22 июня автор курса
«Разработчик C++» в Яндекс.Практикуме Георгий Осипов провёл вебинар
«Вычисляем на видеокартах. Технология OpenCL».
Мы подготовили для вас его текстовую версию, для удобства разбив её на смысловые блоки.
- 0 (вводная часть). Зачем мы здесь собрались. Краткая история GPGPU.
- 1. Пишем для OpenCL.
- 2. Алгоритмы в условиях массового параллелизма.
- 3. Сравнение технологий.
Основная цель цикла — написать простую, но полноценную программу на OpenCL и объяснить базовые понятия. Программу на OpenCL напишем уже в следующей части цикла, понять которую можно, не читая вводную. Однако во вводной вы найдёте понятия и тезисы, важные при программировании с OpenCL.
Цикл будет полезен и тем, кто уже знаком с OpenCL: в нём мы поделимся некоторыми хаками и неочевидными наблюдениями из собственного опыта.
CPU — в помойку?
В статье будем рассматривать технологию GPGPU. Разберёмся, что значат все эти буквы. Начнем с последних трёх — GPU. Все знают аббревиатуру CPU — Central Processor Unit, или центральный процессор. А GPU — Graphic Processor Unit. Это графический процессор. Он предназначен для решения графических задач.
Но перед GPU есть ещё буквы GP. Они расшифровываются как General-Purpose. В аббревиатуре опускают словосочетание Computing on. Если собрать всё вместе, получится General-Purpose Computing on Graphic Processor Unit, что по-русски — вычисления общего назначения на графическом процессоре.
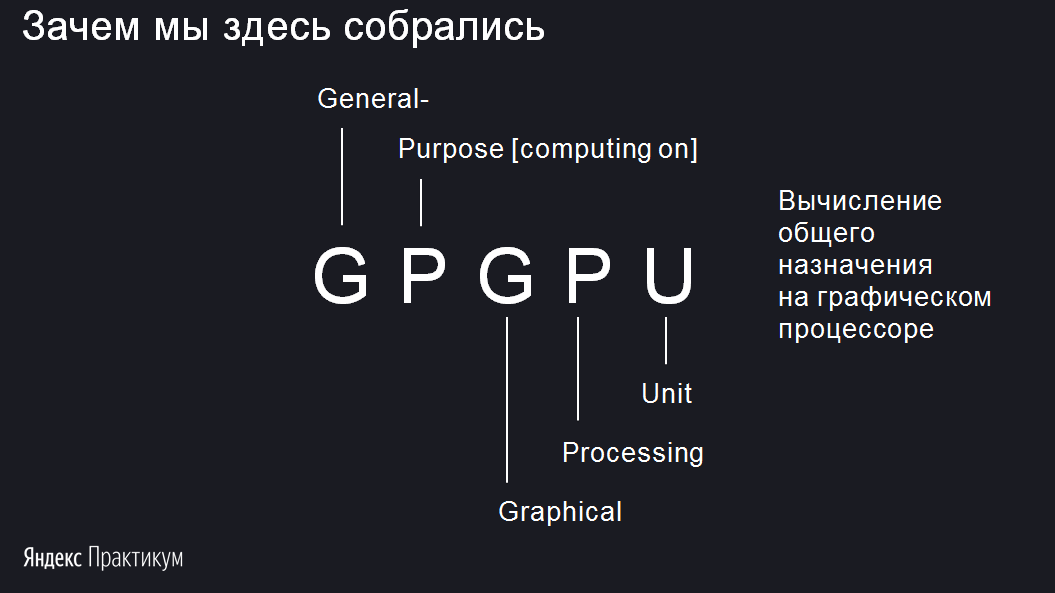
То есть процессор графический, но мы почему-то хотим вычислять на нём что-то, что вообще к графике никакого отношения не имеет. Например, прогноз погоды, майнинг биткоинов. Моя задача в ближайшее время — объяснить, зачем нужно на процессоре для графики обучать, например, нейросети.