
Часть первая. Классификация/локализация, обнаружение объектов и слежение за объектом
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.
Этот фрагмент взят из недавней публикации, которую составила наша научно-исследовательская группа в области компьютерного зрения. В ближайшие месяцы мы опубликуем работы на разные темы исследований в области Искусственного Интеллекта — о его экономических, технологических и социальных приложениях — с целью предоставить образовательные ресурсы для тех, кто желает больше узнать об этой удивительной технологии и её текущем состоянии. Наш проект надеется внести свой вклад в растущую массу работ, которые обеспечивают всех исследователей информацией о самых современных разработках ИИ.
Введение
Компьютерным зрением обычно называют научную дисциплину, которая даёт машинам способность видеть, или более красочно, позволяя машинам визуально анализировать своё окружение и стимулы в нём. Этот процесс обычно включает в себя оценку одного или нескольких изображений или видео. Британская ассоциация машинного зрения (BMVA) определяет компьютерное зрение как «автоматическое извлечение, анализ и понимание полезной информации из изображения или их последовательности».
Термин понимание интересно выделяется на фоне механического определения зрения — и демонстрирует одновременно и значимость, и сложность области компьютерного зрения. Истинное понимание нашего окружения достигается не только через визуальное представление. На самом деле визуальные сигналы проходят через оптический нерв в первичную зрительную кору и осмысливаются мозгом в сильно стилизованном смысле. Интерпретация этой сенсорной информации охватывает почти всю совокупность наших естественных встроенных программ и субъективного опыта, то есть как эволюция запрограммировала нас на выживание и что мы узнали о мире в течение жизни.










 Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
Здравствуй, Хабр! Цикл статей по инструментам для обучения нейронных сетей продолжается обзором популярного фреймворка Tensorflow.
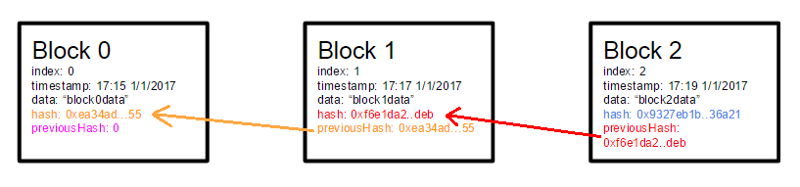


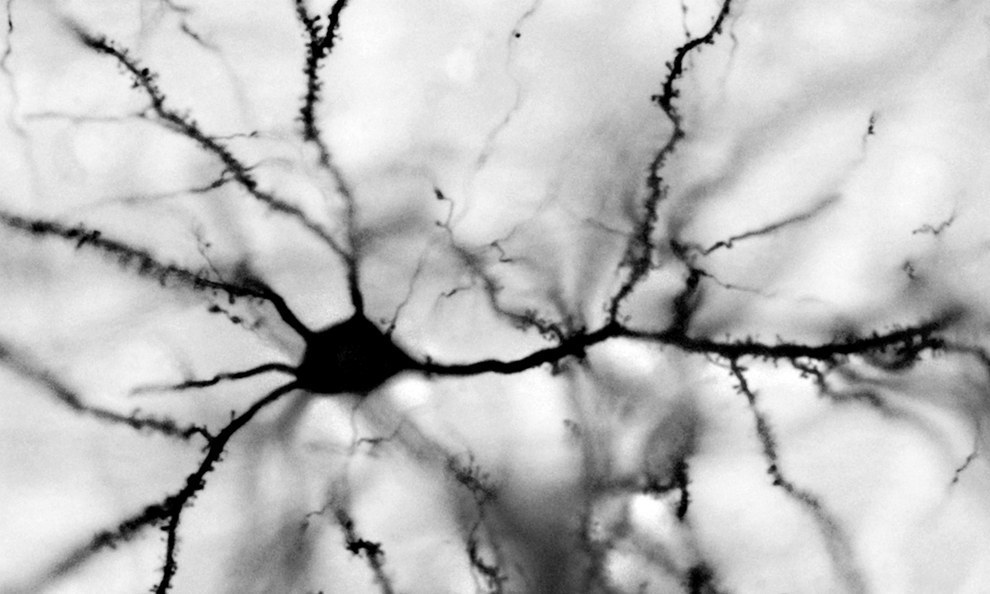 В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга.
В предыдущей части мы показали, что в клеточном автомате могут возникать волны, имеющие специфический внутренний узор. Такие волны могут запускаться из любого места клеточного автомата и распространяться по всему пространству клеток автомата, перенося информацию. Соблазнительно предположить, что реальный мозг может использовать схожие принципы. Чтобы понять возможность аналогии, немного разберемся с тем, как работают нейроны реального мозга. В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.
В свое время на Хабре был опубликован цикл статей «Логика мышления». С тех пор прошло два года. За это время удалось сильно продвинуться вперед в понимании того, как работает мозг и получить интересные результаты моделирования. В новом цикле «Логика сознания» я опишу текущее состоянии наших исследований, ну а попутно попытаюсь рассказать о теориях и моделях интересных для тех, кто хочет разобраться в биологии естественного мозга и понять принципы построения искусственного интеллекта.