Deleted Deleted

Пользователь
Как выжить Инди разработчику. Часть 1
11 мин
Прим. перев.: Здравствуйте, уважаемые хабровчане!
Хочу с вами поделиться историей инди-разработчика Jake Birkett, рассказанной им на конференции Independent Games в 2016. Выступление Джейка — это глубоко личная, полная деталей повесть о длинном и сложном пути в игровой индустрии. Перевод сделан с видеозаписи выступления. По всем ошибкам и неточностям, пожалуйста, пишите в личку. Спасибо!

К сожалению, это пугающая реальность для большинства из нас. И чем скорее вы признаете этот факт, тем быстрее начнете думать как выжить будучи Инди-разработчиком. И чем дольше вы будете на рынке, тем больше шансов сделать стоящую игру и возможно, когда-нибудь, выпустить хит.
Хочу с вами поделиться историей инди-разработчика Jake Birkett, рассказанной им на конференции Independent Games в 2016. Выступление Джейка — это глубоко личная, полная деталей повесть о длинном и сложном пути в игровой индустрии. Перевод сделан с видеозаписи выступления. По всем ошибкам и неточностям, пожалуйста, пишите в личку. Спасибо!
Часть первая
Ты никакой не избранный, твоя игра не хит и ты его никогда не сделаешь
К сожалению, это пугающая реальность для большинства из нас. И чем скорее вы признаете этот факт, тем быстрее начнете думать как выжить будучи Инди-разработчиком. И чем дольше вы будете на рынке, тем больше шансов сделать стоящую игру и возможно, когда-нибудь, выпустить хит.
От установки AWX до запуска первого плейбука — настройка централизованного управления Ansible
9 мин
Туториал

Количество серверов в нашей инфраструктуре уже перевалило за 800, хотя еще год назад их было около 500. Для работы с этим всем активно используются решения от Red Hat. Про FreeIPA — для организации и управления доступами для Linux-серверов — мы уже писали, сейчас же я хочу затронуть тему управления конфигурациями. Для этих целей у нас юзается Ansible, а с недавних пор к нему добавился AWX — представленное полгода назад решение для централизованного управления плейбуками, расписанием их запусков, управления инвентори, учетными данными для доступа к серверам, а также механизм callback'ов для запроса конфигураций со стороны сервера.
Из-за ряда вещей мы не сразу смогли интегрировать его для работы с нашим основным проектом War Robots, но полей для проверки AWX нашлось предостаточно. Во-первых, в компании ведутся разработки новых проектов, которым нужны dev/stage-окружения и, само собой, production-окружения в перспективе. А недавно к этому добавился еще и проект для внутренней аналитики, которому потребовался полностью новый кластер.
Итак, начнём!
Дюжина приемов в Linux, которые действительно сэкономят уйму времени
9 мин

Эта статья также есть на английском.
Однажды вечером, перечитывая Джеффри Фридла, я осознал, что даже несмотря на всем доступную документацию, существует множество приемов заточенных под себя. Все люди слишком разные. И приемы, которые очевидны для одних, могут быть неочевидны для других и выглядеть какой-то магией для третьих. Кстати, несколько подобных моментов я уже описывал здесь.
Командная строка для администратора или пользователя — это не только инструмент, которым можно сделать все, но и инструмент, который кастомизируется под себя любимого бесконечно долго. Недавно пробегал перевод на тему удобных приемов в CLI. Но у меня сложилось впечатление, что сам переводчик мало пользовался советами, из-за чего важные нюансы могли быть упущены.
Под катом — дюжина приемов в командной строке — из личного опыта.
Наш рецепт отказоустойчивого VPN-сервера на базе tinc, OpenVPN, Linux
9 мин
Туториал

Один из наших клиентов попросил разработать отказоустойчивое решение для организации защищенного доступа к его корпоративному сервису. Решение должно было:
- обеспечивать отказоустойчивость и избыточность;
- легко масштабироваться;
- просто и быстро решать задачу добавления и блокировки пользователей VPN;
- балансировать нагрузку между входными нодами;
- одинаково хорошо работать для клиентов на GNU/Linux, Mac OS X и Windows;
- поддерживать клиентов, которые находятся за NAT.
Готовых решений, удовлетворяющих всем поставленным условиям, не нашлось. Поэтому мы собрали его на базе популярных Open Source-продуктов, а теперь с удовольствием делимся полученным результатом в этой статье.
DNS сервер BIND (теория)
21 мин
Основная цель DNS — это отображение доменных имен в IP адреса и наоборот — IP в DNS. В статье я рассмотрю работу DNS сервера BIND (Berkeley Internet Name Domain, ранее: Berkeley Internet Name Daemon), как сАмого (не побоюсь этого слова) распространенного. BIND входит в состав любого дистрибутива UNIX. Основу BIND составляет демон named, который для своей работы использует порт UDP/53 и для некоторых запросов TCP/53.
Исторически, до появления доменной системы имен роль инструмента разрешения символьных имен в IP выполнял файл /etc/hosts, который и в настоящее время играет далеко не последнюю роль в данном деле. Но с ростом количества хостов в глобальной сети, отслеживать и обслуживать базу имен на всех хостах стало нереально затруднительно. В результате придумали DNS, представляющую собой иерархическую, распределенную систему доменных зон. Давайте рассмотрим структуру Системы Доменных Имён на иллюстрации:
Основные понятия Domain Name System
Исторически, до появления доменной системы имен роль инструмента разрешения символьных имен в IP выполнял файл /etc/hosts, который и в настоящее время играет далеко не последнюю роль в данном деле. Но с ростом количества хостов в глобальной сети, отслеживать и обслуживать базу имен на всех хостах стало нереально затруднительно. В результате придумали DNS, представляющую собой иерархическую, распределенную систему доменных зон. Давайте рассмотрим структуру Системы Доменных Имён на иллюстрации:
GitLab Flow
15 мин
Перевод
Это перевод достаточно важной статьи про GitLab Flow, альтернативе Git flow и GitHub flow. Статья была написана в 2014, так что скриншоты успели устареть. Тем не менее сама статья более чем актуальна:
Ветвление и слияние веток в git устроено гораздо проще, чем в более ранних системах контроля версий, таких как SVN. Поэтому есть много способов организации командной работы над кодом, и большинство из них достаточно хороши. По крайней мере, они дают много преимуществ по сравнению с тем, что было до git. Но сам по себе git — не серебряная пуля, и во многих командах организация рабочего процесса с git имеет ряд проблем:
- Не описан точным образом весь рабочий процесс,
- Вносится ненужная сложность,
- Нет связи с трекером задач (issue tracker).
Мы хотим представить вам GitLab flow — чётко определённый набор практик, решающий эти проблемы. Он объединяет в одну систему:
- Практику разработки, управляемой функциональностью (feature driven development),
- Использование feature-веток (feature branches),
- Трекер задач.
ssh: Вытаскиваем для себя чужой порт из-за NAT
2 мин

Что делает ssh -R © erik, unix.stackexchange.com
Подключиться к сервису за NAT, имея человека рядом с сервисом, вооруженного ssh, и белый ip у себя.
Опция -R
В ssh есть режим, в котором он открывает порт на сервере и, через туннель от сервера до клиента, перенаправляет соединения в указанный адрес в сети клиента.
То есть нам нужно поднять sshd, попросить человека выполнить
$ ssh -N -R server_port:target:target_port sshd_server
И у нас на машине с sshd откроется порт server_port, который будет туннелироваться в target:target_port в сети этого человека.
Как в sshd_config ограничить права
Как не хранить секреты где придётся, или зачем нам Hashicorp Vault
11 мин
Туториал

Задайте себе вопрос — как правильно хранить пароль от базы данных, которая используется вашим сервисом? В отдельном репозитории с секретами? В репозитории приложения? В системе деплоя (Jenkins, Teamcity, etc)? В системе управления конфигурациями? Только на личном компьютере? Только на серверах, на которых работает ваш сервис? В некоем хранилище секретов?
Зачем об этом думать? Чтобы минимизировать риски безопасности вашей инфраструктуры.
Начнём исследование вопроса с определения требований к хранению секретов.
Управление контейнерами с runC
6 мин
Туториал

Продолжаем цикл статей о контейнеризации. Сегодня мы поговорим о runC — инструменте для запуска контейнеров, разрабатываемом в рамках проекта Open Containers. Цель этого проекта заключается в разработке единого стандарта в области контейнерных технологий. Проект поддерживают такие компании, как Facebook, Google, Microsoft, Oracle, EMC, Docker. Летом 2015 года был опубликован черновой вариант спецификации под названием Open Container Initiative (OCI).
Systemd и контейнеры: знакомство с systemd-nspawn
8 мин

Контейнеризация сегодня — одна из самых актуальныx тем. Количество публикаций о таких популярных инструментах, как LXC или Docker, исчисляется тысячами, если не десятками тысяч.
В этой статье бы хотели мы обсудить ещё одно решение, о котором публикаций на русском языке пока что мало. Речь идёт о systemd-nspawn — инструменте для создания изолированных сред, который является одним из компонентов systemd. А закрепление systemd в качестве стандарта в мире Linux — уже свершившийся факт. В свете этого факта есть все основания полагать, что в ближайшее время сфера применения systemd-nspawn существенно расширится, и познакомиться с этим инструментом поближе стоит уже сейчас.
Пулы потоков: ускоряем NGINX в 9 и более раз
15 мин
Перевод
Как известно, для обработки соединений NGINX использует асинхронный событийный подход. Вместо того, чтобы выделять на каждый запрос отдельный поток или процесс (как это делают серверы с традиционной архитектурой), NGINX мультиплексирует обработку множества соединений и запросов в одном рабочем процессе. Для этого применяются сокеты в неблокирующем режиме и такие эффективные методы работы с событиями, как epoll и kqueue.
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
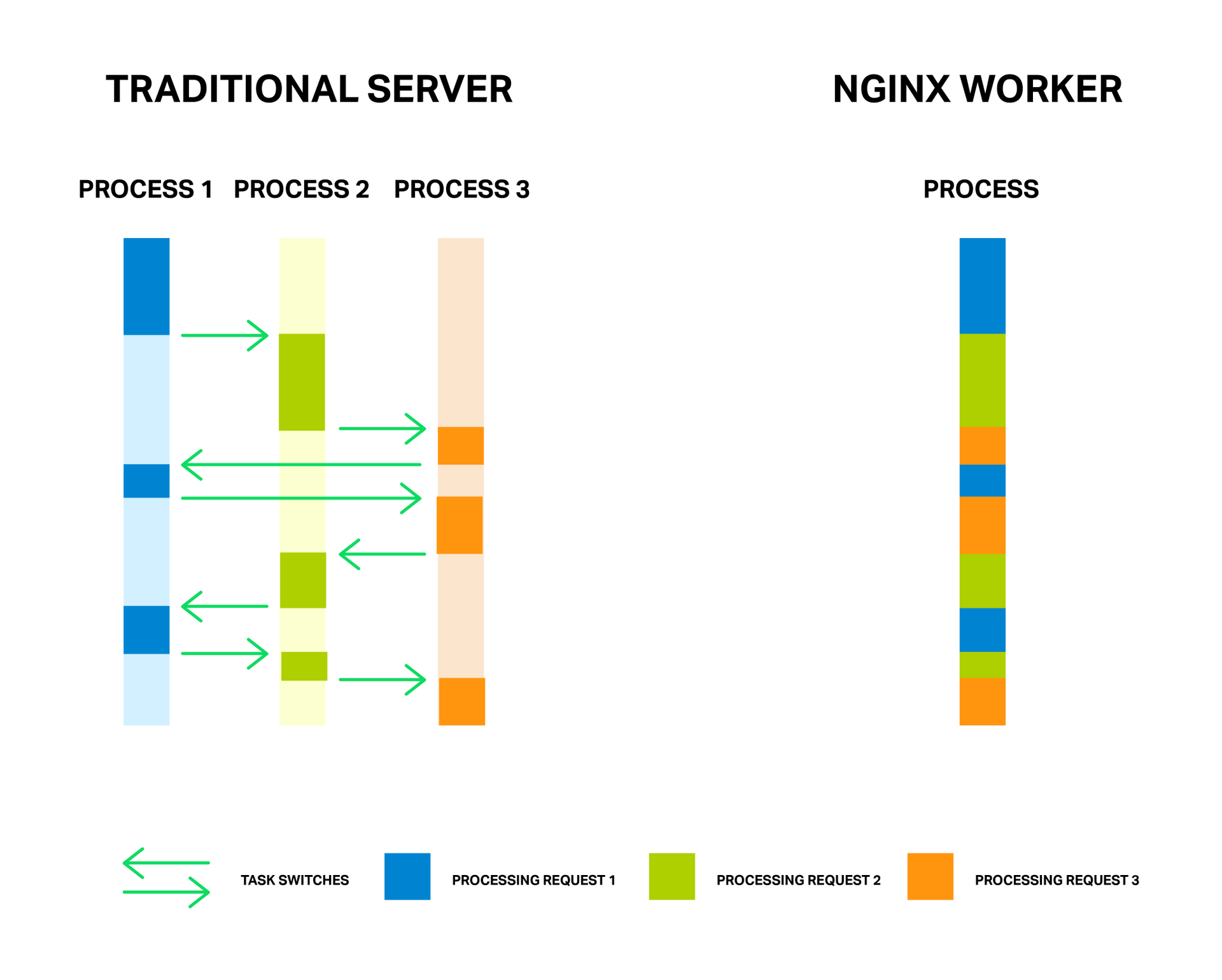 Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
Каждый процесс расходует память и каждое переключение между ними требует дополнительных циклов процессора, а также приводит к вымыванию L-кэшей
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
За счет малого и постоянного количества полновесных потоков обработки (обычно по одному на ядро) достигается экономия памяти, а также ресурсов процессора на переключении контекстов. Все преимущества данного подхода вы можете хорошо наблюдать на примере самого NGINX, который способен обрабатывать миллионы запросов одновременно и хорошо масштабироваться.
У медали есть и обратная сторона. Главной проблемой асинхронного подхода, а лучше даже сказать «врагом» — являются блокирующие операции. И, к сожалению, многие авторы сторонних модулей, не понимая принципов функционирования NGINX, пытаются выполнять блокирующие операции в своих модулях. Такие операции способны полностью убить производительность NGINX и их следует избегать любой ценой.
Но даже в текущей реализации NGINX не всегда возможно избежать блокировок. И для решения данной проблемы в NGINX версии 1.7.11 был представлен новый механизм «пулов потоков». Что это такое и как его применять разберем далее, а для начала познакомимся с нашим врагом в лицо.
Основы Linux от основателя Gentoo. Часть 4 (1/4): Файловые системы, разделы и блочные устройства
20 мин
Перевод
Первый отрывок четвертой части серии руководств для новичков повествует о блочных устройствах, разделах и файловых системах. Вы научитесь размечать жесткий диск с помощью утилиты
fdisk, создавать файловые системы и монтировать их. Познакомитесь с синтаксисом конфигурационного файла fstab.
Навигация по основам Linux от основателя Gentoo:
Часть I: 1, 2, 3, 4
Часть II: 1, 2, 3, 4, 5
Часть III: 1, 2, 3, 4
Часть IV
- Файловые системы, разделы и блочные устройства (вступление)
- Загрузка системы и уровни загрузки
- Квоты файловых систем
- Системные логи (итоги и ссылки)

Подводные камни Bash
32 мин
Перевод
В этой статье мы поговорим об ошибках, совершаемых программистами на Bash. Во всех приведённых примерах есть какие-то изъяны. Вам удастся избежать многих из нижеописанных ошибок, если вы всегда будете использовать кавычки и никогда не будете использовать разбиение на слова (wordsplitting)! Разбиение на слова — это ущербная легаси-практика, унаследованная из оболочки Bourne. Она применяется по умолчанию, если вы не заключаете подстановки (expansions) в кавычки. В общем, подавляющее большинство подводных камней так или иначе связаны с подстановкой без кавычек, что приводит к разбиению на слова и глоббингу (globbing) получившегося результата.
Содержание
- for i in $(ls *.mp3)
- cp $file $target
- Имена файлов с предшествующими дефисами
- [ $foo = «bar» ]
- cd $(dirname "$f")
- [ "$foo" = bar && "$bar" = foo ]
- [[ $foo > 7 ]]
- grep foo bar | while read -r; do ((count++)); done
- if [grep foo myfile]
- if [bar="$foo"]; then ...
- if [ [ a = b ] && [ c = d ] ]; then ...
- read $foo
- cat file | sed s/foo/bar/ > file
- echo $foo
- $foo=bar
- foo = bar
- echo <<EOF
- su -c 'some command'
- cd /foo; bar
- [ bar == "$foo" ]
- for i in {1..10}; do ./something &; done
- cmd1 && cmd2 || cmd3
- echo «Hello World!»
- for arg in $*
- function foo()
- echo "~"
- local varname=$(command)
- export foo=~/bar
- sed 's/$foo/good bye/'
- tr [A-Z] [a-z]
- ps ax | grep gedit
- printf "$foo"
- for i in {1..$n}
- if [[ $foo = $bar ]] (в зависимости от цели)
- if [[ $foo =~ 'some RE' ]]
- [ -n $foo ] or [ -z $foo ]
- [[ -e "$broken_symlink" ]] возвращает 1, несмотря на существование $broken_symlink
- Сбой ed file <<<«g/d\{0,3\}/s//e/g»
- Сбой подцепочки (sub-string) expr для «match»
- Про UTF-8 и отметках последовательности байтов (Byte-Order Marks, BOM)
- content=$(<file)
- for file in ./*; do if [[ $file != *.* ]]
- somecmd 2>&1 >>logfile
- cmd; ((! $? )) || die
- y=$(( array[$x] ))
- read num; echo $((num+1))
- IFS=, read -ra fields <<< "$csv_line"
- export CDPATH=.:~/myProject
Механизмы контейнеризации: cgroups
11 мин
Туториал

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Управление контейнерами с LXD
7 мин
Туториал

Продолжаем наш цикл статей о контейнеризации. Если первые две статьи (1 и 2) были посвящены теории, то сегодня мы поговорим о вполне конкретном инструменте и об особенностях его практического использования. Предметом нашего рассмотрения будет LXD (сокращение от Linux Container Daemon), созданный канадцем Стефаном Грабе из компании Canonical.
Gitlab-CI
5 мин
Туториал

Всем привет.
У нас не так много задач, которым необходим полноценный CI. Некоторое время мы использовали в качестве CI-сервиса Jenkins. Там всё довольно очевидно, он прост и гибок в настройке, имеет кучу плагинов, но пару раз мы столкнулись с OOM-убийцами агентов на слабых машинах и решили рассмотреть в качестве CI-сервиса Gitlab CI, потому что мы любим эксперименты и тем более в комментариях к нашей прошлой статье задавали такой вопрос.
Микросервисы (Microservices)
22 мин
От переводчика: некоторые скорее всего уже читали этот титанический труд от Мартина Фаулера и его коллеги Джеймса Льюиса, но я все же решил сделать перевод этой статьи. Тренд микросервисов набирает обороты в мире enterprise разработки, и эта статья является ценнейшим источником знаний, по сути выжимкой существующего опыта работы с ними.
Термин «Microservice Architecture» получил распространение в последние несколько лет как описание способа дизайна приложений в виде набора независимо развертываемых сервисов. В то время как нет точного описания этого архитектурного стиля, существует некий общий набор характеристик: организация сервисов вокруг бизнес-потребностей, автоматическое развертывание, перенос логики от шины сообщений к приемникам (endpoints) и децентрализованный контроль над языками и данными.
Термин «Microservice Architecture» получил распространение в последние несколько лет как описание способа дизайна приложений в виде набора независимо развертываемых сервисов. В то время как нет точного описания этого архитектурного стиля, существует некий общий набор характеристик: организация сервисов вокруг бизнес-потребностей, автоматическое развертывание, перенос логики от шины сообщений к приемникам (endpoints) и децентрализованный контроль над языками и данными.
Consul.io Часть 1
7 мин
При разработке приложений необходимо уделять особое внимание архитектуре. Если изначально этого не сделать, проблемы масштабирования могут появиться внезапно (а иногда могут не иметь решения). Масштабирование приложения и эффективное использование ресурсов на начальном этапе — это сэкономленные месяцы работы в дальнейшем.
Для предотвращения подобных проблем часто используют распределенную архитектуру, то есть архитектуру с возможностью горизонтального масштабирования всех компонентов. Но к сожалению, при реализации SOA возникают новые проблемы, а именно: связность и сложность конфигурации сервисов.

В данной статье мы расскажем об одном из discovery-сервисов под названием Consul, с помощью которого можно решить вышеизложенные проблемы и сделать архитектуру более прозрачной и понятной.
Для предотвращения подобных проблем часто используют распределенную архитектуру, то есть архитектуру с возможностью горизонтального масштабирования всех компонентов. Но к сожалению, при реализации SOA возникают новые проблемы, а именно: связность и сложность конфигурации сервисов.
В данной статье мы расскажем об одном из discovery-сервисов под названием Consul, с помощью которого можно решить вышеизложенные проблемы и сделать архитектуру более прозрачной и понятной.
Ошибка в ядре Linux отправляет поврежденные TCP/IP-пакеты в контейнеры Mesos, Kubernetes и Docker
8 мин
Перевод

А обнаружена она была на серверах Twitter
Ядро Linux имеет ошибку, причиной которой являются контейнеры. Чтобы не проверять контрольные суммы TCP, для сетевой маршрутизации контейнеры используют veth-устройства (такие как Docker на IPv6, Kubernetes, Google Container Engine и Mesos). Это приводит к тому, что в ряде случаев приложения ошибочно получают поврежденные данные, как это происходит при неисправном сетевом оборудовании. Мы проверили, что эта ошибка появилась, по крайней мере, три года назад и до сих пор «сидит» в ядрах. Наш патч был проверен и введен в ядро, и в настоящее время обеспечивает ретроподдержку стабильного релиза 3.14 в различных дистрибутивах (таких как Suse и Canonical). Если Вы в своей системе используете контейнеры, я рекомендую Вам воспользоваться этим патчем или установить ядро вместе с ним, когда это станет доступным.
Примечание: это не относится к сетям с NAT, по умолчанию используемых для Docker, так как Google Container Engine практически защищен от ошибок «железа» своей виртуализированной сетью. Еще Джейк Бауэр (Jake Bower) считает, что эта ошибка очень похожа на ошибку Pager Duty, обнаруженную ранее.
Как это все началось
В один из выходных ноября группа саппорт-инженеров Твиттера просматривала логи. Каждое неработающее приложение выдавало «невероятные» ошибки в виде строк странных символов или пропусков обязательных полей. Взаимосвязь этих ошибок не была очевидна из-за природы распределенной архитектуры Твиттера. Вся ситуация осложнялась еще и тем, что в любой распределенной системе данные, когда-то испорченные, могут вызвать ошибки еще довольно продолжительное время (они сохраняются в кэшах, записываются на дисках, в журналах и т.д.).
После суток непрерывной работы по поиску неисправности на уровне приложений, команде удалось локализовать проблему до отдельных рэковых стоек. Инженеры определили, что значительное увеличение числа выявленных ошибок контрольной суммы TCP произошло непосредственно перед тем, как они дошли до адресата. Казалось, что этот результат «освобождал от вины» софт: приложение может вызвать перегрузку сети, а не повреждение пакета!