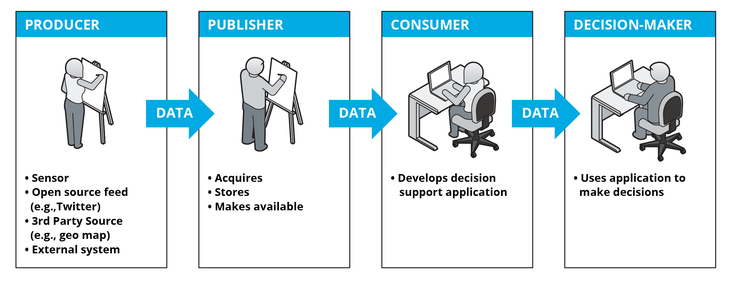
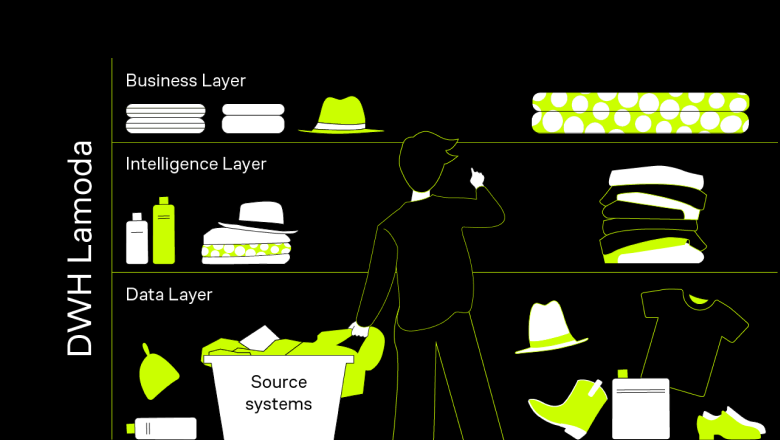
Системный аналитик превращает хаос в красивые решения и наводит порядок. Эта роль ‒ связующее звено между заказчиком и программистом, аналитик переводит с бизнесового на технический язык. Профессия сложная, но интересная и перспективная, поэтому если хочешь перейти в ИТ, обратите внимание на эту профессию.
В школе оценивают ваши знания с помощью ЕГЭ или экзаменов для поступления в ВУЗ на конкретную специальность. Предлагаю проверить знания по системному анализу в тесте «Готов ли я стать системным аналитиком». После прохождения вы узнаете насколько велики ваши шансы стать системным аналитиком или нужно уделить внимание подготовке. Если тест покажет, что необходимо еще набраться знаний, то приходите на курс «Системный аналитик с нуля», чтобы сэкономить время на поиске материала в интернете (прим. информация в статье и тестирование ‒ это мое личное мнение, которое может не совпадать с мнением читателя).
С помощью теста вы пройдете самопроверку перед собеседованием.

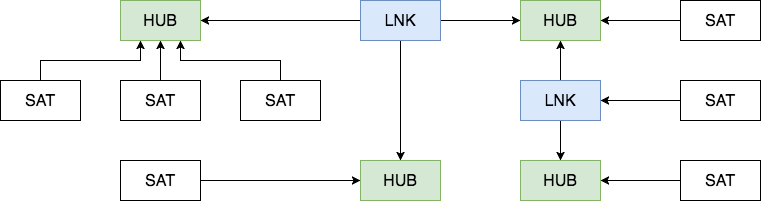



 Эту статью я написал в продолжение
Эту статью я написал в продолжение