFox (последняя версия — 27b4), я не обновлялся до 10 и более свежего FireFox до последнего.
Я не старый бубнящий дед, который не может принять, что все меняется. Потому что я блин прав. Со сложным и многофункциональным ПО лучше работать с десктопа. У меня тут сотня клавиш, два здоровых моника, мышь, джойстик и даже дурацкий тач. Это, мать его, самый продвинутый и современный инструмент для работы с программами. А все сделали вид, что компы, и сложные программы — устаревшее говно, а будущее за дурацкими приложеньками на пол экрана.
Все намного проще. Никто не делал никакого вида. Просто люди тупые и это факт, а смартфон проще чем ПК. Людей которые пользуются ПК и предпочитают ПК меньше не стало, просто айти «образованным» и могущим через интернет что то сделать сейчас может стать реально любой у кого хватит извилин двигать большим пальцем. Это не ПК, где есть конфигурации, разные интерфейсы, сложные программы, шорткаты, знания особенностей его работы и настройки, огромная клавиатура и мышь — это телефон. В телефоне всего три кнопки, из них 2 вообще отвечают за громкость, а из манипуляторов только палец. Нас не стало меньше, нас просто размыло гигантской массой народу которые благодаря нижайшему порогу входа получили доступ к цифровым благам.
Апофеозом деградации я лично считаю свайп клавиатуры. Казалось бы ну невозможно сделать интерфейс более простым чем палец. Но казывается можно, вместо того что бы тыкать пальцем в клавиатуру (на ней ведь так много кнопок и целиться нужно) просто елозь пальчиком по экрану тупо*б. А во вторую лапу банан возьми, раз уж ты ее освободил.
Апофеозом деградации я лично считаю свайп клавиатуры. Казалось бы ну невозможно сделать интерфейс более простым чем палец. Но казывается можно, вместо того что бы тыкать пальцем в клавиатуру (на ней ведь так много кнопок и целиться нужно) просто елозь пальчиком по экрану тупо*б. А во вторую лапу банан возьми, раз уж ты ее освободил.
Действительно. Клавиатуру у смартфона надо делать максимально неудобной. Чтобы пользователи мучались. А то понимаете ли хотят они как проще…
П.С. А заодно и мышки с тачпадами у пользователей ПК/нотебуков отобрать. А то ведь и они могут «за бананом начатъ тянуться». Неее, только консоль, только хардкор :)
Апофеозом деградации я лично считаю свайп клавиатуры.
Апофеоз — это голосовой набор и отправка распознанного в сыром виде. Или вообще без распознавания.
А свайп-клавиатура — это единственное, что мирит меня с набором текста на телефоне. Именно потому, что на клавиатуре много кнопок, а экран маленький и они мелкие. Так что тыкать в них пальцем задолбаешься.
Тыканьем я могу набрать одно предложение. Потом устану. Свайпом меня вполне хватает на пару-тройку абзацев.
Просто люди тупые и это факт
Один из признаков тупого человека — непонимание, что у разных людей разные интересы и цели, и что далеко не всем людям интересно возиться с десктопом.
Я программист, я люблю десктопы, сейчас я сижу за тремя мониторами. Я использую Vim (не всегда, правда) и тайловые WM, так что чего-чего, а хоткеев я не боюсь. Тем не менее, я на телефоне используют только свайп клавиатуры, начиная с оригинального Swype на Windows Mobile, потому что это куда быстрее, чем тыкать пальцем в маааленькую нарисованную кнопочку. Пальцы большие, кнопки маленькие, пальцами перекрываются, тактильной обратной связи нет. Был бы аппаратный qwerty, но он почти вымер.
деградации я лично считаю свайп клавиатуры.
Свайп клавы не деградация, а доводка тач-клавы до юзабельного вида. Без свайпа быстро набрать на телефоне ничего невозможно — тыкать в эти малюсенькие кнопки без нормального тактильного отклика это просто мучение.
Пользую iPhone с последней iOS 13, благодаря тому, что на ней (а указал я ее именно поэтому) уже начали снимать ограничения песочницы (не то, чтобы ее убрали, но взаимодействие между приложениями стало значительно лучше), телефон начал превращаться в полноценную замену для компьютера. Сегодня я беру с собой телефон + наушники + мобильный интернет, иду в тот же парк, к лесу, или еще куда-то, где мне хорошо, и там делаю работу. Я могу одновременно присутствовать на занятии по английскому языку, при этом просматривая видео и документы, что преподаватель скидывает для использования во время занятия. Могу оплатить коммуналку по дороге на работу, будучи в метро. Могу просто посмотреть полезный технический ролик, послушать книгу или поиграться.
Будучи рьяным фанатом ПК в прошлом году я пол года прожил, не имея этого самого ПК дома, да еще и интернета имел всего 300 мегабайт на месяц. Я просто скачивал крупный контент заранее (часто на работе, задерживаясь по окончании рабочего дня), а на мелкий этого хватало и не имел никаких проблем. Мультимедийная система здесь. Чтение здесь. Коммуникации тоже здесь. Игры тоже здесь. И все отлично взаимодействует друг с другом.
Единственный недостаток мобильника: маленький экран. Но т.к. не возможно иметь маленький телефон и огромный экран одновременно, приходится с этим жить.
И вы же в курсе про эксперименты Apple по установке полноценной MacOS на iPhone? Товарищи из Apple собираются перевести их железо на arm, что означает, что MacOS начинает работать на том же железе, что и мобильники (с планшетами), а значит почему бы и нет. Есть план встраивать MacOS в iOS и активировать ее при подключении последней к монитору + мыши + клавиатуры. И это классный план. Если он стрельнет, в тех случаях, когда мне мало iOS, можно будет делать из нее MacOS. Вопрос лишь в станет в мощности железа, тут вот хз как прыгнуть выше головы. А так, ПК как таковой перестанет быть нужен вовсе. Уже сегодня игровой ноут не запускается неделями лишь потому, что желания играть на нем не возникает.
активировать ее при подключении последней к монитору + мыши + клавиатуры
Господи, десять лет все про эту идею говорят, но ни один не довел ее до конца.
Напомню: Windows Continuum, Ubuntu Touch, Samsung DeX и так далее.
Готовой системы, которая способна запускать десктопный софт — так и не появилось.
Если Apple таки сделает это — ну что, молодцы.
лишь потому, что желания играть на нем не возникает.
казалось бы, при чем тут ноутбук
Господи, десять лет все про эту идею говорят, но ни один не довел ее до конца.
Возможно говорят, но вы не учитываете 2 факта:
1. Мобильное железо стало довольно мощным и даже iPhone уже начинают иметь на борту шустрые процессоры и много оперативной памяти + толстые ssd.
2. Эти разговоры начали в отношении Apple после их заявки на перевод десктопа на Arm. Т.е. этой осенью они обещают выкатить iMac и MacBook (ну или что-то одно, если я не разобрался) на Arm вместо Intel. А это уже совсем другой разговор, при таком раскладе закинуть MacOS на iPhone лишь вопрос свободного места на ssd.
Будучи рьяным фанатом ПК в прошлом году я пол года прожил, не имея этого самого ПК дома, да еще и интернета имел всего 300 мегабайт на месяц
Может Вы и не были фанатом ПК?
Занятие — звук. Документы явно не из тех, что уже преформатированы в две колонки, как любят многие поставщики даже в наше время (их и на десктопе-то не очень удобно просматривать, а на мобилке вообще аут).
> Могу оплатить коммуналку по дороге на работу, будучи в метро.
И из работ ни одной не было названо таких, которые требуют набора заметных текстов или работы с большими текстами (а то и с программами). Ну да, при таких запросах можно и обойтись.
А код ревью сделаете со своего телефона? Автор статьи ведь именно такой пример привёл.
> Единственный недостаток мобильника: маленький экран.
А ещё отсутствие нормальной клавиатуры (все замены, даже с суперумной системой предвосхищения набранных слов, не сработают с программным текстом).
Документы явно не из тех, что уже преформатированы в две колонки
Чаще всего ms word. Разных вариаций. Если плохо видно — устройство набок и погнали.
И из работ ни одной не было названо таких, которые требуют набора заметных текстов или работы с большими текстами
Ага, а ещё на мобилке в Варкрафт плохо играть и в готику не побегаешь. Ну блин, специфические задачи на то и специфические, что требуют специального оборудования. В замен могу предложить вам потягать с собой пк с монитором в 27 дюймов и поработать на нем с вашим текстом в метро, или на ходу во время прогулки. Не можете? Г. ваш пк.
Вот такая логика у вас.
А код ревью сделаете со своего телефона?
Делал, и даже доступ на gitlab с мобильника давал. С доступом получилось дольше, чем с ПК, но ПК было лень включать, я на кухне сидел. Вполне себе осилил.
К слову, могу вас поддержать и продолжить цепочку, например, на мобилке кино смотреть не очень (хотя я сериалы в парке смотрел, на лавочке), на телевизоре в 40+ дюймов гораздо лучше видно.
Если продолжать спор, можно смело заявить, что ПК лажа, даёшь телевизоры! Мы же кино смотреть будем!
П.С. Прошу заметить, что ваш ответ вы набрали с мобильника, т.к. цитирования через теги то нет :)
Нет, это у вас такая логика. Потому что в статье были названы именно задачи, которые плохо вкладываются в телефон — на что вы почему-то стали рассказывать про совсем другие задачи.
> Делал, и даже доступ на gitlab с мобильника давал.
Про доступ не сомневаюсь, а вот полноценное ревью — ой.
Я и на большем мониторе уменьшаю шрифт до неприличного, убираю колонку табов и пр., чтобы получить полноценный двухколоночный формат…
Хотя, может, у вас в коде все изменения в 1-2 строчку с понятным контекстом, тогда тупо завидую — но такие задачки редки, мягко говоря.
> П.С. Прошу заметить, что ваш ответ вы набрали с мобильника, т.к. цитирования через теги то нет :)
Я не знаю, какие теги вы имеете в виду, но я набрал это с привычного домашнего десктопа (хотя он под столом) с 19″ монитором и 105-клавишной полноформатной клавиатурой.
Ваша ванга сломалась, несите следующую…
Потому что в статье были названы именно задачи, которые плохо вкладываются в телефон
Да да, действительно :)
Автор возмущается тем, что под мобилки сделаны приложения для код ревью и они работают лучше, чем десктопные версии :)
И как я этого сразу не понял.
Хотя, может, у вас в коде все изменения в 1-2 строчку с понятным контекстом, тогда тупо завидую — но такие задачки редки, мягко говоря.
Ну дык код надо писать как книгу, а не как набор непонятных инструкций для братьев наших меньших.
Хороший код не растянут в строку в 300 символов. Он прост, понятен и хорошо структурирован.
Я не знаю, какие теги вы имеете в виду, но я набрал это с привычного домашнего десктопа (хотя он под столом) с 19″ монитором и 105-клавишной полноформатной клавиатурой.
Ну вот а теперь посмотрите как выглядят мои комментарии и как ваши. В моих красивая верстка с отдельным оформлением для цитат, а у вас они просто помечены угловой скобкой. При этом я набрал текст с того самого 8го айфона, а вы с ПК, заточенного под работу с текстом. Может проблема все же не в инструменте?
Автор возмущается тем, что под мобилки сделаны приложения для код ревью и они работают лучше, чем десктопные версии :)
Странный вывод, я его не понимаю. Поясните.
Хороший код не растянут в строку в 300 символов. Он прост, понятен и хорошо структурирован.
Вот сразу и передёрг про "300 символов". На самом деле, я думаю, у вас слишком простые задачи :)
В моих красивая верстка с отдельным оформлением для цитат, а у вас они просто помечены угловой скобкой.
"Красивая вёрстка" это голубая полоска слева? Не вижу ничего такого, что объясняло бы слово "красиво"… ну ладно, вот я для данного конкретного постинга включил галочку Markdown. Набирал же 1:1 с прошлым вариантом.
Может проблема все же не в инструменте?
Верно, не в инструменте. Тут скорее в "красивостях" вместо смысла.
Странный вывод, я его не понимаю. Поясните.
Автор возмущён тем, что десктоп задвигается на второй план и все больше компаний делают упор на мобильный рынок. Под мобильник делается классное приложение, а под десктоп плохонькая веб страничка и на этом все. При этом посыл автора «че за фигня, десктоп жеж круче мобилки и важнее ее». Я привёл в пример меня и показал, что это уже не совсем так. Не берусь судить хорошо ли это, но мобильник сегодня — это как маленький десктоп для кучи рутинных задач. Он не заменяет десктоп на все 100, но во многих не очень сложных рутинных задачах справляется лучше. И это так не из-за искусственного перекоса, а потому что мобильник просто стал на это способен.
Вот сразу и передёрг про "300 символов". На самом деле, я думаю, у вас слишком простые задачи :)
100 символьный текст отлично читается на мобилке. У меня были разные проекты, в истории 10 лет работы в продуктовой компании, и нет, я не делаю код ревью с мобильника каждый день. Но несколько раз я смотрел код с мобильника, когда было лень включать десктоп или был в дороге. И само собой правки были не на уровне «переписали пол проекта». Хотя, если был просто новый компонент — он тоже на ура читался с мобилки. Сложнее всего смотреть сложный дифф с кучей мелких изменений. Да ещё и на длиннющих строках. Но с этим и на десктопе бывают проблемы. Мне раз попался файл, где вся последовательность из блоков (лямбда функций) не умещалась на моих 27 дюймах. От начала до конца надо было примерно 50 дюймов. Так что, косяк тут явно не в мобильнике.
"Красивая вёрстка" это голубая полоска слева? Не вижу ничего такого, что объясняло бы слово "красиво"… ну ладно, вот я для данного конкретного постинга включил галочку Markdown.
Ага, она самая. Красиво же, и сразу читается лучше.
При этом посыл автора «че за фигня, десктоп жеж круче мобилки и важнее ее».
Перечитал исходное, нигде не нашёл даже намёком про "круче" и "важнее". "Важно" — да, есть. "Важнее" — нет. Если вы будете так беспричинно домысливать, нормальной дискуссии не получится.
100 символьный текст отлично читается на мобилке.
Возможно, это вам лично так удобно. У меня хоть и мелкая (на десяток человек), но статистика — большинство жутко недовольно и допускает такое только как спец-аварийный вариант.
Ага, она самая. Красиво же, и сразу читается лучше.
Во-во — вы только про красоту и думаете. А теперь попробуйте сохранить текст комментария в архиве. Там, где эта "красивая полоска", придётся возвращать признак квотинга вручную на каждом куске цитаты.
Возможно, это вам лично так удобно. У меня хоть и мелкая (на десяток человек), но статистика — большинство жутко недовольно и допускает такое только как спец-аварийный вариант.
ну что я могу сказать, на собеседованиях я завернул уже 4 человека с биркой seniour, последний имел на 2 года больше опыта, чем я, и при этом не знал элементарных основ.
Так что да, кому что нравится. У нас в компании народ отборный, поэтому часто мысли совпадают, а посему мало кто стремится растягивать строки до невероятных широт.
А теперь попробуйте сохранить текст комментария в архиве.
unicode нам поможет. Если его мало — base64 нам поможет. Не вижу вообще никаких проблем куда-то сохранить текст. Самая легкая из задач. Вон, и habr с ней справляется в лучшем виде.
unicode нам поможет. Если его мало — base64 нам поможет.
Мне так "нравится", когда вы пишете уверенным тоном то, что не попробовали… там просто вместо любых нормальных средств квотинга появляется пара пробелов.
Вон, и habr с ней справляется в лучшем виде.
Я не вижу кнопки сохранить текст в файл в читаемом виде и с сохранением факта квотинга.
ну что я могу сказать, на собеседованиях я завернул уже 4 человека с биркой seniour, последний имел на 2 года больше опыта, чем я, и при этом не знал элементарных основ.
С такой бессмысленной аррогантностью вы тут точно далеко не уйдёте.
Если плохо видно — устройство набок и погналиСкорее всего вы всё-таки reader, а не writer.В устройстве на боку видно ещё меньше, т.к.клава занимает больше места.Выделить какой-то существенный кусок текста и перенести его в другой абзац так же доставляет удовольствия.
Для смартфонов надо делать текст, а не его изображение — чтобы читать можно было при любом размере, от 4 до 8 дюймов. На 6″ и ниже сложно читать даже при двух колонках. А мотание туда-обратно за второй колонкой даёт ещё неудобства.
Я же говорил всецело про десктоп/лаптоп.

Посмотрел примеры, спасибо.
У меня всё строго наоборот: в вашем одноколоночном примере текст нормально читается, а в двухколоночном — постоянно прерывается переносами; кроме того, присутствие соседней колонки постоянно сбивает чтение желанием перенести на неё взгляд поискать там начало или продолжение. Если хотя бы поставили вертикальную черту между ними, второй фактор бы не работал (так часто делают в словарях), но первый — остаётся.
Возможно, это последствие постоянной работы с компьютером (типичная строка около 80 символов, а сейчас часто и длиннее; в двухколоночном формате тут где-то 40-50). Но тогда я такой далеко не один.
Единственное видимое преимущество двухколоночного формата в таких статьях — что короткие формулы (как в вашем примере), которые требуют отдельной высокой строки, занимают в двухколоночном формате в 2 раза меньше места. Но где сейчас в серьёзных научных статьях такие короткие формулы? ;) (не в наезд авторам этой статьи, но я обычно вижу сильно более длинные)
На картинке в одноколоночном формате 100 символов в строке — и я соглашусь, что такое читается тяжело. В двухколоночном — 60 символов в строке и выглядит имхо лучше. Хотя именно читать с именно большого десктопного монитора я бы ни тот ни другой вариант не стал. А с электронной читалки размером а-ля киндл, конечно же, одноколоночный формат куда лучше.
1. apple получает не за приложение, а за покупки приложения и внутри приложения
2. 30% в первый год, далее 15%
3. apple уже что-то говорило про обязательную продажу приложений на mac os через appstore, по идее пока не строго, но со временем они хотят к этому придти
4. ничто не мешает apple принуждать так же совершать покупки внутри приложений на mac os с комиссией.
так что деньги как аргумент — это аргумент, но я не уверен, что он сработает.
в конце концов всегда можно внести ограничения в версию mac os, запускаемую на iPhone.

Также в мобильной версии нету автоматического перевода отзывов, из-за чего параллельно приходится пользоваться десктопно-браузерной версией.
Нас не стало меньше, нас просто размыло гигантской массой народу которые благодаря нижайшему порогу входа получили доступ к цифровым благам.
До карантина я и не представлял себе — какая масса людей не может позволить себе купить полноценный ПК. И то, что в семье из трех взрослых работающих людей может быть только один ноут на всех.
Еще есть нюанс, что десктоп — порождение славных ушедших времен, который предоставляет чересчур большую свободу пользователю. Что, конечно, не так удобно, как гладкий уютный однокнопочный девайс, заточеный, да и рожденный вместе с DRM, да в эпоху коррозиеи приватности
в инстаграм монетизация лучше поставлена и щедрее, чем на том же youtube?
При этом без регистрации «стену» блогера дальше пары экранов не посмотреть — вылазит попап что-то вроде «чтобы смотреть дальше — зарегистрируйтесь».
Но больше всего бесит их видео-движок в котором… нет регулятора громкости. И mute нажать некуда.
По-крайней мере такой среднестатистический пользователь как я — не нашёл.
Странная платформа, непонятно как до сих пор выжившая.
А на компе?
Лезть в трей, убавлять громкость там?
Я чаще просто закрываю вкладку с инставидео и всё. Тем более, что там вряд ли что стоящее будет.
Нормальные видео выкладывают на youtube.
Бывают такие клавиатуры.
У меня — обычная.
Ну и, насколько я понимаю, это системная громкость и есть.
Не конкретно для этого приложения ведь?
Давлю на ссылку, ведущую в инстаграм — «по-ошибке» конечно, потому что на видео какая-нибудь гламурная фифа крутит татуированной попой перед камерой — ну как обычно водится в инстаграмме. Ничего другого я там не видел.
И всё это сопровождается каким-нибудь поганым BLM-ным рэпом с интонациями за которые в моём гопническом детстве можно было схлопотать в табло за 5 секунд.
Причём рэп этот — на максимальной громкости.
Т.к. я только что ткнул в ссылку мышкой, то видео у это выскочило у меня буквально «под мышью». И был бы какой-то элемент управления звуком — я бы тут же сместил указатель на пару сантиметров и заглушил звук.
Но… звук в инстаграмме никак не убрать — только уменьшать системный! Вместе с моим музоном.
Как на ютьбе — приглушить или вообще отключить звук именно в плеере, не трогая системный уровень звука — нельзя.
Понятно, что такое видео я просто закрою, но сам факт приводит в недоумение.
Более того, для меня это даже странно: во вкладке ведь может быть не один плеер.
Вместо этого я привык (user experience), что в НОРМАЛЬНОМ плеере есть элементы управления звуком. Внутри плеера.
А вот в ущербном инстаграмовском — нет.
Вот проигрывается видео с инстаграмма — единственное что изменилось в хроме — это появился значок в правом верхнем углу:

Там из управления воспроизведением — только пауза:

На ней всплывает облачко, где… написано «На этой вкладке воспроизводится аудио»
*facepalm*

Клава Logitech (там они прям подписаны доп. значками), операционка Linux Mint Cinnamon
fn + F9 — mute
fn + F10 — volume down
fn + F11 — volume up
@
Ошибиться, признать неправильность своего мнения
@
Все еще свято считать, что чуть другое свое мнение — правильное.
овцеграм опустил планку конечно. основные потребители это те, для кого потребление это основной вид деятельности. и они диктуют моду. но мы делаем продукт для профессионалов, и я не всегда делаю mobile first, но зато всегда разрабатываю сразу управление бизнесом с мобильного телефона, и это чесно говоря удобнее мне самому — я могу с телефона сделать всё что нужно, зарегистрировать продавца, отменить чек, сделать инвентаризацию. просто потому что комп таскать тяжело. так что… наверное стоит делать об этом как о кризисе по китайски, который ещё значит "возможность"
Вообще говоря, я разработчик фронта и потому могу быть предвзят в этом вопросе, но для себя я решил так: и глобально и локально есть задачи малокомпонентные, для которых достаточно мобилки, а есть многокомпонентные, которые проще и удобнее решать на десктопе.
Про этом такое разделение верно не только глобально, но и локально. То есть подобные разные задачи можно встретить в единой сущности. Например, онлайн-банкинг. Мне удобно в пару тапов на мобилке посмотреть баланс или закинуть денежку на телефон, но если я анализирую траты, то пользуюсь web-версией.
В общем, мое мнение: оба формата должны сосуществовать и только так можно поддержать удобство и комфорт для всех пользователей.
(рандомный скриншот из интернета)
высокую скорость интернетаРазве только в Москве. А так для мобильной сети перегруз базовых станций и плохое покрытие — это её обычное состояние. В час пик, бывает, даже в центре города ya.ru по 8 секунд грузится.
Иногда ребята, которые делают сайты, делают их так, что они даже на десктопе с интернетом под сотню мбит/с грузятся полгода.
Недавно я даже заскринил, так меня взбесило. То ли ситилинк, то ли ДНС.

А про поделия сумрачного китайского гения я вообще молчу.
Недавно с коллегами зацепились языками на тему «зачем для интернет-банка городить приложения для разных ОС, если все то же самое может делать мобильная версия сайта за гораздо меньшие деньги». Сошлись на единственном бенефите приложения — сканер отпечатков пальцев [пока еще] не везде «дает» браузерам.
Сделал игру для десктопа. Скоро релиз, все условно ок. Начал прощупывать мобильную версию — запустил, посмотрел, привязал масштабирование UI. А потом глянул на конкурентов и стало видно, что я безнадежно отстал — десктопный интерфейс по пикселям на телефоне помещается, а по логике, размеру и тач возможностям — никак. И простых путей тут нет, это как два разных полотна, где в одном видны мельчайшие детали в стиле реализма, а в другом жирные импрессионистские мазки фокусируют внимание на самом важном. И мобильный "импрессионизм" имеет больший охват и потенциал, чем ретро-реализм, к которому мы так привычны.
Портировать десктопный UI на мобилки это серьёзная заявка на победу. Даже под консоли приходится переделывать, а тут консоль плюс ещё микроэкран (с огромным разрешением).
Но в этой «мобилизации» есть и положительная сторона — облегчение. Начинают делать аккуратнее, минималистичнее. Помните последние тренды разработки под десктоп? Они были такие: «На моих X ядрах, Y гигабайтах и оптическом подключении — нормально работает, годится!». И несколько вкладок могли загрузить ЦП на 100% и заполнить ОЗУ полностью. И дизайн, в котором от обилия элементов в глазах рябило.
Но хорошо хоть, некоторые продолжают работать по старинке, делая полноценные приложения для всех популярных платформ; причем десктопные приложения делают с более функциональным интерфейсом, а мобильные — с упрощенным, удобным для тыканья пальцем. Хорошо, например, работают некоторые производители мессенджеров (Телеграм, Дискорд, Аська) и браузеров (Хром, Файрфокс, Опера).

desktop — покажите мне нормальную читалку книг с синхронизацией, заметками, поддержкой большой библиотеки? А нету (частично подходит iBooks но менеджер библиотеки там… интересный ну и синхронизация даже с айфонами тупит иногда. Встроенная читалка Calibre — без синхронизации. Kindle — десктоп-версия только книги с kindle store умеет). Приходится использования например веб-клиент Bookfusion (они кстати обещают desktop в этом году) или Pocketbook'овский веб-клиент либо… Dex + андроидный Calibre Companion + Moon+
мобилки — вот где брать нормально работающий клиент Evernote? с рабочим поиском, тегами и так далее и чтобы все быстро работало? (Galaxy Note 10+, свободно несколько десятков Gb на встроенной памяти — нет, все лагает при поиске, большие заметки(ориентировочно — выше где то 600 Kb текста) может вообще не открыть а уж их редактировать лучше даже не мечтать). Хотя на любом десктопе за которыми — работает нормально. (ну да на десктопе база данных Evernote занимает под 30 Gb и там десятки тысяч заметок).
Что-то уровня Android Studio — я вообще не представляю как на маленьком экране использовать (10" в данном случае — маленький экран), я часто 2 24" монитора использую для Android Studio.
ICE Book Reader очень хорош.
Я пользовался ICE Book Reader до тех пор, пока не наткнулся на STDU Viewer (Scientific and technical documentation viewer).
В STDU, конечно, есть определенные косяки — но практическая всеядность их компенсирует.
— насколько я помню Windows-only (мне желательно хотя бы и мак тоже. а был период когда мак-версия была в приоритете(поэтому iBooks упомянут))
— как с мобильным чтением то быть? Покупать 8" (а меньше разве есть?) планшет на Win10?
— что с epub3? (с момента последнего знакомства с ним у меня книги где epub3 — не блажь — появились).
2)Мобильный да — у меня там другие читалки FBReader в первую очередь, и Moon+ Reader как дополнительно. Еще иногда CoolReader пользую.
3)Вроде полностью поддерживается. Там только один нюанс — все автоконвертится во внутренний формат. А так поддерживает почти все.
Можно бесконечно смотреть на 3 вещи: огонь, воду и как fillpackart клепает статьи об инженерах, которые практикуют правильный подход к технологиям, но мир несовершенен и поэтому они страдают.
2. Другим «Анти примером» будет Телеграм — он просто и одинаково работает везде и на всём!
Вообще странные вещи происходят с этой поголовной мобилизацией. Я уж думал мы пережили эту блажь про "по приложению на каждый чих". Ан нет прихожу недавно в отделение одной из популярных в Украине почтовых служб забрать посылку с али (тут надо добавить что какой службой всякая мелочь приходит к нам зависит от какого-то рендома), а они мне говорят "мы без предложения посылок не выдаем".
Вот нахрена мне их приложение, если я пользуюсь ими 5 раз в год и то по не зависящее от меня причине...

{kind=link}
{kind=link}
{kind=link}
{kind=link}
/send?phone=NUMBER) таким образом решающий поставленную задачу — переписка на десктопе с продавцами/покупателями. Многие другие решения легко можно найти на чистом десктопе — да, они будут не такие удобные (правда мне всё удобнее, лишь бы не использовать телефон), но, ведь, работают. В результате имеем маргенализируемый десктоп, который, через ещё чуть непродолжительное время, будет использован исключительно профессионалами и для развлечения (код, cad, звук, графика, геймеры), а в остальных случаях всегда будет возможность повторить нечто меньше, в большем.
Недавно вернулся к увлечению фотографией, установил классическую и «мобильную» версию на компьютер и опечалился – на развитие классической так и забили лет 10 назад, обновляют профили, сделали синхронизацию с облаком и делают упор на том, что пора сваливать на «мобильную», а в ней за 5 лет так и не появилось нужных функций. В итоге нормальное приложение развалили предоставив выбор, либо модное-удобное облако, либо по-старинке.
Я не знаю как это работает в таких компаниях, но они просто разваливают бренд и если завтра появится свежая развитая на десктопе альтернатива, то вместо выбора я лучше переключусь на нее.
Так альтернатив полно.
У того же Адоба есть Lightroom Classic, а есть Lightroom CC — если хочется чтобы было как на смартфоне.
Если нужны фичи — есть Capture One, причем с бесплатной версией для Fuji и Sony.
Нужно модно и с нейросетями — Luminar.
Для сторонников Open source — Darktable.
Для Мака Affinity Photo ещё есть.
За остальные рекомендации спасибо, надо рассмотреть альтернативы.
В Capture One отличный редактор и грустный каталог. В Luminar крайне медленный (как ваще вышло сделать тормознее лайтрума-то?!) и очень хипстерский редактор. С darktable хорош совместно с linux, кроме Digicam с каталогом особо и нет конкурентов. Да и падуч. На винде с макосью уже не то пальто. ON1 уступает и как редактор, и каталогизатор (тоже невероятно медленный). В DxO Photolab с каталогом вообще грустно.
И тут вы такой, люди, вы чего отвелкаетесь, просто не отвлекайтесь. Ага, как я раньше то не догадался до такого простого решения.
Я вот помню как в поезде ездил и… столько времени было потрачено.
Я даже книги не читал, так как было сложно сосредоточится.
А сейчас — бамц и слушаю по 60-120 в год. Там конференцию в пути посмотрю, там пулл-реквест отправлю. Идей запишу в гугл док.
Конечно же с телефоном многое позже на листание методички перед экзаменом. Теперь можно за 10 минут до встречи всю переписку прочитать, всех пробить в линкедине и по теме выудить ключевую информацию в гугле — можно вообще не готовиться. Этим многие и пользуются.
Айти — это не только масочки в инстаграмчике.
Инфраструктура это у нас что? Тяжмаш, логистика, коммодити. У вас воду отключат на неделю, как вы думаете, операторы будут рулить ситуацией мобайл ферст? А если ляжет грид (вы ведь в курсе, что это?).
Наивность людей, которые думают, что их комфорт рождается из воздуха, а технологии нужны, чтобы cмотреть этот ваш «контент».
Сейчас бы сваливать в одну кучу промышленные интерфейсы и просмотр фоточек в инстаграме.
Нужно исходить из целей конкретных пользователей.
Бухгалтеру вряд-ли будет удобно использовать 1С на смартфоне, если это не какое-то дополнение к десктопу.
А вот рабочему на заводе, вполне может больше подойти простой сенсорный интерфейс с минимумом кнопок и дублированием важных переключателей механическими кнопками.
Главное — вовсе не потребление, и тем более "контента", а производство. Потребители не двигают цивилизацию вперёд — нечем. Незачем на них и ориентироваться. А производить на мобайле годно разве что фотографии — и то ценность сомнительна.
Вспоминается фильм Дудя про Сил. Долину: 3 часа диалогов с дядьками, пилящими продукты вида «масочки для инстаграмчика» и 5 минут — с парнем, снимающим с дронов землю с целью понять ее геологию с помощью машинного зрения.
Уверен, последний не заморачивается на мобайл фест.
Разумеется, это все имхо, но мне каждый раз больно когда мне кидают гугл-таблицу вместо нормального файла
Забавный бомбеж)
А нужно ли всех насильно сажать за десктопы? Всем ли нужен миллион кнопок в плеере, как было в Winamp, если основная цель слушать музыку, а не нажимать кнопки?
Почему бы не учитывать именно потребности конкретных пользователей.
Тому же ПМу на обязательно всегда нужен десктоп, позволяющий редактировать код. А вот удобный тач-интерфейс, позволяющий на ходу со смартфона или планшета отслеживать выполнение тасков придется весьма кстати.
Прошло время, когда софт писали гики для гиков, не учитывая аудиторию и условия, в которых будет использоваться этот самый софт.
Извините, но это бизнес.
Вы готовы оплачивать разработку отдельной расширенной версии софта, которая будет удобна именно вам (или ещё парочке пользователей), но ухудшит юзабилити для большинства других или понизит конверсию для разработчика?
Тогда можете попробовать обратиться к нему (разработчику) напрямую. Производители суперкаров, например, не отказывают покупателям, у которых есть особые требования и возможность платить за уникальные версии или даже новые модели своих авто.
Я не старый бубнящий дед, который не может принять, что все меняется
Press F to doubt
Бред. Пусть попробуют на мобильнике помонтировать документалку длиной в час, концерт в мультикаме, где каждая склейка дб идеальная по видео и звуку или сделать какой-нить After Effect-проект, где больше ста слоев.
А было время, когда оно цеплялось за все новые технологии, а вот теперь брыкается от новой волны мобилизации всего и вся.
«Остановите эту планету я сойду». Смешно жаловаться, когда прогресс, прошелся по лично твоему удобству и пошел дальше и кричать ему в до гонку, не трогай ПК, я к нему привык.
рынок смартфонов растет, рынок ПК падает
Рынок ПК насыщен, смартам пока есть куда расти.
Было время, когда ПК нужно было апгрейдить раз в год/два.
Оно прошло (см. фильм The Onion Movie, там этот момент хорошо обыгран :)
Сейчас люди меняют смарты, при этом человек не может внятно объяснить, чем его не устраивает 10 айфон и почему ему нужен 11, причем тогда, когда на горизонте уже маячит 12.
Естественно, рынок смартов будет расти (тем более, что и физический срок службы у них гораздо меньше)
Эти же люди, что портят UX человека разумного, сломали нам поиск, поставив монетизацию через рекламу во главу угла. См., например, Яндекс, выдающий на запрос «пифагоровы штаны» рекламу «Брюки от 290 руб. на Беру – Скидки и акции каждый день».
А траты на детей делаются очень рационально, новую версию коляски не покупают, каждые полгода, а наоборот коляски, автокресла, стараются брать, передавать и т.д., по крайней мере после первого ребенка.
А маркетинг, уже давно, перешел от заманивания «успешным образом жизни» к формированию этого «образа». А «успешный образ жизни» и много детей в рекламе не сочетаются в принципе. Кстати, реклама mazda, прямо агитирует за child-free.
Последний абзац действительно гениальный
Вообще не могу согласиться. У меня правда андроид а не айфон, но тикеты ведутся в джире. Каждый день запускаю, и каждый мать его день оно требует кучи действий чтобы войти в систему. И далее, войдя с телефона через их приложение, я вижу всё тот же веб, но очень мелко и неудобно. Так что под дроид фактически нет приложения, проще сразу браузер открывать — он хоть помнит что уже логинились.
и у меня нет ни одного механизма, чтобы заставить их так же доверять моему компу. Ни одного.Так Authy же, впилите туда свои 2FA, и можете коды брать со своего ненаглядного десктопа.
На маленьком экране не получится сделать сложную многофункциональную форму — значит сложных форм больше не будет.
Именно поэтому с брокером, банком, предпочитаю работать через мобильное приложение. На иконку нажал, пару раз свайпнул/тапнул, закрыл. На компе: зашел на сайт, вводишь пароль (благо есть lastpass с автозаполнением), потом ждешь СМСку, заходишь, и на тебе, сложные формы с купой менюшек и полей, иногда с дизайном из 2000-х. Блеванул, закрыл.
В итоге получается, что раз большинство людей не хочет использовать сложное, но крутое ПО — значит сложного и крутого ПО просто не будет. Ни для кого.
Сложное, крутое ПО всегда будет на десктопе когда оно оправданно. Никто же не заставляет на телефоне кодить, делать ревью, редактировать видосики, редактировать текст.
Вообще, по своему опыту, потреблять контент (кроме видео или чтение большего текста) проще на телефоне, тупо потому что он всегда под рукой. А вот создавать контент — проще на десктопе.
Не надо прыгать из крайности в крайность и делать на телефоне то, что всегда делалось на десктопе и для чего на десткопе есть специализированные приложения которые телефон никогда не заменить. Особенно когда никто не заставляет использовать телефон для этих задач.
Умеешь работать с большими объёмами данных, набивать осмысленные тексты — добро пожаловать в мир ПК. Привык давить лайки и свайпить котят — твой смартфон всегда с тобой.
Я прекрасно помню когда практически тоже самое говорили про винду и линукс.
Или например про тех людей которые пользуются мышкой и тех, которые пользуются исключительно клавиатурой и консолью.
А вот разница между полноценной клавиатурой и виртуальной, где двумя пальцами надо тыкать, это как между рукой с развитыми пальцами примата и ластами тюленя. Клавиатура позволяет в полной мере использовать всё богатство письменного языка. Телефон смартфона для этого функционально не предназначен.
То же про экраны.
Смартфон и ПК это на мой взгляд такое же "дело вкуса" как и винда/линукс. Да и клавиатура на смартфоне в обсуждаемом нами контексте от клавиатуры ПК ничем принципиально не отличается. Банально дело привычки.
Скорость набора текста на клавиатуре к культуре имеет мало отношения.
Я знаю кучу людей, которые и на клавиатуре двумя пальцами текст набирают, но при этом бескультурными их не назовёшь.
В конце концов большинство молодёжи на своих смартфонах любой текст быстрее "насвайпают" чем Пушкин мог от руки писать. Но это их автоматом культурнее не делает.
Мне кажется ваш собеседник прав, а иначе почему в старой доброй Ирке люди печатают простыни текста и не обламываются, а в новомодном Телеграмме молодежь общается преимущественно смайликами, стикерами и прочими мемами.
На смартфоне длинный текст не получится ни набрать ни насвайпать, банально большой палец устанет.
Это вы подросткам расскажите. Они посмеются.
Мне кажется ваш собеседник прав, а иначе почему в старой доброй Ирке люди печатают простыни текста и не обламываются, а в новомодном Телеграмме молодежь общается преимущественно смайликами, стикерами и прочими мемами.
Потому что в Ирке не молодёжь? И потому что если молодёжь туда пустить и дать им возможность, то они всё равно будут общаться преимущественно смайликами, стикерами и прочими мемами?
Это вы подросткам расскажите. Они посмеются.
17-летние не набирают. Они посылают друг другу голосовые сообщения.
(процесс наблюдаю ежедневно :)
За 14 -летних не скажу.
В мире, где каждый продукт делается под мобильники, у всех продуктов останутся только те функции, которые будут удобными на мобильниках.
Мне это напоминает другую известную фразу:
Сделайте продукт, который сможет использовать любой идиот, и только идиоты и будут им пользоваться.
Либо, что ближе к теме статьи:
… все пользователи станут идиотами
Хотя, как здесь выше писали, может дело и не в том, что пользователи поглупели, а в том, что порог вхождения очень упал и смартфоном теперь пользуются все, даже те, кто раньше в компьютерах не разбирался.
Тут возникает вопрос. Нужно ли всем и каждому уметь пользоваться компьютером и понимать, как это работает? Понимать не только, как потребить контент, но и как он создаётся? Я твёрдо убеждён, что каждому нужно быть хотя бы уверенным пользователем, иметь представление о компьютерах и сетях, алгоритмах. Просто мы живём в такое время. Когда-то просто необходимо было уметь скакать на лошади или выращивать сельскохозяйственные культуры. А в наше время — пользоваться компьютером. Ещё лучше — понимать как он работает, хоть в общих чертах. Каждый не должне быть программистом, но каждый должен написать несколько программ в школе на информатике. Это банально поможет автоматизировать документооборот на работе вместо бездумного труда. Иначе многие люди просто не задумываются, что вот это повторяющееся действие можно автоматизировать.
А ещё я вспоминаю старый ролик (сейчас уже не найду) про Unix, одну из первых версий. Там приятная такая девушка (наверное секретарь, точно не программист) рассказывает, как ей нравится удобство и понятность командной строки, как хорошо использовать перенаправление ввода/вывода между утилитами, что позволяет ей из простых утилит собрать нужный в данный момент функционал, в результате работать быстрее и лучше. Это я к чему? Если вы системный администратор и к вам подходит с вопросом «Я ничего не нажимала, пароль не работает» (отжать капс) сотрудница, которая залипает в инстаграм, соцсетях, с котиками… Не нужно за неё ничего делать, нужно направить в правильное русло, на поиски знаний, пусть разбирается сама. Может быть даже путём физического приложения трудов Таненбаума к воспитательной области. А если вы программист, то поспорьте с заказчиком, когда он попросить упростить интерфейс приложения. И неважно, там mobile first или другая какая концепция. Интерфейс, он либо гибкий, настраиваемый и для нормальных развитых людей, либо убожество для альтернативных.
Хм, а вы всё что вас окружает "понимаете в общих чертах"? Ну то есть вы даже просто разбираетесь в медицине, биологии, физике, химии, географии, политике, литературе больше чем на уровне школьной программы? Вот прямо во всём-всём?
Я просто пару лет назад имел дискуссию с одним филологом который точно так же доказывал что обычные люди просто обязаны лучше разбираться в литературе и искусстве…
Почти всё из перечисленного вами как раз и нужно понимать, как минимум, в общих чертах и изучать в школе.
Так «в общих чертах» или «понимать, как это работает»? Bот вы понимаете как работают все медикаменты, которые вам врач выписывает? Вы в школе создали сами хотя бы парочку на уроке химии?
Не скажу, что я специалист в этих вопросах, но когда мне «врачи» выписывают «уникальный российский препарат, не имеющий аналогов в мире», я понимаю, что это полная ерунда, с поиском на «Пабмеде» справляюсь и по его результатам «врачу» советую пойти подальше.
Ну а вот я считаю что за назначение правильных медикаметнов должен отвечать врач. И если он начинает заниматься вот такими делами, то его должны наказывать. И оперировать меня врач должен нормально даже если я в медицине не разбираюсь. И механик мне должен правильно и честно ремонтировать машину и без того чтобы я сам разбирался в ремонте. И так далее и тому подобное.
По поводу политики я напомню выражение, которое часто пишут на Хабре: «если вы не занимаетесь политикой, то она займётся вами». Собственно это мы и наблюдаем, как «хорошо» мы живём.
Ну и насколько хорошо вы сами разбираетесь в политике и скжем юриспруденции? Вы уверены что политологи и/или юристы посчитают что вы в этом действительно разбираетесь хоть на базовом уровне?
Просто естественно когда вы обладаете какими-то знаниями или умениями, то это обычно даёт вам какие-то преимущества над теми кто ими не обладает. Но в современном мире знатъ всё на том уровне, которые вы хотите от людей в плане компьютеров, не потянет большинство людей. Поэтому люди обычно смотрят не что знать важно и полезно в принципе, а что знать важнее и полезнее лично им. И для многих людей компьютеры в этом списке стоят далеко не на первом месте.
назначение правильных медикаметнов должен отвечать врач. И если он начинает заниматься вот такими делами, то его должны наказывать.
А кто будет его наказывать? Вот врач выписывает арбидол и оцилококцинум, а все его пациенты думают «ну он же врач, ему виднее», и бегут покупать сахар за стократную цену. И жалобу никто не подаст, так как все слепо верят врачу. То же самое с каким-нибудь шиномонтажом — если вы вообще не разбираетесь в автомобилях, то вместо заделывания пореза в одной покрышке за 500 руб, вы купите новый комплект резины за 50 000 руб, и будете уверены что так и нужно. И не нужно быть юристом с профильным образованием, чтобы понять что гаишник выписал вам неправомерный штраф. И так далее
Или например тот, кто ему выдал его врачебную лицензию и разрешил вести его врачебную практику.
Поймали врача на какой-нибудь непотребства и до свидания лицензия. А то и уголовное преследование если слишком начудил.
Аналогично и с механиками. И с гаишниками. И с кем угодно. Для этого в общем-то государство и существует. И под это дело я в общем-то налоги и плачу.
Если у вас соседи ночью шумят, то полиция как об этом должна узнать? Только от вас, и ваших соседей. Вы же не учились 5 лет на юриста по гражданскому праву чтобы знать тот факт, что шуметь после 23:00 нельзя?
И этого в совокупности со строгими наказаниями в случае нарушений в куче стран вполне себе достаточно чтобы держать ситуацию на приемлемом уровне.
P.S. Ну и мне например «арбидол и оцилококцинум» или что-то подобное пока никто не пытался выписывать. Хотя бы просто потому что моя страховка такое оплачивать не станет вообще или как минимум сначала разберётся кто и зачем мне такое выписал.
Bот вы понимаете как работают все медикаменты, которые вам врач выписывает? Вы в школе создали сами хотя бы парочку на уроке химии?
Ну а вот я считаю что за назначение правильных медикаметнов должен отвечать врач.
Взаимоисключающие параграфы какие-то. ИМХО, понимать как работает аспирин не значит что надо уметь его синтезировать, а то что врач отвечает за назначение лекарств не значит что не надо разбираться в том как работают медикаменты. Синтез тут вообще не при чем, далеко не каждый врач синтезировал хоть какое-то из выписываемых им лекарств. Ну и в общем, из-за такого рода аргументации, я больше на стороне вашего оппонента :)
ИМХО, понимать как работает аспирин не значит что надо уметь его синтезировать
А чтобы правильно его принимать совсем не нужно разбираться в том как он работает. Более того я уверен что и вы до конца не понимаете как он работает на самом деле.
Ну и в общем, из-за такого рода аргументации, я больше на стороне вашего оппонента :)
Подождите, но ведь именно мой оппонент и утверждает что для того чтобы пользоваться программами надо сначала самому написать парочку…
А чтобы правильно его принимать совсем не нужно разбираться в том как он работает. Более того я уверен что и вы до конца не понимаете как он работает на самом деле.
Сюрприз, но нужно. Не до конца, это уже к профессионалам, но банально осилить инструкцию и сообразить, например, что нельзя мешать его с чем-то, что врач в рецепте не указал — например, с алкоголем.
Подождите, но ведь именно мой оппонент и утверждает что для того чтобы пользоваться программами надо сначала самому написать парочку…
Но ведь утверждал он вовсе не это.
Вам бы наверное в Германии понравилось — там не то что десктоп-фест, там вообще пацаны за личное общение :)) Ну и в ходу такие гаджеты: medium.com/@snipsnapsnoop/tan-4309c4497928
А рынок сказал, что я без телефона больше не человек, и даже на гитхаб должен заходить, только когда введу код из сообщения на телефон.
Я на удалёнке, тестирую
На все подключения — vpn, почта, мессенджер, github — повесили дополнительную необходимость брать цифровой код из Microsoft Authenticator, он же Oracle Mobile Authenticator. Пользоваться им предлагалось только со смартфона.
Избил тревогу внутренним сисадминам. Они подсказали, что можно этим приложением пользоваться и на ноуте, но при настройке аккаунта в этом Microsoft Authenticator на шаге сканирования QR-код надо кликнуть по ссылке ‘Configure app without notifications‘ — переход выглядел нелогично, но сработал.
Вместо обычного
Code: только_цыфры
URL: линк_для_аппрува
надо использовать данные другого вида
Account Name: НАЗВАНИЕ_ДОМЕНА: рабочий@емайл
Secret Key: мешанина_из_букофф_и_цыфыр
Теперь ради аутентификации нет необходимости трогать себя за смартфон, всё происходит на экране ноута.
Возможно, это облегчение временно и связано с тем, что аутентифицироваться мне надо во внутренний домен, который находится под контролем внутренних сисадминов.
инстаграм станет маргинальным сервисом для кучки странных женщин, которые почему-то не любят десктопы.Я бы сказал, что автор совершенно прав. С одной оговоркой: таких Эллочек-людоедок миллионы, а интернет сейчас доступен каждому. Поэтому, слово «маргинальный» придётся вычеркнуть.
Проблема программистов в том, что они пытаются сделать продукт для своего уровня, а надо для Эллочки. Для этого надо понимать её интересы.
Тут хорошо иметь девушку Эллочку, как портал в её мир. Так много интересного можно накодить
Во все времена деньги делались на «идиотах». Не в обидном смысле.На массовости.
Тут хорошо иметь девушку Эллочку, как портал в её мир.Упаси Б-же! Это будет тот самый портал, который легко открыть, трудно закрыть и ещё труднее запихать обратно всех тварей, что успели сквозь него просочиться. Адские врата :)
Так много интересного можно накодитьИнтересного для Эллочек, а не для себя.
В гугл плее у шахмат 10к скачиваний, а у бегалки за монеткой — 20 миллионов. Даже у zoom миллионы скачиваний, а более кривую приложуху не смог родить даже майкрософт.
Да, потому что Эллочек — большинство.Таки да. Примерно 95% :)
Все эти приложения являются большой дырой в безопастности, так как никто не знает какие данные они начнут тянуть после следующего обновления. Многие из них запрашивают кучу прав.
Вспомни, например, nero — была удобная приложуха для записей дисков. Сначала они отлаживали глюки и скорость. Когда это было сделано, а развиваться надо, они стали пихать в код всё больше и больше. Это оттолкнуло пользователей, которым нужно было «просто записать диск». И неро уступил под давлением кустарных приложух с одной кнопкой.
А мобильник даёт возможность ещё и быстро находить такие приложухи.
Например, мне надо было узнать высоту. Я за 2 минуты скачал приложение, которое показывает только высоту по барометру и ЖПС в телефоне. Искать, где оно включается в гугл картах и в каком столетии это появится в яндекс навигаторе было бы дольше.
Сейчас век «ответов». Если твоё приложение даёт ответ на популярный вопрос и только на него — оно выстрелит. Типа, запостить фотку чтобы все её лайкнули. Вот и инста.
Не, есть большие телефоны, где на экране возможно многое. Но я вот не люблю лопаты и ношу компактный смартфон. А на нём очень многое уже неудобно. Те же, кто ратуют за мобильный мир, это, как правило, любители «полупланшетов», ну и сенсорного экрана.
Можно много говорить об удобстве двух больших мониторов (сам люблю) — но так все равно не удобно многие вещи делать!
Так что ждем нейроинтерфейсов, и тогда споры, что удобнее — отпадут сами собой.
А нейроинтерфейсы(особенно с прямой подачей картинки в мозг) лет десять ждать придётся и то в лучшем случае.
А вы оптимист.
В первые серьёзно вложились такие компании как Эппл и Самсунг, т.к. это непаханное поле для онлайн рекламы и вложенные деньги гарантированно окупятся.
Во второй вложился Илон Маск(из тех кто на слуху, а так ещё куча вариантов), а у него только со сроками проблема. Десять лет разве что до тестовых образцов, а не массового продукта. Но тут как пойдёт, какие препятствия будут и кто ещё вложится.
Ничего у Маска не выйдет даже за 10 лет, профессор Савельев доходчиво объяснил, почему: https://youtu.be/6D_zSUIW4aw
ИМХО, единственное, почему десктопы вообще ещё не умерли как формат — со смартфона неудобно печатать. Вот когда этот вопрос решится каким-то образом (голографическая клавиатура? 100% распознавание речи? brain-machine interface? хз....), про десктопы можно будет забыть.
Ни ноутбуки, ни тем более смартфоны не могут так же решать задачи. И пока не начнут выпускать массовые квантовые процессоры, десктопы не умрут.
Голографическая клавиатура, 100% распознавание речи, однозначно нет и никогда не догонят по удобству механическую клавиатуру.
Ближайший и единственный на мой взгляд заменитель прямой мысленный ввод, но там ещё далеко до массового продукта.

Мир меняется, ныне смартфон основной гаджет любого человека, чем бы он не занимался.
p.s. Снимающих вертикальное видео я все равно ненавижу. Но идея о том, что уже скоро выйдет вертикальное полноформатное кино, уже не кажется мне такой уж безумной.
0xd34df00d виртуальные рабочие столы? Жест какой нибудь придумают, тройное моргание к примеру.
Но идея о том, что уже скоро выйдет вертикальное полноформатное кино, уже не кажется мне такой уж безумной
См. полную версию (широкоформатную) старого советского фильма «Автомобиль, скрипка и собака Клякса»
Там и вертикалка, и горизонталка и выход в зал за пределы экрана — в общем Ролан Быков оттянулся по полной :)
Смотреть с 1:40
Возможно будут какие-то узконаправленные ролики.
Индустрия складывалась уже более 100 лет. Когда снимали первые фильма у людей даже телеков не было. Ни один выходивший прибор не изменил кино кардинально.
Скорее наоборот, кино становится все шире — 21:9 уже практически стандарт.
Это связано с экранами в кинотеатре, с горизонтальным формированием сцены в большинстве ситуаций и много какими еще факторами.
Взять сцену какого-то фильма — что там обычно происходит, например 2 чела разговаривают, они сидят обычно напротив или стоят, или идут, они не друг над другом. Какие-то вечеринки, где много людей — все они будут горизонтально, т.е. 90% сцен в кино горизонтальные.
Кто застал фидо, помнит, насколько удобно было редактировать сообщения в GoldED. А теперь приходится набирать в этих убогих формах на форуме, которые работают просто с цепочкой символов вместо отдельных реплик и структуры поста, и это новая нормальность. Ещё раньше на мейнфреймах были удобные формы ввода, которые канули в лету. А сейчас, значит, к телефонам всё обрушится.
Технологическое превосходство сопровождается жертвами в дизайне.
Просто это все степенная прогрессия стоимости. Потому что стоимость разработки растет кратно, число пользователей снижается кратно.
Разработка и поддержка функции на смартфоне — 10 тысяч долларов в месяц и сотни миллионов пользователей. 0,1 цента на пользователя. Сто функций на 10 долларов в месяц.
Разработка и поддержка функции на умной панели — 100 тысяч долларов в месяц и миллионы пользователей. 10 центов на пользователя. Десять функций на 100 долларов в месяц.
Разработка и поддержка функции на кокпите или мостике — миллионы долларов в месяц и тысячи пользователей. Тысячи долларов на пользователя в месяц на каждую функцию.
Это когда индустрия вновь консолидируется вокруг инициативы «каждой функции — своя инфраструктура»
Не надо портить инженерам десктопы своими мобильными решениями, одумайтесь