

На прошлой неделе я помогал одному другу пустить одно его новое приложение в свободное плавание. Пока не могу особенно об этом распространяться, но упомяну, что это приложение, конечно же, сдобрено искусственным интеллектом — сегодня этим не удивишь. Может быть, даже изрядно сдобрено, в зависимости от того, к чему вы привыкли.
В большинстве современных приложений с ИИ в той или иной форме внедрена технология RAG (генерация с дополненной выборкой). Сейчас она у всех на слуху — о ней даже написали страницу в Википедии! Не знаю, ведёт ли кто-нибудь статистику, как быстро термин обычно дозревает до собственной статьи в Википедии, но термин RAG определённо должен быть где-то в топе этого рейтинга.
Меня довольно заинтриговало, что большинство успешных ИИ-приложений – это, в сущности, инструменты для умного семантического поиска. Поиск Google (в своём роде) раскрепостился, и это наталкивает меня на мысли, вдруг они только сейчас дали волю своим мощностям LLM, которые уже давно стояли за поисковым движком. Но я отвлёкся.
То приложение, разработкой которого мой друг занимался пару последних недель, работает с обширными данными из интернет-магазина: это описание различных товаров, инвойсы, отзывы, т. д. Вот с какой проблемой он столкнулся: оказалось, RAG не слишком хорошо обрабатывает некоторые запросы, но с большинством запросов справляется отлично.
За последние пару лет я успел заметить одну выраженную черту разработчиков, привыкших действовать в области традиционного (детерминированного) программирования: им очень сложно перестроиться на осмысление задач в статистическом контексте, а именно так и следует подходить к программированию приложений с большими языковыми моделями, суть которых — это статистика. Статистика «хаотичнее» традиционной информатики и подчиняется иным правилам, нежели алгоритмы обычной computer science. К чему я клоню: статистика — это по-прежнему математика, но очень своеобразная математика.












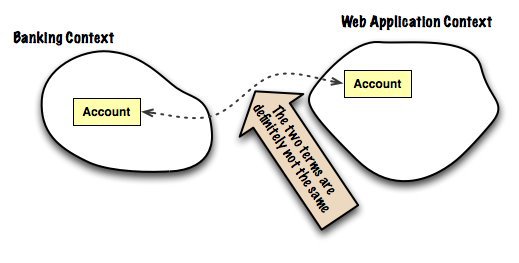
 Эванс написал
Эванс написал 
