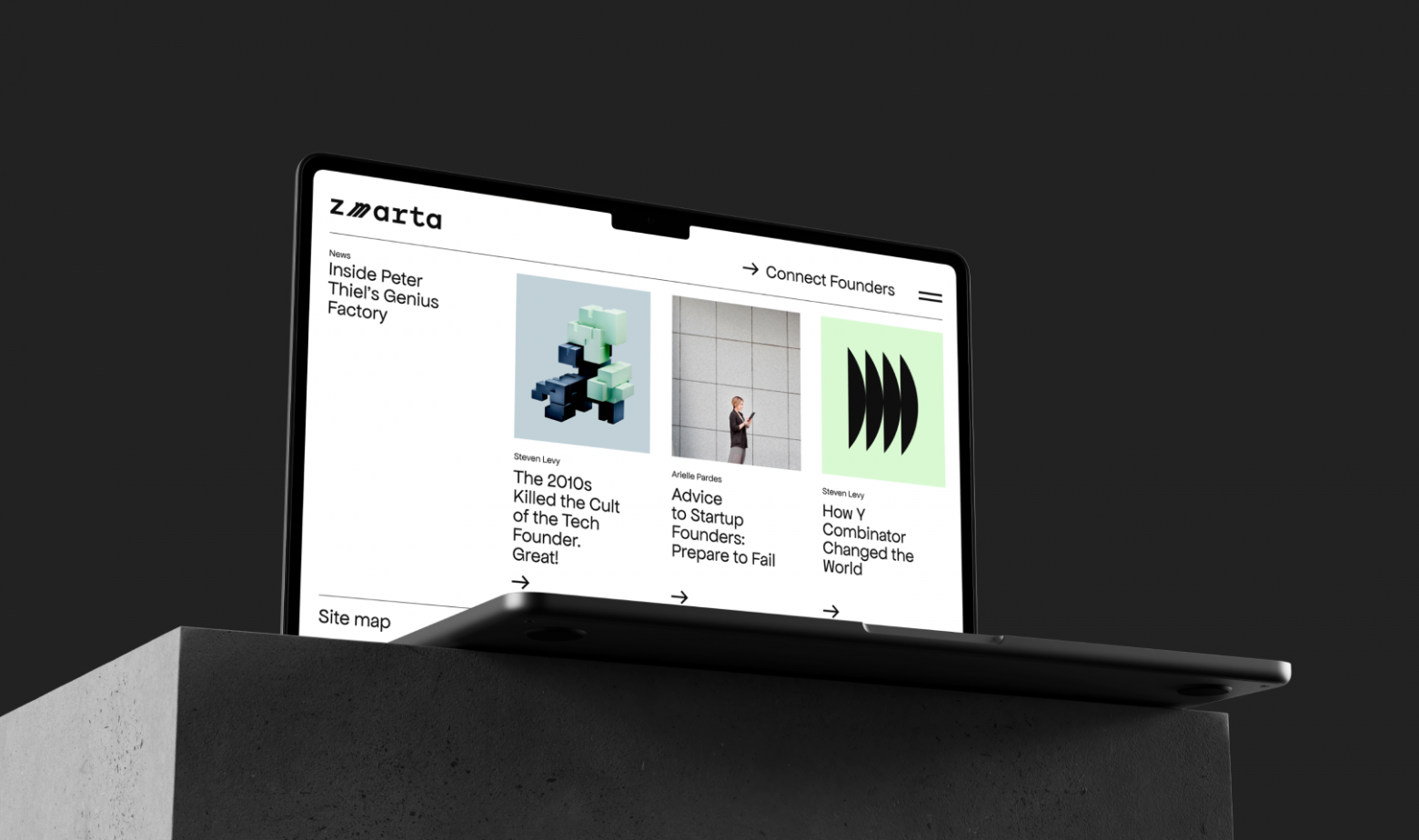
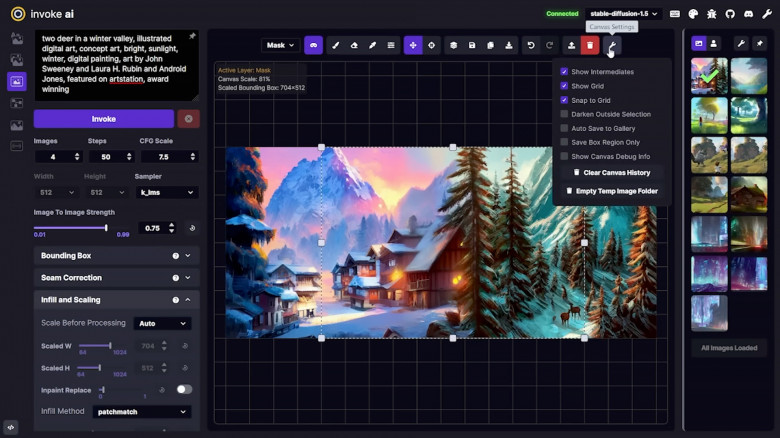
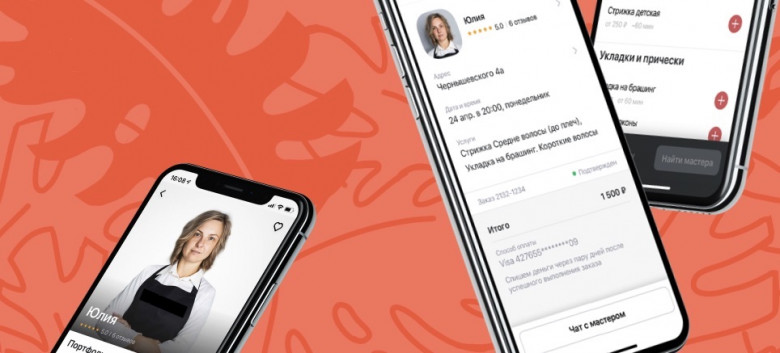
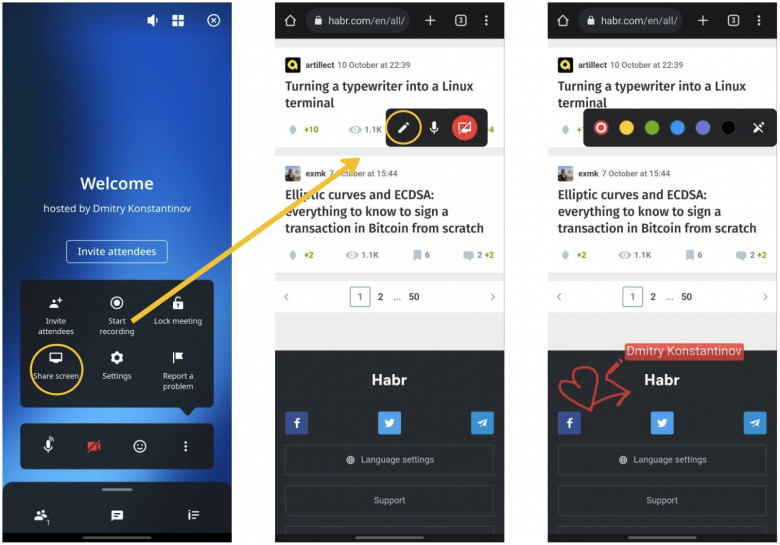
No matter how many degrees you have or how high your experience level is, your recruiters need to evaluate your knowledge of UX design as a whole. But keep in mind that a job interview is not an exam, so here you are expected not to recite the textbook definitions learned by heart, but rather share your personal understanding of UX and your role as a designer in general. Consider talking about how you define UX, what creates value in the design, what are the necessary parts of a UX design process, what are the current trends in UX. You might also be asked to explain the difference between UI and UX to see how you understand the role of each in the development process.