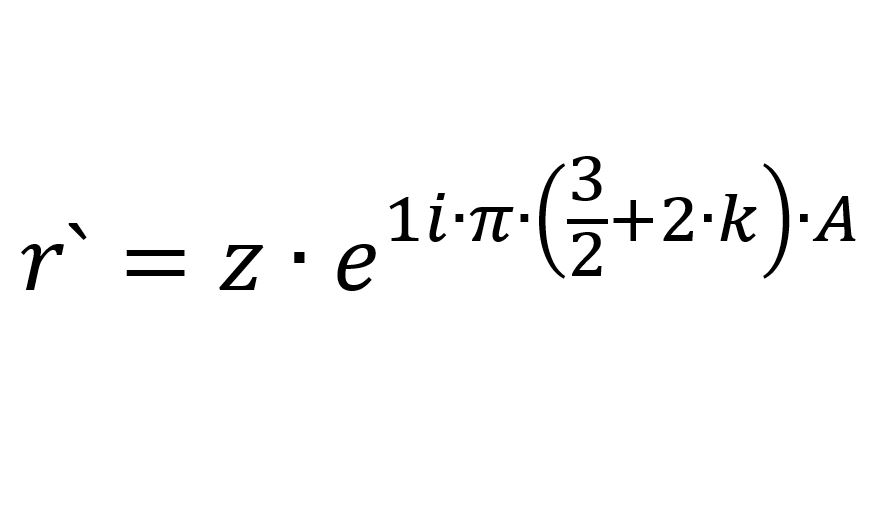Давно хотел я написать про матрицы Паули. Но каждый раз, когда я читал очередную чисто научную статью на схожую тему, задавал простой вопрос: "Дружище, ты за что так не любишь людей?". Поэтому во-первых статья в жанре "научно-популярный кейс", во-вторых из изначальной идеи статьи долго исключал все, что возможно, из лишнего и труднопонятного.
В-третьих, основной рецепт во введении, на первой же странице.
Мне не нравится, когда от букв в глазах рябит, или много не нужного лирического текста, или не очень понятно, где же практически полезный рецепт и линия повествования. Поэтому в основном тексте только суть, а все подробности кейса убраны под кат, для тех читателей, кому нужны подробности, а не простота.
Все что ниже, наверное, у кого-то опубликовано, но мне лично не попалось. С одной стороны, к моему сожалению, потому что сэкономил бы полгода своего досуга. С другой стороны, разобраться было увлекательно. Ну и буду рад, если кому знания о таком инструменте окажутся полезными, или хотя бы расширят кругозор.