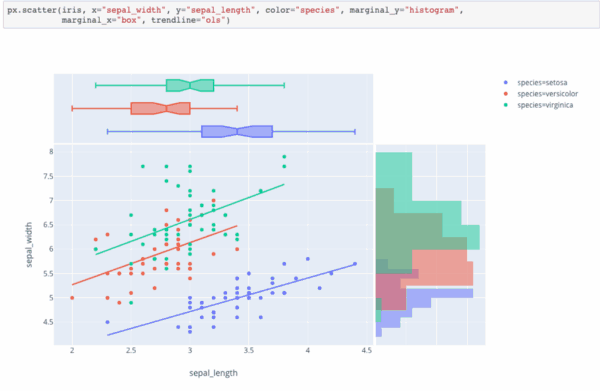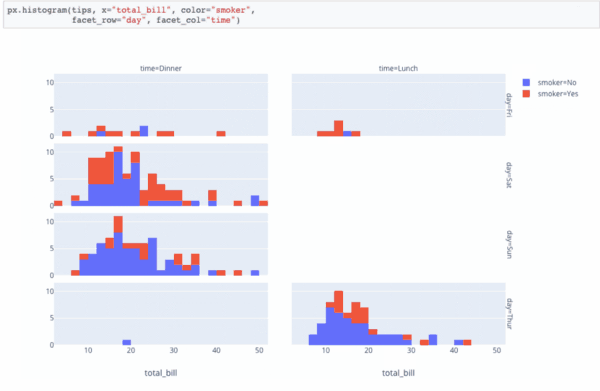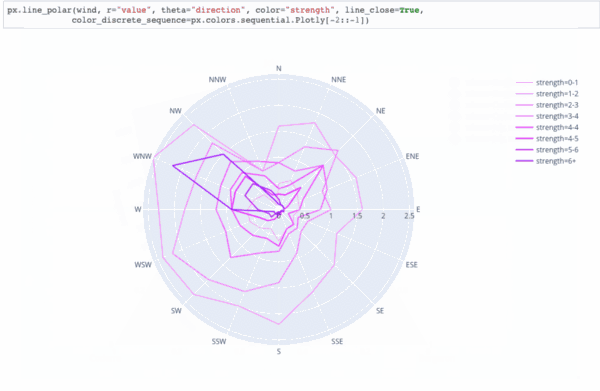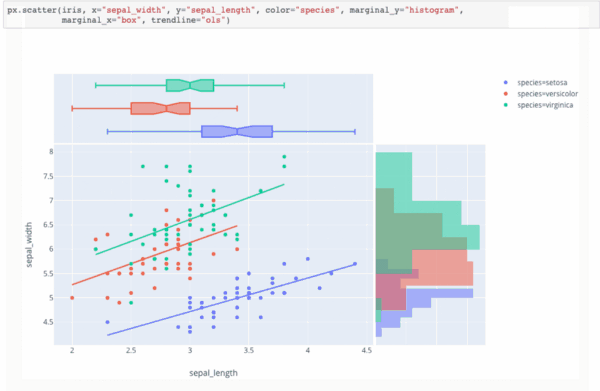
Привет, Хабр.
Меня зовут Алексей Кнорре, и я криминолог, аспирант в UPenn и аффилированный научный сотрудник в ЕУСПб. Подумал, что сейчас, после месяцев карантина, самое время рассказать о преступности. Неясная экономическая ситуация, рост безработицы, ухудшение общественного здоровья — все это вызывает опасения в завтрашнем дне. Что будет с преступностью в России? Как криминолог, я использую статистические методы и программирование для того, чтобы эмпирически исследовать преступность, поэтому я постоянно работаю с данными, о которых сегодня и хотел бы рассказать доступным языком. На Хабре
было всего два поста по тегу «криминология», поэтому надеюсь, мой рассказ будет интересным.
Кто-то из вас мог видеть в прошлом году
рейтинг безопасности городов России. Как собирали данные о безопасности: вроде бы был опрос жителей, но сколько человек опросили? Не было ли в выборке систематических смещений, как если бы опрашивали только жителей больших многоквартирных домов? Насколько вообще люди могут точно сказать, что в их городе в целом безопасно? Безопасно по сравнению с чем, и как эту безопасность измерить? А вдруг анкетный опрос отражает больше общественные настроения, нежели реальную преступность — вероятность случайного нападения на улице, грабежа или кражи?
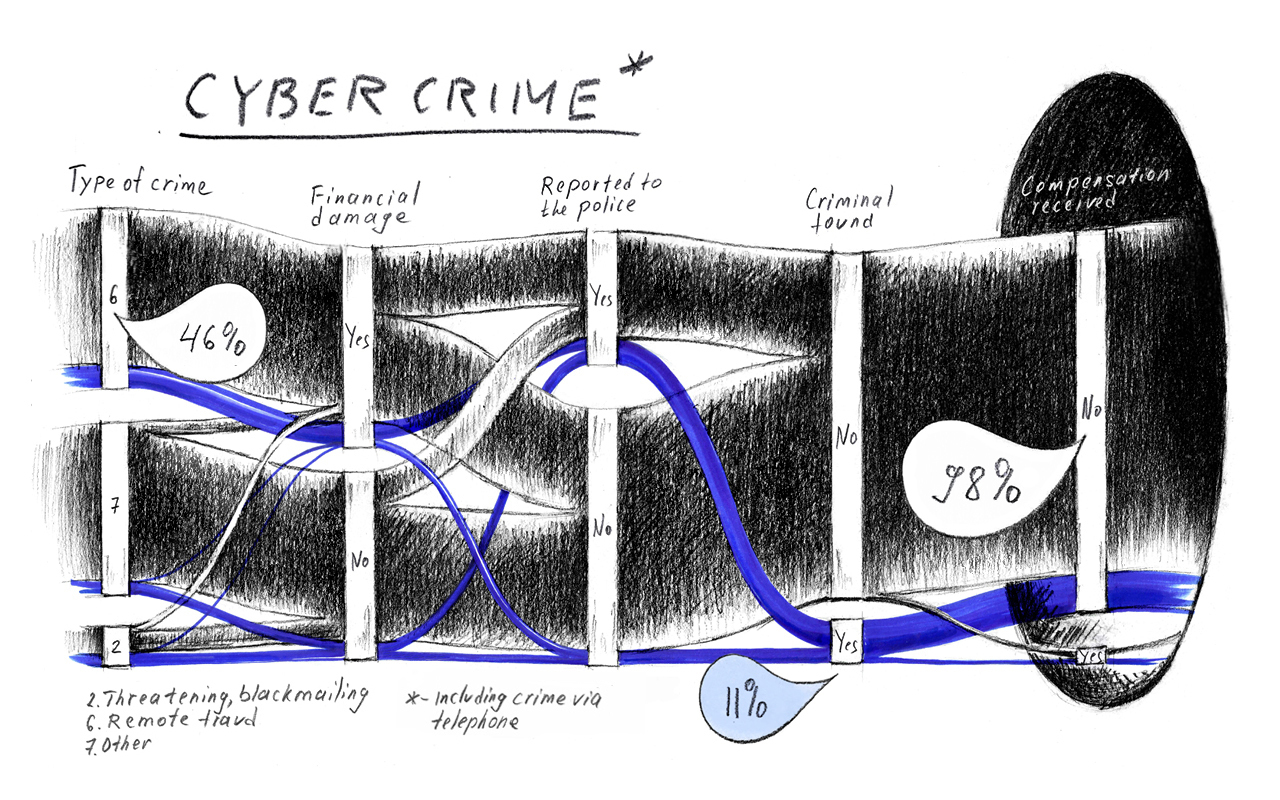
В науке преступность измеряют разными способами. Два года назад мы с коллегами, например, провели первый в России репрезентативный виктимизационный опрос, обзвонив 16 тыс. человек.
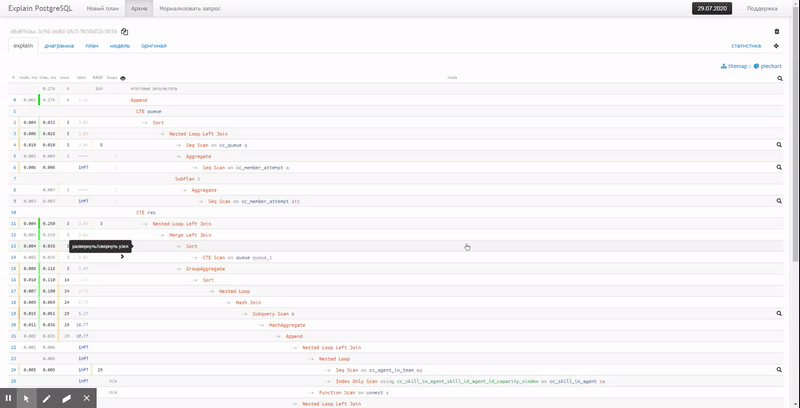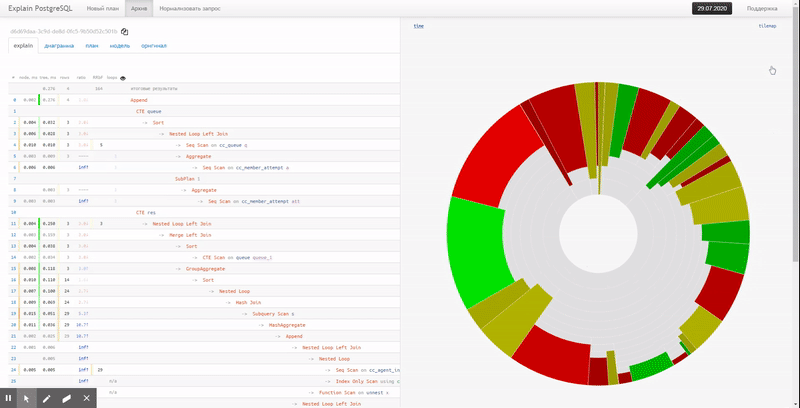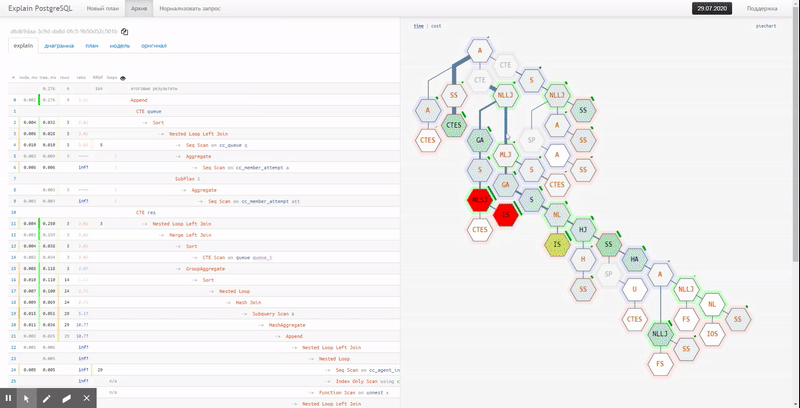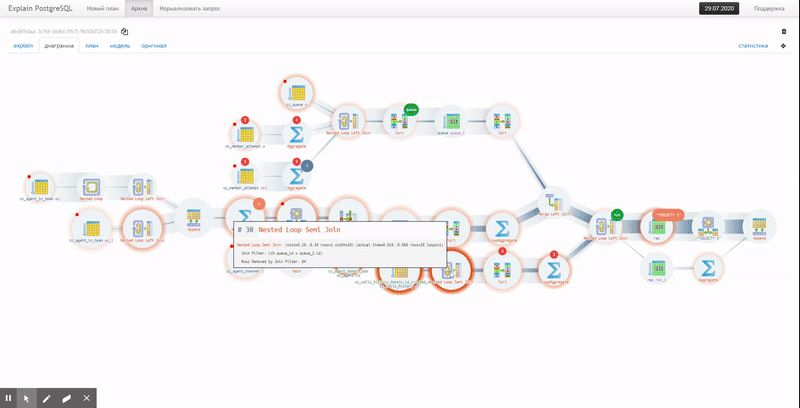
Данные мы открыли для общего пользования. Основной вывод — уровень реальной преступности где-то в 8 раз выше регистрируемой правоохранительными органами. Вот визуализация процесса от Марии Бублик и Натальи Тогановой, вошедшая в шорт-лист премии
Information is Beautiful — 2019.