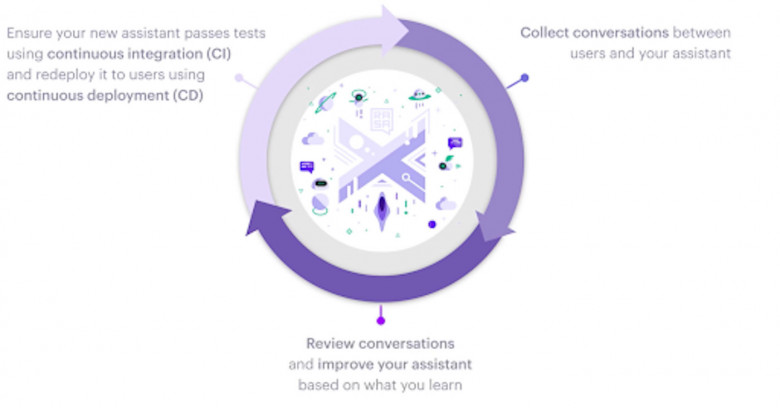
Наверняка вы слышали о нашумевшей в своё время ИИ стримерше NeuroSama. Однако мое внимание привлекало не само шоу и эти нашумевшие самые «крутейшие» моменты стримов, а сам факт того, что нейросеть реально может полностью автономно и полноценно вести стрим, удерживая внимание зрителей! Меня очень заинтересовала такая задумка, и я решился её повторить!
В этой статье я расскажу о попытке создать свою нейро-тян для русского сегмента, которая сможет автономно и без перерывов играть и вести трансляции на различных стриминг-платформах и буллить кожаных мешков конечно же развлекать зрителей и игроков, не получая баны! В результате получился самый настоящий гомункул киборг-убийца (мозгов) квадратных людей, поэтому запасайтесь бочкой кваса и ванной попкрона, как и в прошлый раз, приключение обещает быть жарким, но не только потому, что скоро лето, а ещё потому, что сейчас весна (и сопутствующее весеннее обострение), ведь мы с вами будем создавать настоящую (виртуальную) девушку-стримера!
Может, немного опоздал с трендом, но не пропадать же добру просто так! Кому-нибудь да пригодится (хотя бы для того, чтобы посмеяться или кринжануть с человека, который год занимался никому не нужной фигнёй).
Статья получилась без преувеличения огромной из-за совмещения просто ТУЧИ разных технологий и необходимости погружения в тонкости некоторых, так что отправьте ссылку себе на комп, расположитесь поудобнее и предупредите свою попу, что она рискует не отрываться от стула на протяжении целого часа!
Будет весело, сложно и очень интересно как опытному «бойцу», так и простому обывателю!