Getting a task from a client, UX designers tend to pay attention to the design goals, not the contents of the website/app itself. There’s something completely wrong with it because the visual part might be superb, but when it frames a vague or wordy message, the client's goals won’t be reached.
To avoid this, a UX designer should dive deeper into the content, analyze it, and restructure it in an interface-friendly way. It doesn’t mean doing the copywriter’s job, it means collaborating. The reality is that sometimes the writing team is used to praising the product (because clients like that), or there is no copywriter involved in the project at all.
Provide proof instead of opinion
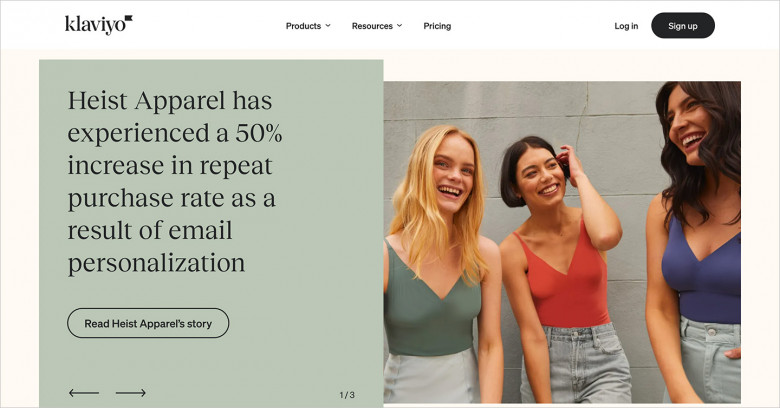
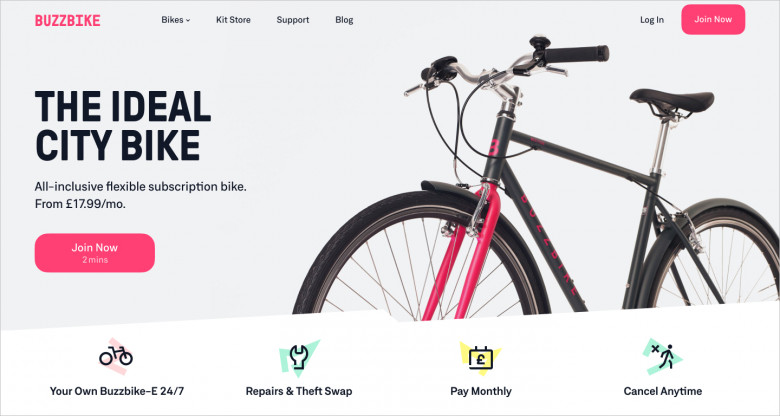
An impression is more powerful when the customer can conclude the product’s benefits on their own. Instead of a colorful line of adjectives like “ultimate” or “leading” you should aim at what exactly makes the product that cool. The trick is to be precise, preferably with an example.





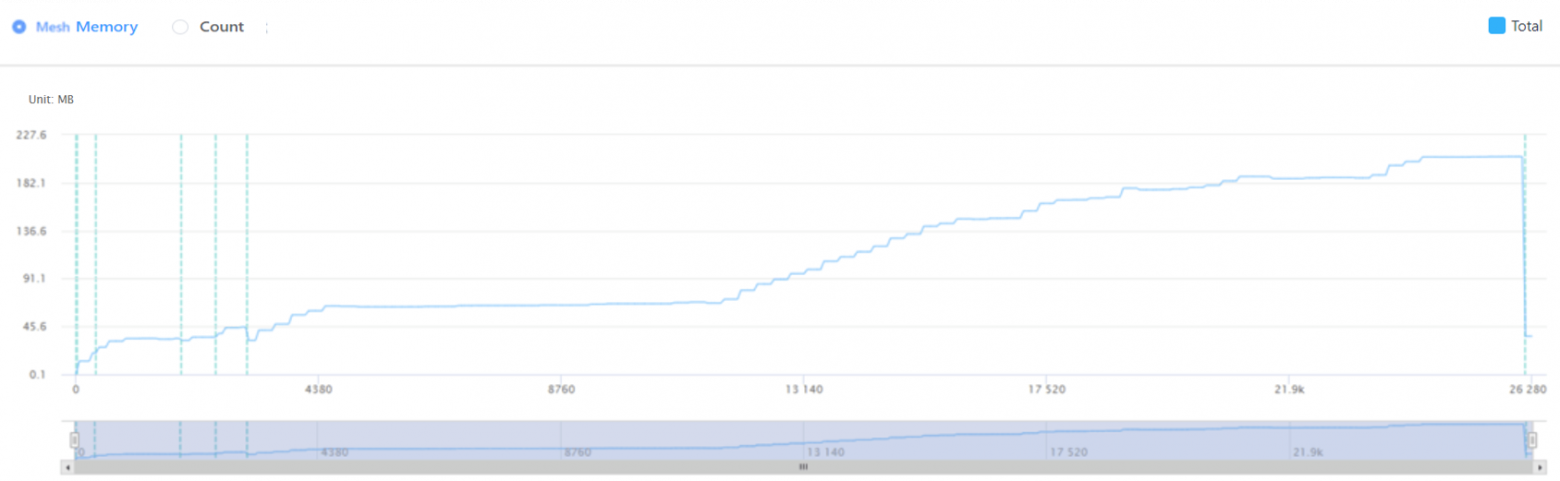
 Since 2011 all Intel GPUs (integrated and discrete Intel Graphics products) include Intel Quick Sync Video (QSV) — the dedicated hardware core for video encoding and decoding. Intel QSV is supported by all popular video processing applications across multiple OSes including
Since 2011 all Intel GPUs (integrated and discrete Intel Graphics products) include Intel Quick Sync Video (QSV) — the dedicated hardware core for video encoding and decoding. Intel QSV is supported by all popular video processing applications across multiple OSes including 

















