Завтра искусственный интеллект поработит Землю и станет использовать человеков в качестве смешных батареек, поддерживающих функционирование его систем, а сегодня мы запасаемся попкорном и смотрим, с чего он начинает.
19 октября 2017 года команда Deepmind
опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён
sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.

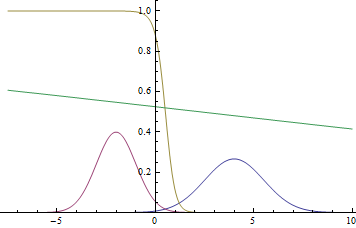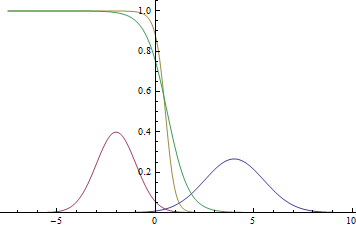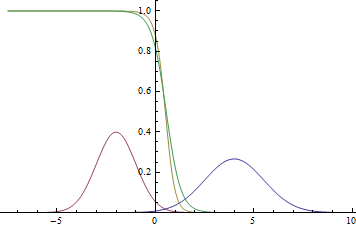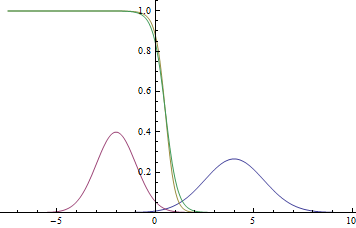



 Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест
Статистика приходит к нам на помощь при решении многих задач, например: когда нет возможности построить детерминированную модель, когда слишком много факторов или когда нам необходимо оценить правдоподобие построенной модели с учётом имеющихся данных. Отношение к статистике неоднозначное. Есть мнение, что существует три вида лжи: ложь, наглая ложь и статистика. С другой стороны, многие «пользователи» статистики слишком ей верят, не понимая до конца, как она работает: применяя, например, тест