Spring Boot vs Spring MVC vs Spring — Как они сравниваются?

Spring, Spring Boot, Spring MVC, везде есть слово “spring”! Давайте пройдемся где и когда вы можете применять каждый из этих инструментов
В этой статье, вы увидите обзоры: Spring, Spring MVC, и Spring Boot, узнаете какие проблемы они решают, и где они лучше всего применимы. Самый важный в факт что вы узнаете, является тем что Spring, Spring MVC, и Spring Boot не конкурируют за одно и то же место. Они решают разные проблемы, и они решают их очень хорошо.
Что за основная проблема, которую этот Spring Framework решает?
Долго и упорно подумайте. Какова проблема, решаемая Spring Framework?
Почему это важно? Потому что, когда DI или IOC правильно используются, мы можем разрабатывать слабо связанные приложения. А слабо связанные приложения могут быть легко протестированы юнит-тестами.
Давайте рассмотрим простой пример.
Пример без внедрения зависимостей
Рассмотрим пример ниже: WelcomeController зависит от WelcomeService, чтобы получить приветственное сообщение. Что он делает, чтобы получить экземпляр WelcomeService?
WelcomeService service = new WelcomeService();
Эта строка создает экземпляр данного сервиса. А это значит что они сильно связаны. Например, если я создаю мок для WelcomeService в юнит-тесте для WelcomeController, как мне заставить WelcomeController использовать мок? Не легко!
@RestController
public class WelcomeController { private WelcomeService service = new WelcomeService(); @RequestMapping("/welcome")
public String welcome() {
return service.retrieveWelcomeMessage();
}
}

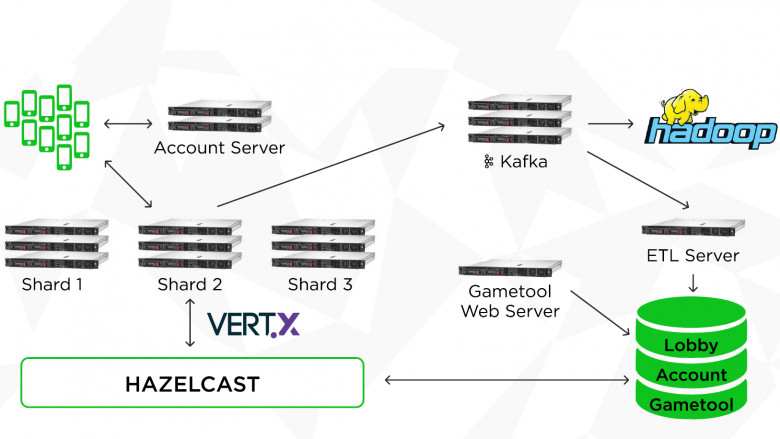

 Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.
Эта статья содержит краткую выжимку из моего собственного опыта и опыта моих коллег, с которыми мне днями и ночами доводилось разгребать инциденты. И многих инцидентов не возникло бы никогда, если бы всеми любимые микросервисы были написаны хотя бы немного аккуратнее.

 В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.
В последние два месяца лета в управлении хранилищ данных (Data Warehouse, DWH) Тинькофф Банка появилась новая тема для кухонных споров.