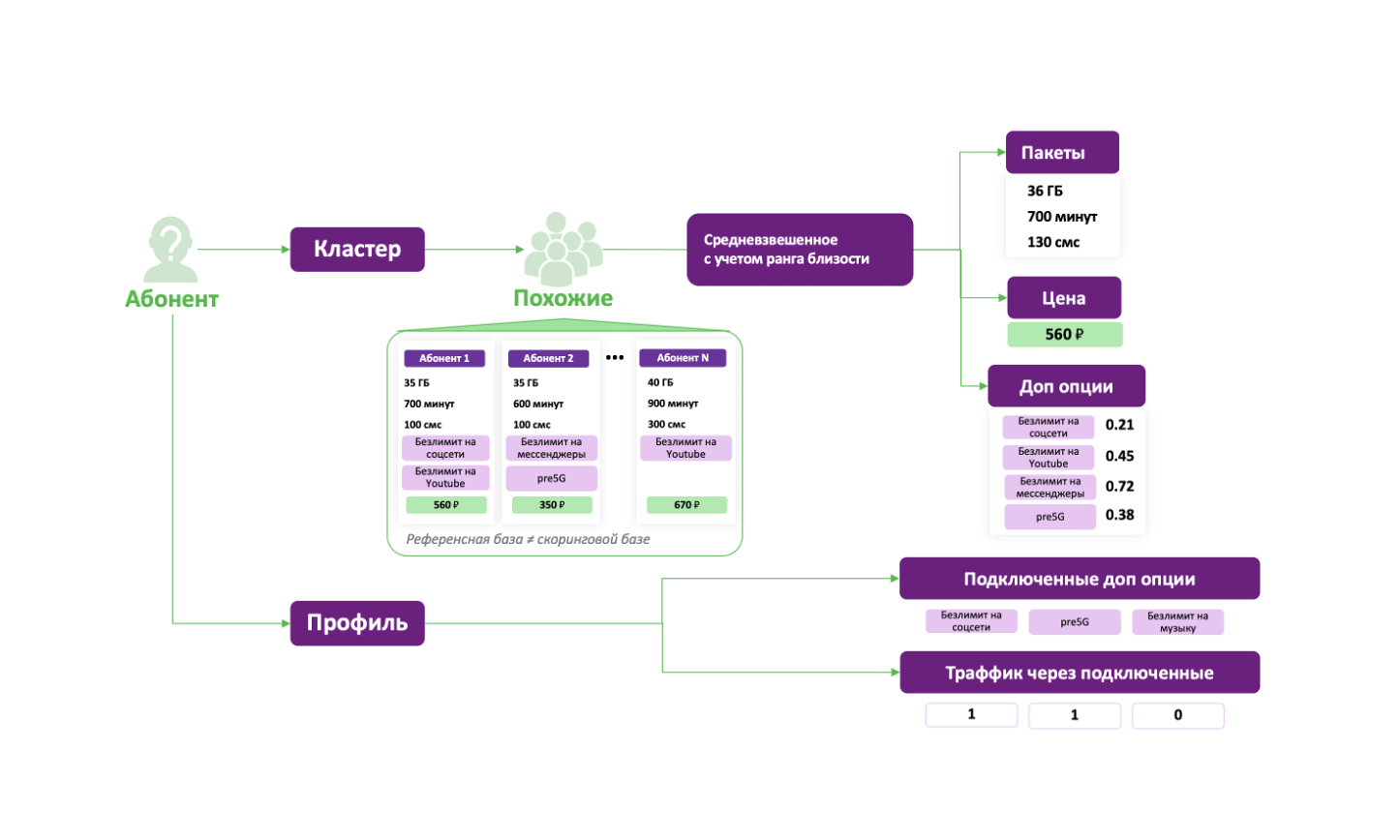
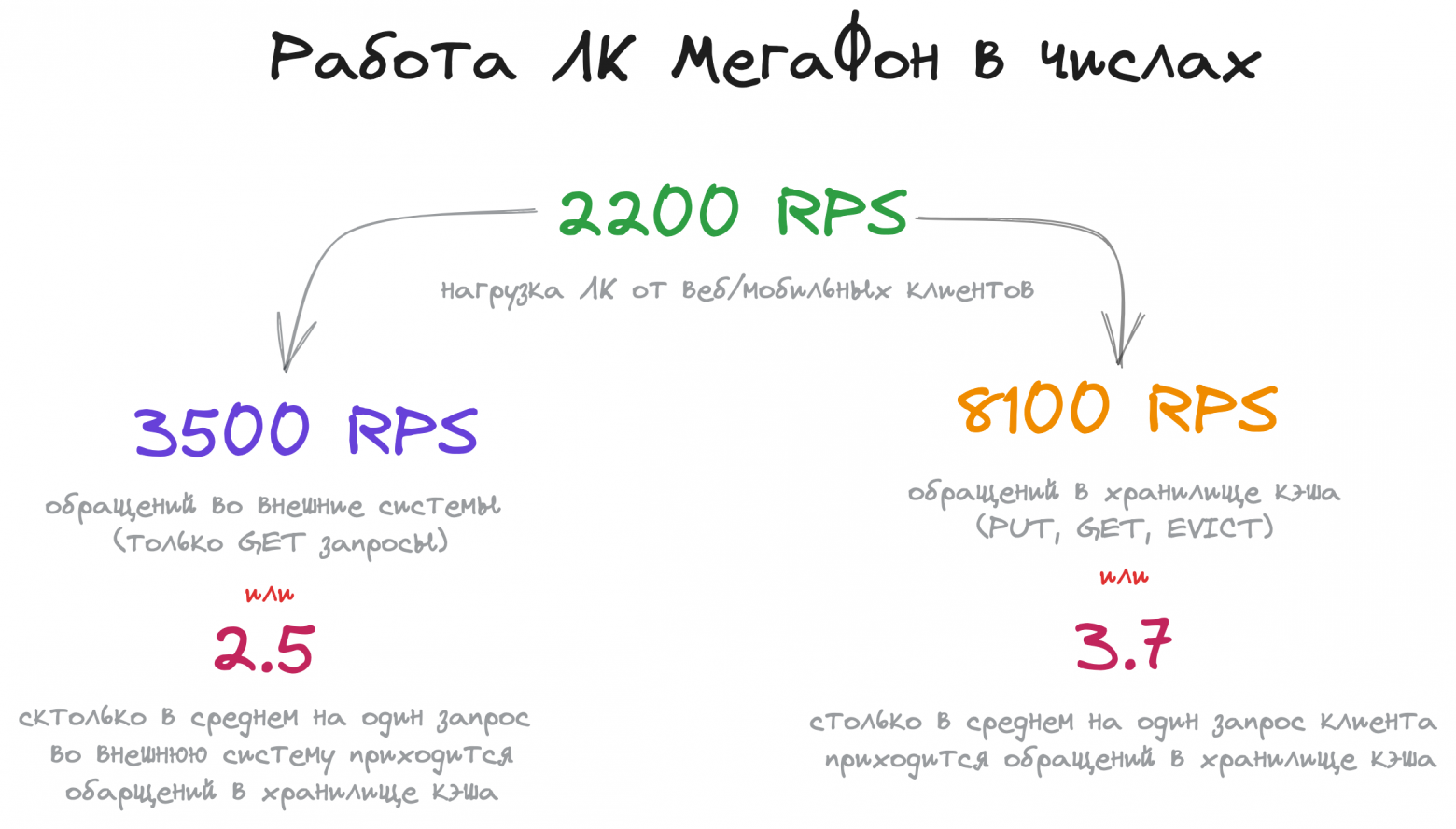
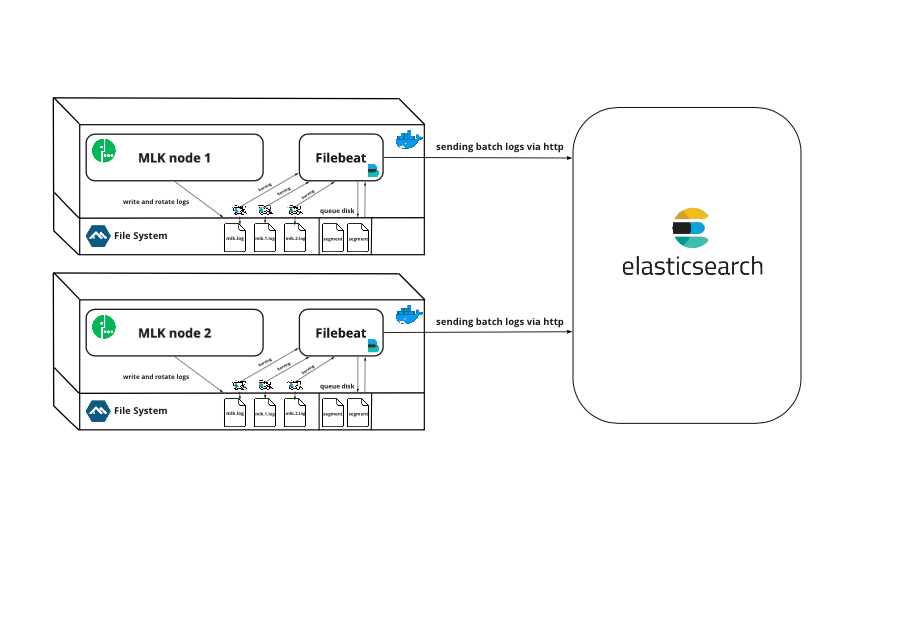
Мы привыкли, что Machine Learning предоставляет нам большое количество предиктивных методов, которые с каждым годом предсказывают события лучше и лучше. Деревья, леса, бустинги, нейронные сети, обучение с подкреплением и другие алгоритмы машинного обучения позволяют предвидеть будущее все более отчетливо. Казалось бы, что нужно еще? Просто улучшать методы и тогда мы рано или поздно будем жить в будущем так же спокойно, как и в настоящем. Однако не все так просто.
Когда мы рассматриваем бизнес задачи, мы часто сталкиваемся с двумя моментами. Во-первых, мы хотим понять что к чему относится и что с чем связано. Нам важна интерпретация. Чем сложнее модели мы используем, тем более нелинейные они. Тем больше они похожи на черную коробку, в которой очень сложно выявить связи, понятные человеческому разуму. Все же мы привыкли мыслить довольно линейно или близко к тому. Во-вторых, мы хотим понять - если мы подергаем вот эту "ручку", изменится ли результат в будущем и насколько? То есть, мы хотим увидеть причинно-следственную связь между нашим целевым событием и некоторым фактором. Как сказал Рубин - без манипуляции нет причинно следственной связи. Мы часто ошибочно принимаем обыкновенную корреляцию за эту связь. В этой серии статей мы сконцентрируемся на причинах и следствиях.
Но что не так с привычными нам методами ML? Мы строим модель, а значит, предсказывая значение целевого события мы можем менять значение одного из факторов - одной из фич и тогда мы получим соответствующее изменение таргета. Вот нам и предсказание. Все не так просто. По конструкции, большинство ML методов отлично выявляют корреляцию между признаком и таргетом, но ничего не говорят о том, произошло ли изменение целевого события именно из-за изменения значения фичи. То есть, ничего не говорят нам о том - что здесь было причиной, а что следствием.