
Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

Пользователь
Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

Облако предлагает много возможностей для развития ИИ. С помощью облачных вычислений проще масштабировать ML-модели, повышать точность обучения и предоставлять данные удаленно пользователям. Однако масштабное развертывание ML-моделей требует понимания архитектуры нейронных сетей.
Один из важнейших инструментов машинного обучения — трансформеры. Популярность трансформеров взлетела до небес в связи с появлением больших языковых моделей вроде ChatGPT, GPT-4 и LLama. Эти модели созданы на основе трансформерной архитектуры и демонстрируют отличную производительность в понимании и синтезе естественных языков.
Хотя в сети уже есть хорошие статьи, в которых разобран принцип действия трансформеров, большинство материалов изобилует запутанными терминами. Мы подготовили перевод статьи, в которой без кода и сложной математики объясняют современную трансформерную архитектуру.

Эта история началась в начале марта этого года. ChatGPT тогда был в самом расцвете. Мне в Telegram пришёл Саша Кукушкин, с которым мы знакомы довольно давно. Спросил, не занимаемся ли мы с Сашей Николичем языковыми моделями для русского языка, и как можно нам помочь.
И так вышло, что мы действительно занимались, я пытался собрать набор данных для обучения нормальной базовой модели, rulm, а Саша экспериментировал с существующими русскими базовыми моделями и кустарными инструктивными наборами данных.
После этого мы какое-то время продолжали какое-то время делать всё то же самое. Я потихоньку по инерции расширял rulm новыми наборами данных. Посчитав, что обучить базовую модель нам в ближайшее время не светит, мы решили сосредоточиться на дообучении на инструкциях и почти начали конвертировать то, что есть, в формат инструкций по аналогии с Flan. И тут меня угораздило внимательно перечитать статью.
Понятие Mutual Information (MI) связано с задачей прогноза. Собственно, задачу прогноза можно рассматривать как задачу извлечения информации о сигнале из факторов. Какая-то часть информации о сигнале содержится в факторах. И если вы напишите функцию, которая по факторам вычисляет число близкое к сигналу, то это и будет демонстрацией того, что вы смогли извлечь MI между сигналом и факторами.

ClearML — это довольно мощный фреймворк, основным предназначением которого является трекинг ML-экспериментов. Для рассмотрения его возможностей построим небольшой пайплайн обучения ML-модели...
Не знаю как вы, а я регулярно сталкиваюсь с ситуацией - предлагаешь кому-то сделать проект на современном стеке технологий, а он говорит - "Да я лучше установлю Wordpress". Думаю, многие мало-мальски опытные программисты, ненавидят вордпресс. Но почему заказчики предпочитают его?
Да, можно сказать, что для него есть куча готовых плагинов, что многие программисты его знают (пусть и ненавидят). Но в то же время даже заказчики понимают, что вордпресс очень быстро превращает в тормозящую свалку из плагинов разной степени глючности. Но почему они все-таки его предпочитают?
Мне кажется я нашел ответ. Этот ответ - хостинги.
Точнее, виртуальные LAMP-хостинги. Те самые, по 100 рублей сайт. Они не меняются последние лет 20. И они действительно очень удобны для простых людей.
Почему? Потому что там все есть. Панель управления, где есть кнопка "Создать сайт на Wordpress/Drupal/MediaWiki с таким-то адресом". Ты нажимаешь, и сайт создан. Всё. Для заказчиков это куда важнее любой технологичности.
И тут я задумался - а почему нет замены этому для современных веб-сервисов на современном стеке технологии? И нашел ответ, который меня поразил. Замена есть. Но ею никто не пользуется как заменой.
Это docker-образы.
Docker-образ - это буквально картридж для игровой приставки, который вставил в слот, и он сразу работает. Ну, несколько env-параметров укажи, и работает. Технологический стек при этом может быть любым. Docker для этого и нужен - абстрагировать технологический стек и все окружение от конечной эксплуатации.

Маленький совет из будущего: «В данной статье будут затронуты некоторые понятия, о которых я писал раньше, так что для полного понимания темы, советую прочитать и предыдущую статью»На самом деле, на хабре было множество публикаций по этой теме, но все они говорят о разных вещах. Давайте разберёмся и соберём всё в одну кучку, для полноценного понимания картины мира.

К задачам на поиск кратчайшего пути я вернулся спустя год после первого не совсем успешного опыта. По воле случая пришлось углубиться в современные методы решения подобных задач и я обнаружил целый удивительный мир эвристических, не точных, методов решения логистических задач, о которых год назад и не подозревал. Исследуя эту тематику появились некоторые идеи по улучшению и развитию данных методов. Этим и хочу поделиться в данной статье.
Привет, Хабр!

В задачах машинного обучения для оценки качества моделей и сравнения различных алгоритмов используются метрики, а их выбор и анализ — непременная часть работы датасатаниста.
В этой статье мы рассмотрим некоторые критерии качества в задачах классификации, обсудим, что является важным при выборе метрики и что может пойти не так.


В предыдущей статье было показано как, используя несколько модулей Python, можно обрабатывать текстовые данные и переводить их в числовые векторы, чтобы получить матрицу векторных представлений коллекции документов. В данной статье будет рассказано об использовании матрицы векторных представлений текстов в сервисе автокластеризации первичных событий в платформе monq для зонтичного мониторинга ИТ-инфраструктуры и бизнес-процессов.
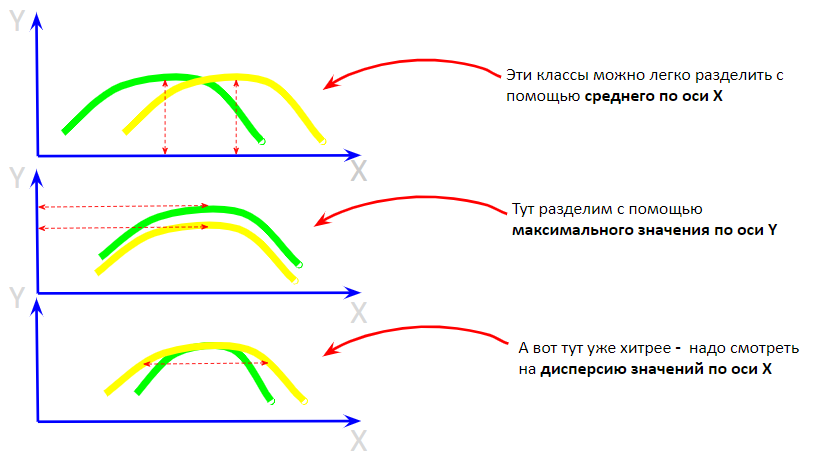
Разберем способы поднять точность модели!
Привет, чемпион! Возможно, перед тобой сейчас стоит задача построить предиктивную модель, или ты просто фармишь Kaggle, и тебе не хватает идей, тогда эта статья будет тебе полезна!
Наверное, уже только ленивый не слышал про Data Science и то, как модели машинного обучения помогают прогнозировать будущее, но самое крутое в анализе данных, на мой взгляд, - это хакатоны! Будь-то Kaggle или локальные соревнования, везде примерно одна задача - получить точность выше, чем у других оппонентов (в идеале еще пригодную для продакшена модель). И тут возникает проблема...

Когда впервые сталкиваешься с понятием MLOps, нет абсолютно никакого понимания, а зачем это вообще нужно. В разного рода выступлениях, посвященных этой теме, рассказывают о важности воспроизводимости результатов, хранения зависимостей проекта, а зачем это нужно — обычно никто не объясняет. Все эти вещи становятся очевидными только после того, как пройдешь через весь ад создания и поддержания действительно крупного проекта.
В первой части этой статьи я расскажу о проблемах, с которыми можно столкнуться при работе над проектами, а во второй — об инструментах, которые помогут с ними справиться. Это будет интересно в первую очередь начинающим специалистам в области ML, которые еще не столкнулись с подобными проблемами в своей практике. Я не буду рассказывать об инструментах, которые и так пользуются популярностью в DevOps, а затрону специфичные для области вещи.

CatBoost – библиотека, которая была разработана Яндексом в 2017 году, представляет разновидность семейства алгоритмов Boosting и является усовершенствованной реализацией Gradient Boosting Decision Trees (GBDT). CatBoost имеет поддержку категориальных переменных и обеспечивает высокую точность. Стоит сказать, что CatBoost решает проблему смещения градиента (Gradient Bias) и смещения предсказания (Prediction Shift), это позволяет уменьшить вероятность переобучения и повысить точность алгоритма.
Многие, кто работал с Spark ML, знают, что некоторые вещи там сделаны "не совсем удачно"
или не сделаны вообще. Позиция разработчиков Spark в том, что SparkML — это базовая платформа, а все расширения должны быть отдельными пакетами. Но это не всегда удобно, ведь Data Scientist и аналитики хотят работать с привычными инструментами (Jupter, Zeppelin), где есть большая часть того, что нужно. Они не хотят собирать при помощи maven-assembly JAR-файлы на 500 мегабайт или руками скачивать зависимости и добавлять в параметры запуска Spark. А более тонкая работа с системами сборки JVM-проектов может потребовать от привыкшых к Jupyter/Zeppelin аналитиков и DataScientist-ов много дополнительных усилий. Просить же DevOps-ов и администраторов кластера ставить кучу пакетов на вычислительные ноды — явно плохая идея. Тот, кто писал расширения для SparkML самостоятельно, знает, сколько там скрытых трудностей с важными классами и методами (которые почему-то private[ml]), ограничениями на типы сохраняемых параметров и т.д.
И кажется, что теперь, с библиотекой MMLSpark, жизнь станет немного проще, а порог вхождения в масштабируемое машинное обучение со SparkML и Scala чуть ниже.

В этой статье я поделюсь с вами ресурсами и методологией, которые я активно использовал для прохождения сертификации “Databricks Certified Associate Developer for Apache Spark 3.0”.

Прим. Wunder Fund: короткая статья о том, как эмбеддинги могут помочь при работе с категориальными признаками и сетками. А если вы и так умеете в сетки — то мы скоро открываем набор рисерчеров и будем рады с вами пообщаться, stay tuned.
Создание эмбеддингов признаков (feature embeddings) — это один из важнейших этапов подготовки табличных данных, используемых для обучения нейросетевых моделей. Об этом подходе к подготовке данных, к сожалению, редко говорят в сферах, не связанных с обработкой естественных языков. И, как следствие, его почти полностью обходят стороной при работе со структурированными наборами данных. Но то, что его, при работе с такими данными, не применяют, ведёт к значительному ухудшению точности моделей. Это стало причиной появления заблуждения, которое заключается в том, что алгоритмы градиентного бустинга, вроде того, что реализован в библиотеке XGBoost, это всегда — наилучший выбор для решения задач, предусматривающих работу со структурированными наборами данных. Нейросетевые методы моделирования, улучшенные за счёт эмбеддингов, часто дают лучшие результаты, чем методы, основанные на градиентном бустинге. Более того — обе группы методов показывают серьёзные улучшения при использовании эмбеддингов, извлечённых из существующих моделей.
Эта статья направлена на поиск ответов на следующие вопросы:
1. Что такое эмбеддинги признаков?
2. Как они используются при работе со структурированными данными?
3. Если использование эмбеддингов — это столь мощная методика — почему она недостаточно широко распространена?
4. Как создавать эмбеддинги?
5. Как использовать существующие эмбеддинги для улучшения других моделей?

Редакция сайта DOU.UA решила подробнее проанализировать, кто получает больше всего на рынке, и попыталась составить инструкцию, как добиться столь высоких результатов. Далее – 11 шагов, которые помогут вам получать зарплату более $5000.
Внимательный читатель может сказать, что сегодня на ИТ-рынке почти каждый второй специалист получает более $5000. Так ли это?
