
Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

Пользователь
Авторский обзор 90+ нейросетевых моделей на основе Transformer для тех, кто не успевает читать статьи, но хочет быть в курсе ситуации и понимать технические детали идущей революции ИИ.

С релизом Atomic Heart геймерам напомнили про один из не самых заезженных сеттингов для видеоигр. Сеттинг Страны Советов в том или ином виде интересен публике — как нашей, так и зарубежной. Вспоминаем игры, пропитанные духом СССР.

Для описания объектов и процессов в терминах бизнес-логики, конфигурирования и определения структуры и логики в сложных системах популярным подходом является использование предметно-специфических языков (Domain Specific Language - DSL), которые реализуются либо через синтаксические особенности языка программирования (например, с использованием средств метапрограммирования, аннотаций/декораторов, переопределения операторов и создания инфиксных операторов, как например в Kotlin DSL) или с помощью применения специализированных инструментов разработки и компиляторов (например, Jetbrains MPS или парсеров общего назначения, таких как ANTLR или Bison). Но существует также подход реализации DSL, основанный на синтаксическом разборе и одновременной кодогенерации для создания исполняемого кода по описанию и в этой статье мы рассмотрим некоторые примеры использования библиотеки textx для создания DSL на Python.

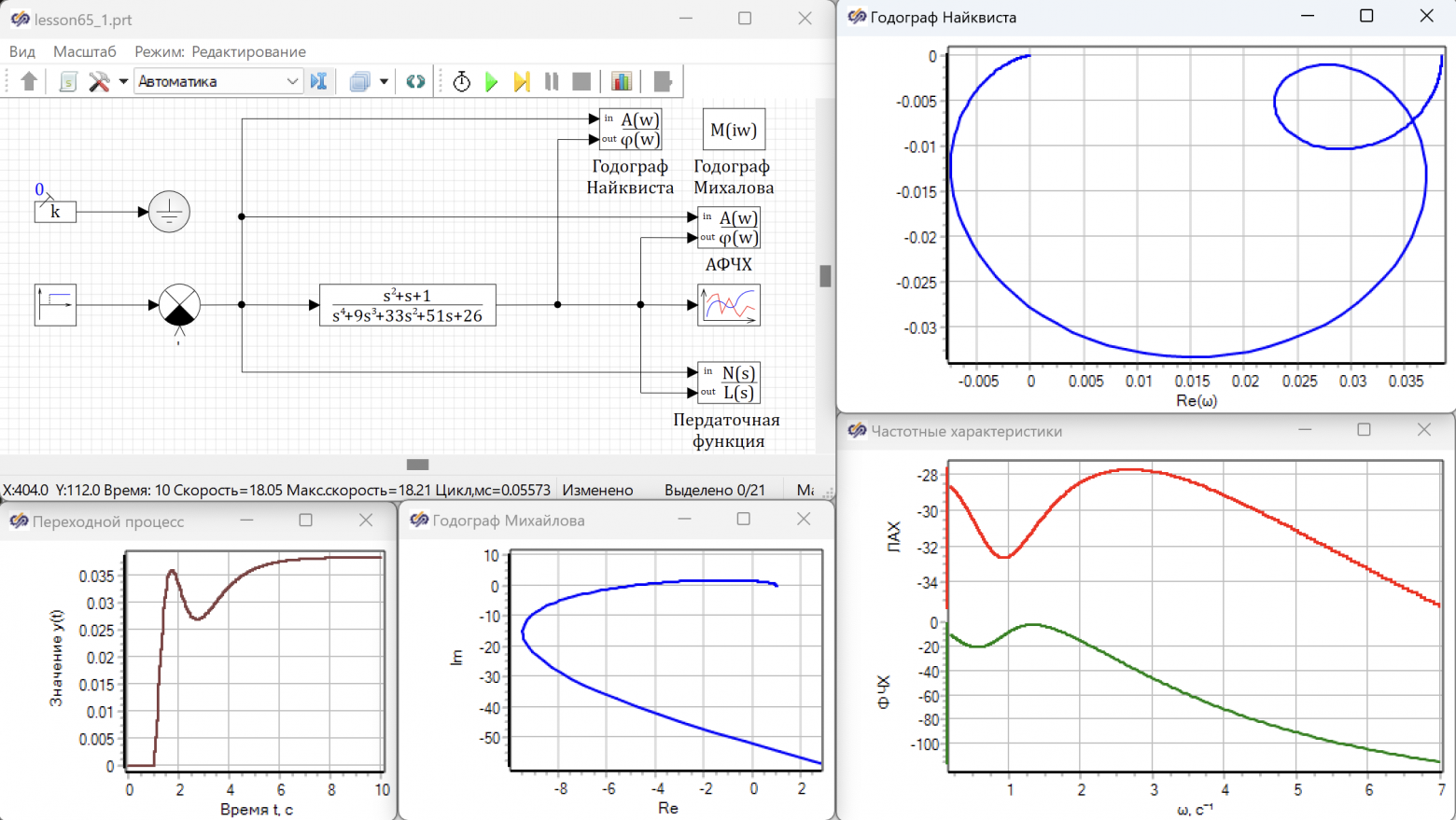
Продолжаем разбиратся теорией автоматического управления, по лекциям Олега Степановаича Козлова, "Управление в технических системах". Сейчас у нас будет годограф Найквиста.
Хайп вокруг нейросетей, выровненных при помощи инструкций и человеческой оценки (известных в народе под единым брендом «ChatGPT»), трудно не заметить. Люди разных профессий и возрастов дивятся примерами нейросетевых генераций, используют ChatGPT для создания контента и рассуждают на темы сознания, а также повсеместного отнимания нейросетями рабочих мест. Отдадим должное качеству продукта от OpenAI — так и подмывает использовать эту технологию по любому поводу — «напиши статью», «исправь код», «дай совет по общению с девушками».
Но как достичь или хотя бы приблизиться к подобному качеству? Что играет ключевую роль при обучении — данные, архитектура, ёмкость модели или что-то ещё? Создатели ChatGPT, к сожалению, не раскрывают деталей своих экспериментов, поэтому многочисленные исследователи нащупывают свой путь и опираются на результаты друг друга.
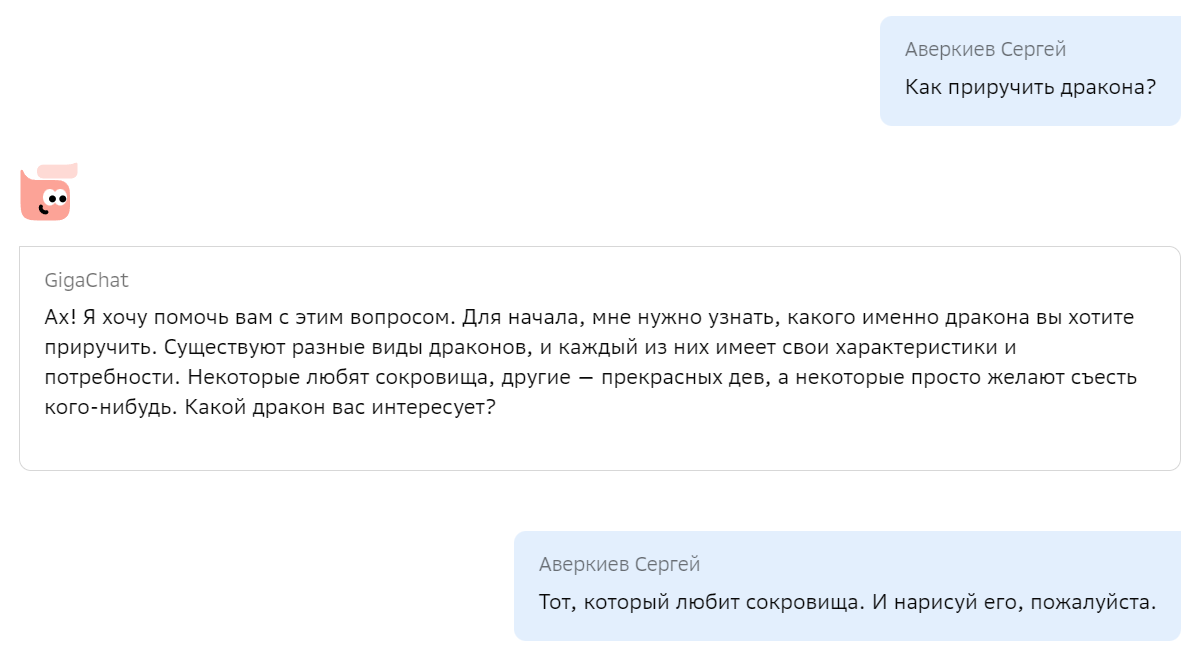
Мы с радостью хотим поделиться с сообществом своим опытом по созданию подобной модели, включая технические детали, а также дать возможность попробовать её, в том числе через API. Итак, «Салют, GigaChat! Как приручить дракона?»

У нас в SberDevices разрабатывается платформа по управлению рекомендациями, которая взаимодействует с разными ML-движками. Со временем их станет много, и, когда пользователь умных устройств Sber будет запрашивать контент – искать фильмы, музыку, спрашивать о чём-то виртуальных ассистентов Салют, – запрос будет проходить через нашу платформу.
Сначала выбор движка мы хотели завязывать на источник сообщений – пользовательское приложение на устройстве. Сейчас мы решили управлять маршрутизацией на основе содержания сообщений – по различным полям. Для этого используется набор правил, похожих на условие WHERE в SQL, т.е. мы выбираем маршруты, у которых совпадают условия со значениями полей сообщений.
В SQL-запросе пользователь шлёт условие, по которому из существующих строк таблицы выбираются подходящие. В нашей задаче получается наоборот: входящему сообщению нужно сопоставить все условия, которые у нас есть, и вернуть те, которые прошли проверку. Правила маршрутизации – это настройки и их должны создавать не только программисты, но и менеджеры контента или дейта-сайентисты. С такими задачами справляются такие фреймворки, как, например Drools, но мы решили написать своё легковесное решение с упрощенным DSL, условия на котором может понять не только разработчик.
Для обработки правил, написанных на кастомном DSL, лучшая библиотека – ANTLR4. Я находил много статей, в которых описываются разные аспекты работы с ANTLR4, но ни в одной из них я не увидел, то, что изучил на пути создания production-ready кода. Поэтому, разобравшись, я решил собрать туториал. Ниже опишу пример парсинга SQL SELECT-запроса в объектную модель Java. Будем двигаться постепенно, в этот раз рассмотрим простейший случай. На нём мы разберём саму идею этого парсера, сделаем минимальную реализацию.

Генеративные языковые модели уверенно обосновались в практике Natural Language Processing (NLP). Большие предобученные трансформеры двигаются сразу в трёх направлениях: мультимодальность, мультизадачность и мультиязычность. Сегодня мы расскажем про последнюю — о том, как учили модель на основе GPT-3 на 61 языке мира.
Это — самая многоязычная авторегрессионная модель на сегодня. Такую модель можно использовать, например, чтобы создать вопросно-ответную систему, обрабатывающую тексты на многих языках, научить диалогового ассистента говорить на разных языках, а также сделать более универсальные решения для парсинга текста, извлечения информации.
Этим релизом мы хотим привлечь внимание к развитию NLP для языков стран СНГ, а также народов России. Для многих из представленных языков эта модель стала первой авторегрессионной языковой моделью.
Модель доступна в двух вариантах размеров: mGPT XL на 1,3 миллиарда параметров — в открытом доступе, а mGPT 13B — будет доступна в ML Space SberCloud.


Уже много времени прошло с момента публикации наших последних языковых моделей ruT5, ruRoBERTa, ruGPT-3. За это время много что изменилось в NLP. Наши модели легли в основу множества русскоязычных NLP-сервисов. Многие коллеги на базе наших моделей выпустили свои доменно-адаптированные решения и поделились ими с сообществом. Надеемся, что наша новая модель поможет вам поднять метрики качества, и ее возможности вдохновят вас на создание новых интересных продуктов и сервисов.
Появление ChatGPT и, как следствие, возросший интерес к методам обучения с подкреплением обратной связью от человека (Reinforcement Learning with Human Feedback, RLHF), привели к росту потребности в эффективных архитектурах для reward-сетей. Именно от «интеллекта» и продуктопригодности reward-модели зависит то, насколько эффективно модель для инструктивной диалоговой генерации будет дообучаться, взаимодействуя с экспертами. Разрабатывая FRED-T5, мы имели в виду и эту задачу, поскольку от качества её решения будет во многом зависеть успех в конкуренции с продуктами OpenAI. Так что если ваша команда строит в гараже свой собственный ChatGPT, то, возможно, вам следует присмотреться и к FRED’у. Мы уже ранее рассказывали в общих чертах об этой модели, а сейчас, вместе с публичным релизом, настало время раскрытия некоторых технических подробностей.
Появление новых, более производительных GPU и TPU открывает возможности для использования в массовых продуктах и сервисах всё более емких моделей машинного обучения. Выбирая архитектуру своей модели, мы целились именно в ее пригодность к массовому realtime-инференсу, поскольку время выполнения и доступное оборудование — это основные факторы, лимитирующие возможность создания массовых решений на основе нейросетевых моделей. Если вы уже используете в своем решении модель ruT5, то подменив ее на FRED-T5 вы, вероятно, получите заметное улучшение значений ваших целевых метрик. Конечно, в скором будущем мы обучим еще более емкие варианты модели FRED-T5 и проверим их возможности — мы планируем и дальнейшее развитие линейки энкодер-декодерных моделей для обработки русского языка.

Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-like моделей и ответить на вопрос — можно ли обучить GPT-like модель в домашних условиях?
Для эксперимента выбрали LLaMA и GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.

Участники открытого сообщества LAION-AI выпустили в открытый доступ первые обученные модели OA_SFT_Llama_30B и OA_SFT_Llama_13B. и запустили ИИ-чатбот OpenAssistant на их основе. На текущий момент доступны модели в 13 и 30 млрд параметров, дообученные на мультиязычных датасетах, собранных сообществом. В основе моделей лежит уже успевшая стать популярной LLaMA.
OpenAssistant - это диалоговый помощник на базе ИИ, который понимает задачи, может взаимодействовать со сторонними системами (подобно плагинам в ChatGPT) и динамически извлекать информацию из них. OpenAssistant позиционируется как открытая альтернатива ChatGPT.
"Мы хотим, чтобы OpenAssistant стал единой, объединяющей платформой, которую все другие системы используют для взаимодействия с людьми." - декларируют своё видение члены сообщества LAION.
Вы можете попробовать поговорить с OpenAssistant уже сейчаст тут.
Еще вы можете принять участие в формировании датасета на своём языке тут.


--- Обновление статьи 9 Августа 2023 ---
В течении последнего полугода в сфере текстовых нейронок всё кипит - после слитой в сеть модели Llama, aka "ChatGPT у себя на пекарне" люди ощутили, что никакой зацензуренный OpenAI по сути им и не нужен, а хорошие по мощности нейронки можно запускать локально.
Основная проблема в том, что всё это требует глубоких технических знаний.
Но в этой статье я расскажу, как запустить добротную нейросеть на домашнем ПК с 16ГБ ОЗУ в несколько кликов. Буквально в несколько кликов - копаться в консоли не придётся.

Мы с командой разрабатываем FractalGPT — проект самообучающегося ИИ на базе больших языковых моделей(LLM) и логического вывода (reasoning). В этой статье мы расскажем о разработанном нами новом подходе, который называется fractal answer synthesis. Фрактальный синтез ответа позволяет существенно уменьшить уровень «галлюционирования» LLM и, как следствие, является важным шагом к решению проблемы фактологии генеративных нейросетей. По сути подход позволяет перейти от простого векторного представления текста(базы знаний) к его фрактальному представлению — более сложной структуре, инкапсулирующей внутри себя дополнительные «смыслы», которые в содержатся в тексте. В статье мы кратко описали преимущества и недостатки подхода, показали алгоритм построения «фрактального графа», представили принципиальную схему алгоритма и результаты тестирования на нашей базе знаний — статьях и книгах.

Понимание декораторов является важной вехой для любого программиста Python. Эта статья представляет собой пошаговое руководство о том, как декораторы могут помочь вам стать более эффективным и продуктивным разработчиком на Python.

В этой статье мы будем говорить о Notion AI - новой языковой модели, которая недавно была представлена в мире искусственного интеллекта.
Notion AI встроен в Notion, который многие программисты используют для документации и ведения проектов.
Четвёртая версия ChatGPT одних заставила пищать от восторга, а других повергла в уныние. Кто-то уже нашёл этой системе множество творческих применений, а кто-то пророчит, что эта нейросеть лишит работы кучу людей. Теперь возможности ChatGPT стали ещё шире: систему интегрировали с Wolfram | Alpha, легендарным движком для вычисления ответов в самых разных областях знания. Мы перевели для вас огромную подробную статью об этом от одного из разработчиков Wolfram | Alpha.
В предыдущей части мы рассматривали вероятностную постановку задачи машинного обучения, статистические модели, модель регрессии как частный случай и ее обучение методом максимизации правдоподобия.
В данной части рассмотрим метод максимизации правдоподобия в классификации: в чем роль кроссэнтропии, функций сигмоиды и softmax, как кроссэнтропия связана с "расстоянием" между распределениями вероятностей и почему модель регрессии тоже обучается через минимизацию кроссэнтропии. Данная часть содержит много отсылок к формулам и понятиям, введенным в первой части, поэтому рекомендуется читать их последовательно.
В третьей части (статья планируется) перейдем от метода максимизации правдоподобия к байесовскому выводу и его различным приближениям.
Данная серия статей не является введением в машинное обучение и предполагает знакомство читателя с основными понятиями. Задача статей - рассмотреть машинное обучение с точки зрения теории вероятностей, что позволит по новому взглянуть на проблему, понять связь машинного обучения со статистикой и лучше понимать формулы из научных статей. Также на описанном материале строятся более сложные темы, такие как вариационные автокодировщики (Kingma and Welling, 2013), нейробайесовские методы (Müller et al., 2021) и даже некоторые теории сознания (Friston et al., 2022).
