
Вместе с дата-сайентистом и биоинформатиком Марией Дьяковой подготовили подробный гайд о том, как устроены языковые модели и что нужно знать, чтобы начать с ними работать.

Пользователь
Вместе с дата-сайентистом и биоинформатиком Марией Дьяковой подготовили подробный гайд о том, как устроены языковые модели и что нужно знать, чтобы начать с ними работать.

Привет, Хабр! Мы — DS-ы Павел Парфенов и Максим Шаланкин в команде Финтеха Big Data МТС. У нас много ML-моделей, которые нужно тестировать и внедрять в прод. Все это создает высокий темп разработки c кучей рутинных и ручных операций: от постановки задачи до продуктивизации и сопровождении модели. Мы смогли частично победить эту рутину с помощью drag and drop деплоя ML-моделей через web-интерфейс. В этой статье расскажем, что у него под капотом и какие функции в нем реализованы.

Сейчас технологии машинного обучения и нейронных сетей находят широкое применение в различных сферах, не исключая дизайн и ремонт помещений. Одной из таких технологий является методы генеративных нейросетей, которые позволяют преобразовывать изображения, сохраняя основные элементы оригинала, но добавляя новые детали и стилистические изменения. Меня зовут Алексей Луговой, я работаю с Computer Vision в Самолете и уже обзорно рассказывал на Хабре, как мы применяем искусственный интеллект в строительстве. Сегодня же углубимся в задачу по созданию генеративной сети для создания проекта ремонта. Рассмотрю процесс использования диффузионных моделей с различными дополнениями на примере не самой обычной задачи — преобразования интерьера комнаты, начав с оригинального изображения голых стен и завершая итоговой генерацией в фирменном дизайнерском стиле.

Генерация разнообразного контента с помощью ИИ продолжает быть на пике популярности. На смену картинкам по описанию пришли музыкальные композиции на основе текста и психоделические видео, на которых у людей меняется не только геометрия, но и вообще всё. Однако это лишь вершина айсберга. We need to go deeper. Хабру нужны не смешные нейро(де)генеративные мемы, а статьи от людей, которые работают с генеративным ИИ профессионально и на острие современных технологий пытаются сделать нечто крутое и полезное.
Привет, меня зовут Алексей Луговой, я занимаюсь Computer Vision в Самолете, и сегодня объявляю о старте автоген-челленджа. Этот челлендж — совместная инициатива Хабра и Самолета. Про призы лучшим авторам и другие детали расскажу подробнее в конце статьи, а начну с личного примера — расскажу, как мы научились подставлять другую мебель на фото интерьера.

Если вы полный ноль в интернет-технологиях, и хотите получить общее понимание Интернета, прочитав всего одну статью, то эта статья - для вас.
Здесь вы узнаете о 4 уровнях модели TCP/IP. О том, что такое MAC-адрес и IP-адрес, и зачем нам 2 типа цифровых адресов. Как работает DNS. Зачем нужны коммутаторы и роутеры. Как работает NAT. Как устанавливается защищённое соединение. Что такое инфраструктура открытых ключей, и зачем нужны TLS-сертификаты. Чем отличаются три версии протокола HTTP. Как происходит HTTP-аутентификация. И в конце будет несколько слов о VPN.

Примерно полгода назад математическое сообщество услышало новость о том, что исследователи DeepMind создали ИИ-систему, решающую геометрические задачи с Международной математической олимпиады на уровне, близком к золотым медалистам ММО. (Эту новость обсуждали в сабреддите \math, см., например, здесь и здесь.) За этими новостями, как часто бывает с новостями о прогрессе ИИ, последовала волна страха и ужаса, усиленная множеством громких газетных статей с картинками (разумеется, сгенерированными ИИ), на которых искусственные мозги решают ужасно сложные уравнения. По коллективной спине математического сообщества побежали мурашки, снова всплыли на поверхность обычные экзистенциальные вопросы о будущем человеческого интеллекта, а Интернет заполнили мемы о грядущем восстании машин.
Я бы хотел взглянуть на эту тему под новым углом. (Предупреждение: возможно, для вас он не будет новым. Если вы имели дело с евклидовой геометрией, понимаете основы линейной алгебры и внимательно читаете журнал Nature, то могли прийти ко всем этим выводам самостоятельно. Но поскольку некоторые критичные аспекты изложены мелким шрифтом (вероятно, намеренно), я всё равно считаю, что их нужно сделать более очевидными.)
Я узнал об этих исследованиях, когда кто-то выложил ссылку на пресс-релиз DeepMind в групповом чате моих друзей, любящих математику. Один мой друг с небольшими нотками паники рассказывал, что какой-то ИИ смог решить какую-то сложную задачу с ММО при помощи рассуждений, состоящих примерно из двухсот логических шагов. Вскоре все в чате начали грустно шутить о своём неизбежном увольнении и безработице.

Налоговая отдаёт данные ЕГРЮЛ по организации в виде PDF. Посредники за автоматический доступ по API хотят денег. На многих сайтах часть данных закрыто, часть функций недоступны бесплатно, и полно рекламы.
Особенно интересно, что на некоторых сайтах предоставляющих данные по API имеется логотип Сколково. Это такой высокотехнологический бизнес, наверное, открытые данные продавать.
Налоговая просит 150 000 рублей в год за доступ к данным ЕГРЮЛ в виде сваленных в архивы XML-файлов. У ФНС классный бизнес. Вы проявляйте должную осмотрительность при выборе поставщиков, но доступ к данным за деньги. Если вы хотите получить доступ и к реестру индивидуальных предпринимателей (ЕГРИП), то платите ещё 150 000 рублей в год. Согласитесь 300 000 рублей в год приличная сумма.
Остальные реестры данных у налоговой доступны бесплатно. Однако, без базы ЕГРЮЛ их вряд ли можно использовать. Самая частая операция в бизнесе подставить реквизиты из ЕГРЮЛ по ИНН.
Сформировалась целая отрасль, можно сказать, торговцев воздухом открытыми данными, создающих ВВП из воздуха как бухгалтеры, работающие руками там, где должны работать программы. Сколько компаний платит налоговой по 300 000р. в год?! Сколько программистов занято написанием одинаковых по функциям парсеров, которые переводят данные из XML налоговой в SQL и JSON?! Сколько серверов заняты под одинаковые функции?! Где добавочная стоимость? Все вроде при деле, а за чей счёт банкет?
Ну, ладно, “скандалить, критиковать каждый может”(с) как говорил бессмертный товарищ Райкин. “А что ты предлагаешь?” — резонно вы меня спросите. А я вам отвечу.

ML‑эксперименты, по своей природе, полны неопределённости и сюрпризов. Небольшие изменения могут вести к огромным улучшениям, но иногда даже самые хитрые уловки не дают результатов.
В любом случае — успешная работа в сфере машинного обучения держится на систематическом применении итеративного подхода к экспериментам и на исследовании моделей. Именно здесь ML‑специалисты часто сталкиваются с беспорядком. Учитывая то, как много путей они могут избрать, им тяжело бывает удержать в поле зрения то, что они уже попробовали, и то, как это отразилось на эффективности работы моделей. Более того — ML‑эксперименты могут требовать много времени. С ними сопряжён риск пустой траты денег на повторные запуски тех экспериментов, результаты которых уже известны.
С помощью трекера экспериментов, вроде neptune.ai, можно скрупулёзно логировать сведения об экспериментах и сравнивать результаты разных попыток. Это позволяет выяснять то, какие настройки гиперпараметров и наборы данных вносят положительный вклад в эффективность работы моделей.
Но запись метаданных — это лишь половина секрета успешного ML‑моделирования. Нужно ещё иметь возможность проведения экспериментов таким образом, который позволяет быстро получать нужные результаты. Многие команды дата‑сайентистов, в основе рабочих процессов которых лежит система Git, сочли CI/CD‑платформы идеальным решением.
В этой статье мы исследуем вышеописанный подход к управления ML‑экспериментами и поговорим о том, в каких ситуациях его применение оправдано. Мы уделим основное внимание платформе GitHub Actions — системе, интегрированной в GitHub. Но освещённые здесь идеи применимы и к другим CI/CD‑фреймворкам. TL;DR под катом.

Postgres - один из крупнейших open source проектов. Он создавался многие года. Кодовая база накопилась огромная. Мне, как программисту, всегда было интересно как он работает под капотом. Но не про SQL пойдет речь, а про язык на котором он написан. Про C.
С общей архитектурой можно ознакомиться здесь
Для начала поймем, что происходит до входа в главный цикл сервера.

Мир нейросетей развивается с невероятной скоростью. Ещё вчера генерация изображений по текстовому описанию казалась чем-то фантастическим, а сегодня уже существуют десятки сервисов, соревнующихся в качестве и реалистичности результатов. Но как выбрать инструмент, который подходит именно вам?
В этом обзоре мы не будем загружать вас техническими подробностями и сложными терминами. Мы пойдём другим путём — протестируем популярные нейросети на конкретном задании и посмотрим, кто справится лучше.
Приятного прочтения (:

Базовые distroless-образы GoogleContainerTools часто упоминаются как один из способов создания (более) маленьких, (более) быстрых и (более) безопасных контейнеров. Но что на самом деле они собой представляют? Зачем они нужны? В чем разница между контейнером, созданным на distroless-базе, и контейнером, созданным с нуля? Давайте разберёмся.


Привет, Хабр!
Алгоритм backpropagation, или обратное распространение ошибки, является некой базой для тренировки многослойных перцептронов и других типов искусственных нейронных сетей. Этот алгоритм впервые был предложен Полем Вербосом в 1974 году, а позже популяризирован Дэвидом Румельхартом, Джеффри Хинтоном и Рональдом Уильямсом в 1986 году.
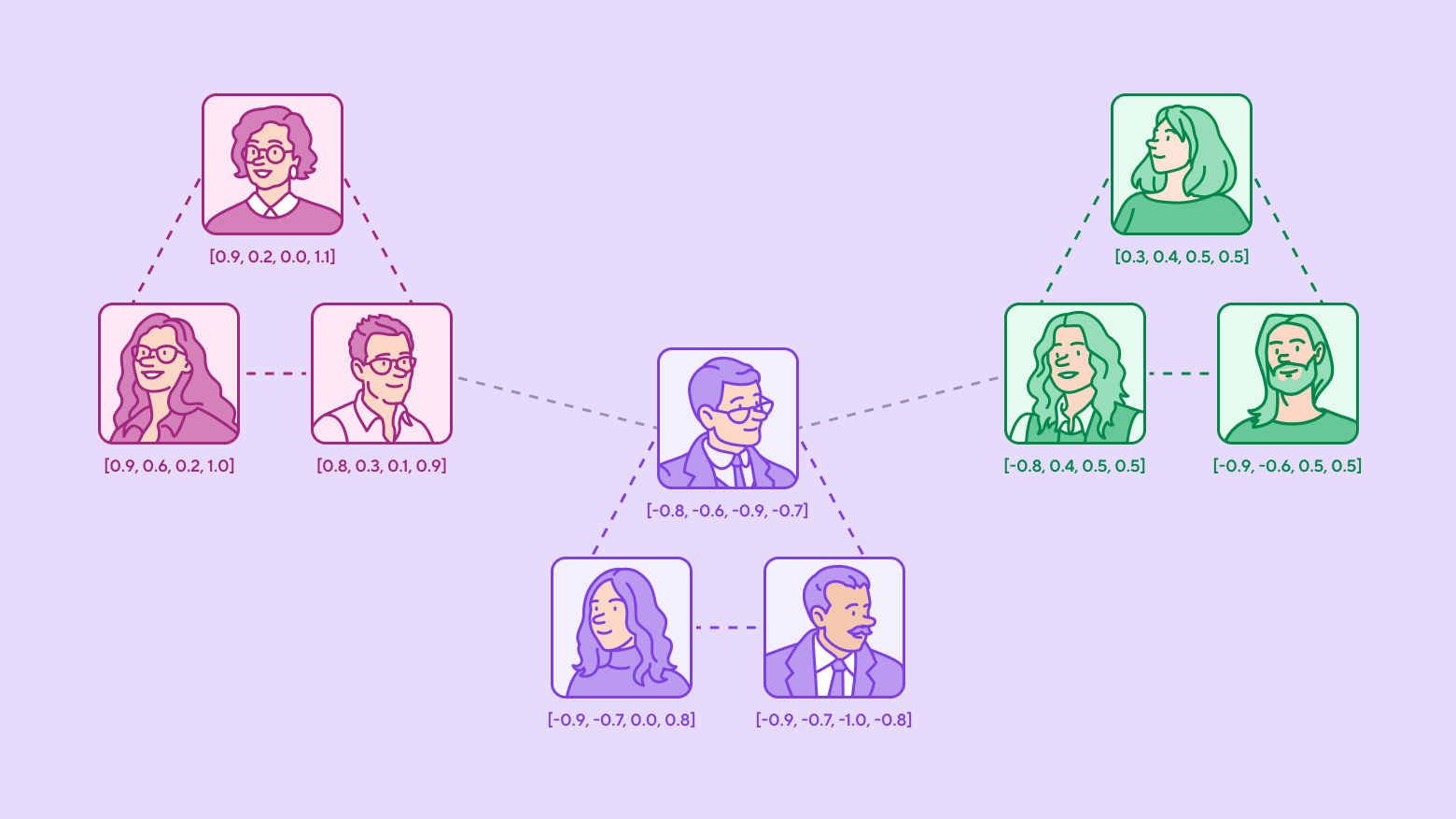
Только изучили один инструмент, как сразу же появились новые? Придется разбираться! В статье мы рассмотрим новый тип баз данных, который отлично подходит для ML задач. Пройдем путь от простого вектора до целой рекомендательной системы, пробежимся по основным фишкам и внутреннему устройству. Поймем, а где вообще использовать этот инструмент и посмотрим на векторные базы данных в деле.

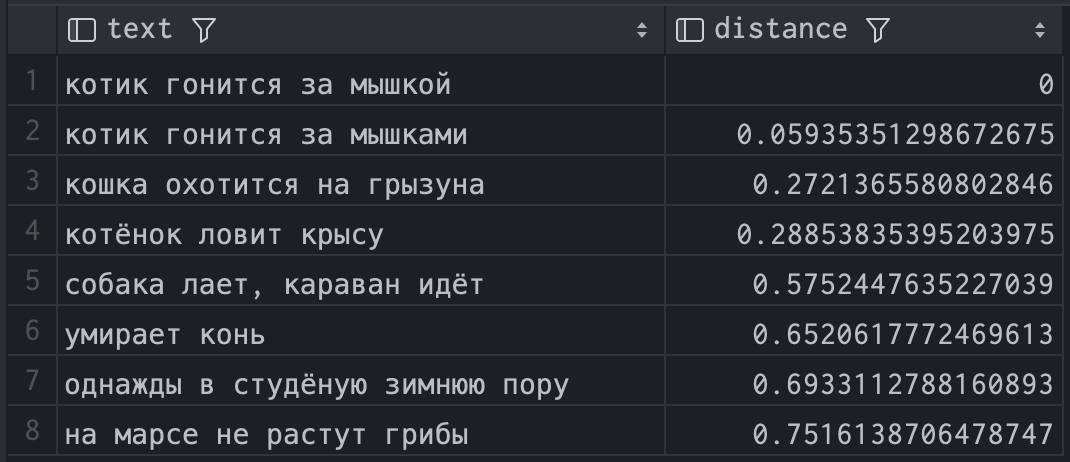
Казалось бы, в посгресе и так есть неплохой полнотекстовый поиск (tsvector/tsquery), и вы из коробки можете проиндексировать ваши тексты, а потом поискать по ним. Но на самом деле это не совсем то, что нужно — такой поиск работает лишь по чётким совпадениям слов. Т.е. postgres не догадается, что "кошка гонится за мышью" — это довольно близко к "котёнок охотится на грызуна". Как же победить такую проблему?
TLDR:

Исходные данные: мы с командой делаем банковское приложение. Веб-приложение. Не все поверят, но сегодня реально реализовать на вебе такой пользовательский опыт, от которого люди не будут скрипеть зубами и умолять вернуть им натив. Расскажу, какие Web API мы используем, раскрою тонкости и покажу примеры кода.
