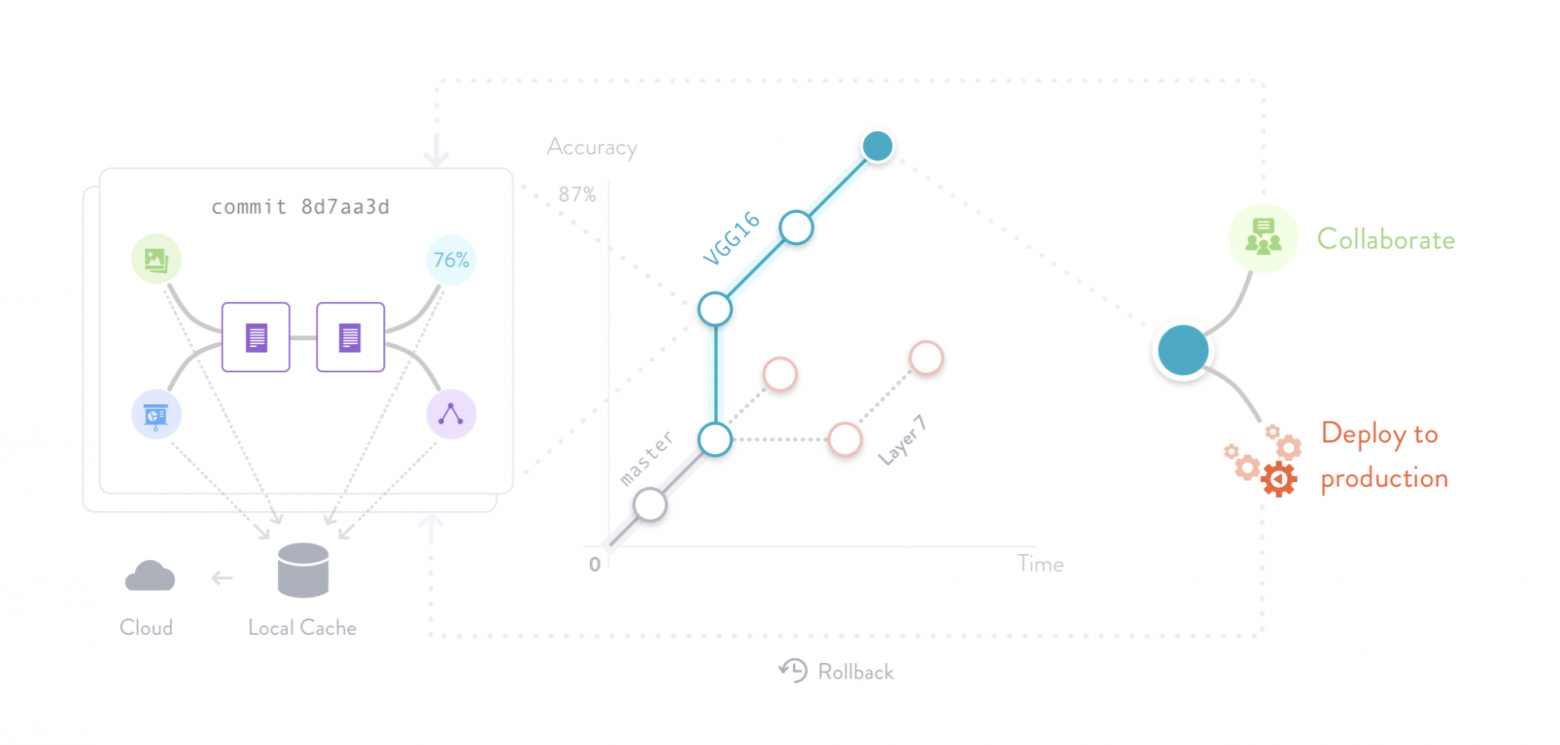
Data-science развивается очень быстро, в том числе благодаря росту объема доступных данных для анализа или построения моделей. Но для создания сложных моделей командам аналитиков нужно работать совместно и эффективно управлять большими датасетами. И вот здесь может помочь, например, DVC — open-source система контроля версий для проектов машинного обучения.
Нашел не так много информации по ней в рунете, поэтому под катом на примере простого ML-проекта расскажу, как работать с инструментом для хранения и обновления датасета.