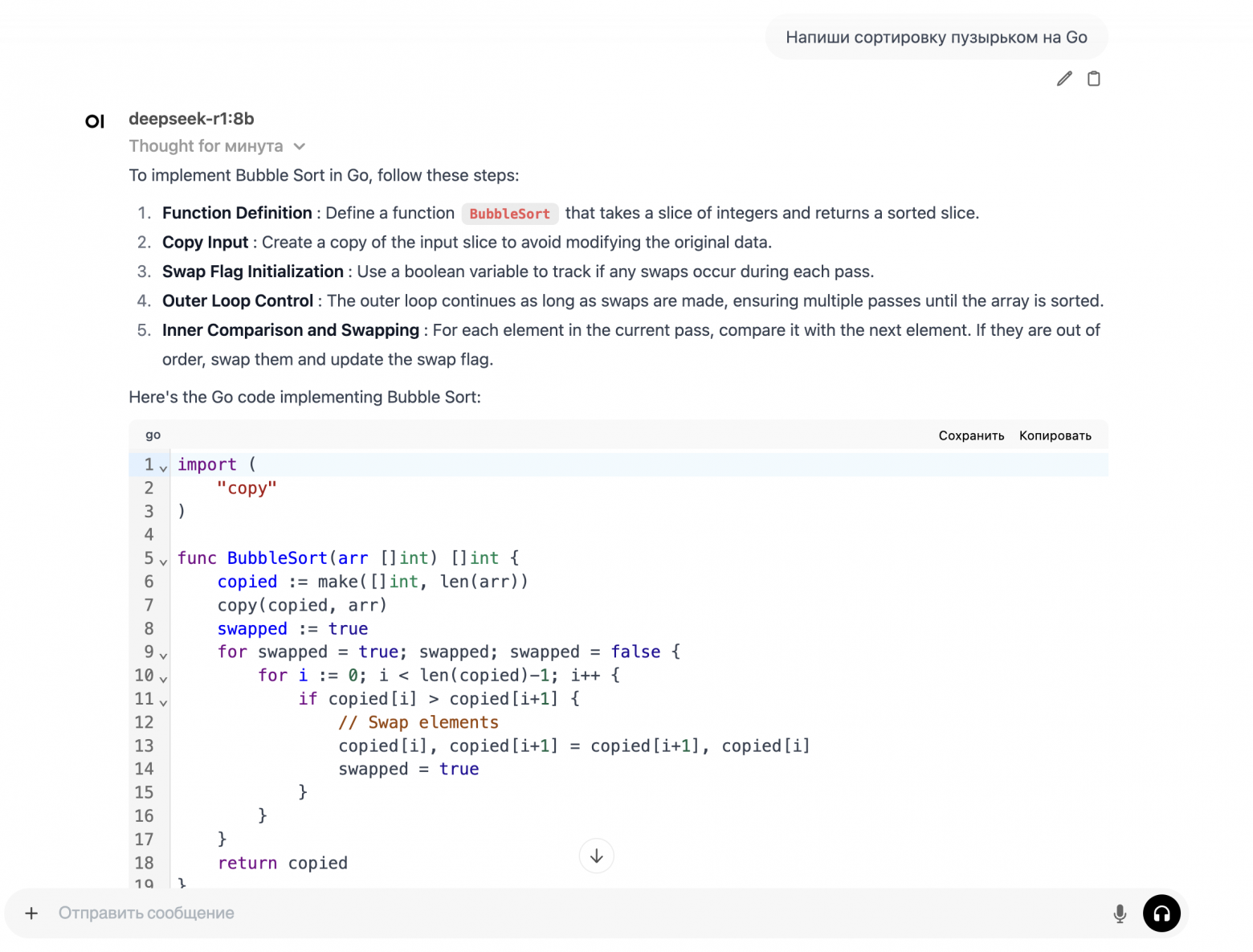
Итак, группа исследователей создала платформу MathArena, где планируют делиться отчётами о сравнении нейросетей в различных математических проблемах. Для начала множество моделей уже протестировали на AIME 2025 I, олимпиаде, прошедшей в четверг.
Что такое AIME? American Invitational Mathematics Examination — элитное математическое состязание, проводимое с 1983 года. Существует две версии теста — AIME I и AIME II, но каждый участник может пройти только одну (хотя ИИ-моделям повезло, и вскоре появятся результаты для второй части). Олимпиада состоит из 15 задач, сложность которых возрастает.
Каждую модель тестировали по четыре раза на каждой задаче, вычисляя средний балл (столбец Acc — accuracy) и финансовую стоимость вычислений (столбец Cost). Для удобства использовалась цветовая кодировка: 🟩зелёный — задача решена в более чем 75% случаев; 🟨жёлтый — успех в 25–75% случаев; 🟥красный — модель справилась менее чем в 25% попыток. Щелчком по клетке можно открыть условие задачи, ход рассуждений модели в каждом из четырёх подходов и финальные ответы.
🏆o3-mini-high от OpenAI показала впечатляющий результат — 80% решённых задач при очень низкой стоимости вычислений.
🔹DeepSeek-r1, лидер среди опенсорс-моделей, набрал 65%, а его дистиллированные версии тоже продемонстрировали достойные результаты. (Кстати, уже пробовали запустить его в нашем агрегаторе нейросетей?)
Можно заметить, что дистилляты хоть и уступают своим полным аналогам, но не так уж сильно: сжатие DeepSeek-r1 с 671 млрд параметров до 70 или даже 14 млрд привело к падению эффективности в обоих случаях всего на 15%. То есть урезанная модель становится заметно легче, но при этом сохраняет бóльшую часть своих возможностей.
К сожалению, Claude 3.5 Sonnet, модель июня 2024-го, оказалась на дне рейтинга. Однако её сильная сторона явно не в этом — огромное контекстное окно (200 000 токенов) делает модель отличным инструментом для программирования. Кодеры подтверждают, что она хорошо генерирует длинные и сложные фрагменты кода.
Пока что в тестах не замечено семейства Phi. Phi-4 набирает 80%+ на сложнейших бенчмарках, таких как MATH, уверенно обходя Gemini Pro и GPT-4o-mini. Посмотрим, добавят ли авторы сайта её в дальнейшем🤔
Тем временем пользователи X забили тревогу и решили проверить честность олимпиады, задействовав свежачок от OpenAI — Deep Research. Цель? Выяснить, не мелькали ли эти задачки где-то в Сети раньше и, соответственно, не могли ли их решения заранее попасть в обучающие данные моделей. Ведь если так, то модели получали преимущество.
Нашлось ли что-то подозрительное? Как оказалось, похожие задачи действительно уже обсуждались на форумах.
Задача № 1: найти сумму всех целых оснований b > 9, для которых одно число делится на другое в системе счисления b. Аналогичное задание всплыло на Quora. Однако и различия существенны: на форуме просто рассматривались все возможные значения b, удовлетворяющие делимости, а в олимпиадном варианте — только те, которые больше 9. Это заметно сужает поиск и усложняет задачу.
Задача № 3: найти остаток от деления количества возможных распределений мороженого между игроками с заданными ограничениями. Deep Research нашёл похожую концепцию: обе задачи связаны с разбиением числа на несколько частей с учётом ограничений. Но здесь тоже есть нюансы: в олимпиадной версии обязательно, чтобы каждый из трёх вкусов достался хотя бы одному игроку, причём количество игроков, выбравших каждый вкус, подчиняется неравенству c > v > s. Более того, порядок распределения важен, что добавляет ещё один уровень сложности.
Итог. Похожие? Да. Идентичные? Нет. Найти аналоги почти любой задачи в интернете реально, если искать достаточно хорошо. Так что сказать, что модели видели точно такие же задачи, нельзя.