Давайте поговорим о тех проблемах, с которыми приходится сталкиваться на сайтах для стримингового видео, и как организовать архитектуру такого сайта, чтобы было проще справляться с нагрузками.


Пользователь

Не стоит ожидать, что в текущем виде ChatGPT способна проделать за вас работу, поскольку она еще слишком нова и наивна, хотя и учится и совершенствуется с каждым днем. При этом он вполне может помогать искать ошибки в коде и быстро сгенерировать простой код. Но для выполнения этих задач нужны правильные промпты, написать которые иногда не так просто, как кажется. В этой статье увидите, какие промпты можно использовать для работы с ChatGPT, а также в целом больше узнаете о том, с какими микрозадачами он может помочь.

В CMF MODX Revolution изначально не предусмотрена возможность ставить задачи и привязывать их к ресурсам. Такое дополнение я тоже не нашел, да и было интересно разобраться в создании виджетов, поэтому придумал решение, как можно быстро реализовать такой функционал на своем сайте. Собственно, в этой статье хочу им поделиться.

Привет, Хабр! Меня зовут Никита Летов, я тимлид бэкенд-разработки мобильного приложения Росбанка для физических лиц. Этот пост входит в серию постов по разработке бэкенд-микросервисов на Java и Spring и является адаптацией моего доклада с JPoint 2022.
Также хочу предупредить, что данный пост не cookbook и не предоставляет идеально приготовленное решение какой-либо бизнес-проблемы. Это разбор одной технологии, которая при правильном использовании может помочь вам в решении реальной проблемы. А может и не помочь — всё зависит от ее природы.

Микросервисная архитектура – одна из самых полезных архитектур в индустрии программного обеспечения. При правильном подходе она может помочь в создании лучших программных приложений. Из этой статьи вы узнаете, что такое микросервисная архитектура, какие шаблоны проектирования необходимы для ее реализации, а также почему стоит и почему не стоит использовать эту архитектуру для вашего нового программного обеспечения.
Перед вами очередное руководство по Mockito. В нём я, с одной стороны, попытался описать функционал этой библиотеки так, чтобы незнакомый с нею читатель сразу получил возможность полноценно ею пользоваться, а не только общее представление о ней. С другой — я хотел сделать его достаточно компактным и структурированным, чтобы можно было быстро прочесть его целиком и быстро найти в нём что-то единожды прочитанное, но подзабытое. В общем, эта такая статья, какая бы пригодилась мне самому, когда я только столкнулся с этой библиотекой и не очень понимал, как она работает.
Полагаю, она и сейчас может пригодиться мне же — иногда я забываю что-то из этого, а вспоминать материал удобнее всего не по официальной документации или чужим статьям, а по собственному, скажем так, конспекту. Вместе с тем я старался построить текст так, чтобы он был удобен прежде всего для знакомства с Mockito с нуля, и кое-где подробно разбираю вроде бы очевидные вещи — не все из которых были для меня очевидными с самого начала.

Одним из важных шагов для обеспечения возможности настройки программных приложений является эффективное управление конфигурацией. Современные платформы предоставляют готовые функции для вывода параметров конфигурации.
Для некоторых параметров конфигурации имеет смысл не запускать приложение, если они недействительны.
Spring Boot предлагает нам удобный способ валидации параметров конфигурации. Мы собираемся связать входные значения со @ConfigurationProperties и использовать Bean Validation для их валидации.
«Понимание плана — это искусство, и чтобы овладеть им, нужен определённый опыт, …»Но можно обойтись и без него, если воспользоваться подходящим инструментом!

Я не гарантирую, что изложенные здесь трактовки общепринятых терминов и принципов совпадают с тем, что изложили в солидных научных статьях калифорнийские профессора во второй половине прошлого века. Я не гарантирую, что мои трактовки полностью разделялись или разделяются большинством IT-профессионалов в отрасли или научной среде. Я даже не гарантирую, что мои трактовки помогут вам на собеседовании, хоть и предполагаю, что будут небесполезны.
Но я гарантирую, что если отсутствие всякого понимания заменить моими трактовками и начать их применять, то код вами написанный будет проще сопровождать и изменять. Так же я прекрасно понимаю, что в комментариях мной написанное будут яростно дополнять, что позволит выправить совсем уж вопиющие упущения и нестыковки.
Столь малые гарантии поднимают вопросы о причинах, по которым статья пишется. Я считаю, что этим вещам должны учить везде, где учат программированию, вплоть до уроков информатики в школах с углублённым её изучением. Тем не менее, для меня стала пугающе нормальной ситуация, когда я узнаю, что собеседник мой коллега, причём работающий уже не первый год, но про инкапсуляцию «что-то там слышал». Необходимость собрать всё это в одном месте и давать ссылку при возникновении вопросов зрела давно. А тут ещё и мой «pet-project» дал мне изрядно пищи для размышлений.
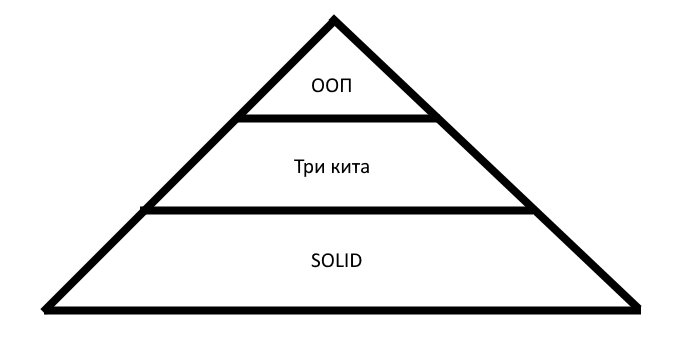
Тут мне могут возразить, что учить эти вещи в школе рановато, и вообще на ООП свет клином не сошёлся. Во-первых, это смотря как учить. Во-вторых, 70% материала этой статьи применимо не только к ООП. Что я буду отмечать отдельно.

 Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.
Клифф Клик — CTO компании Cratus (IoT сенсоры для улучшения процессов), основатель и сооснователь нескольких стартапов (включая Rocket Realtime School, Neurensic и H2O.ai) с несколькими успешными экзитами. Клифф написал свой первый компилятор в 15 лет (Pascal для TRS Z-80)! Наиболее известен за работу над С2 в Java (the Sea of Nodes IR). Этот компилятор показал миру, что JIT может производить качественный код, что стало одним из факторов становления Java как одной из основных современных программных платформ. Потом Клифф помог компании Azul Systems построить 864-ядерный мейнфрейм с софтом на чистой Java, который поддерживал паузы GC на 500-гигабайтной куче в пределах 10 миллисекунд. Вообще, Клифф успел поработать над всеми аспектами JVM.
Этот хабрапост — большое интервью с Клиффом. Мы поговорим на следующие темы:
Интервью ведут:

Добрый день, уважаемые читатели. В данной статье я расскажу о том, как распарсить число, записанное прописью на русском языке.
Умным данный парсер делает возможность извлечения чисел из текста с ошибками, допущенными в результате некорректного ввода или в результате оптического распознавания текста из изображения (OCR).
Для ленивых:
Ссылка на проект github: ссылка.
