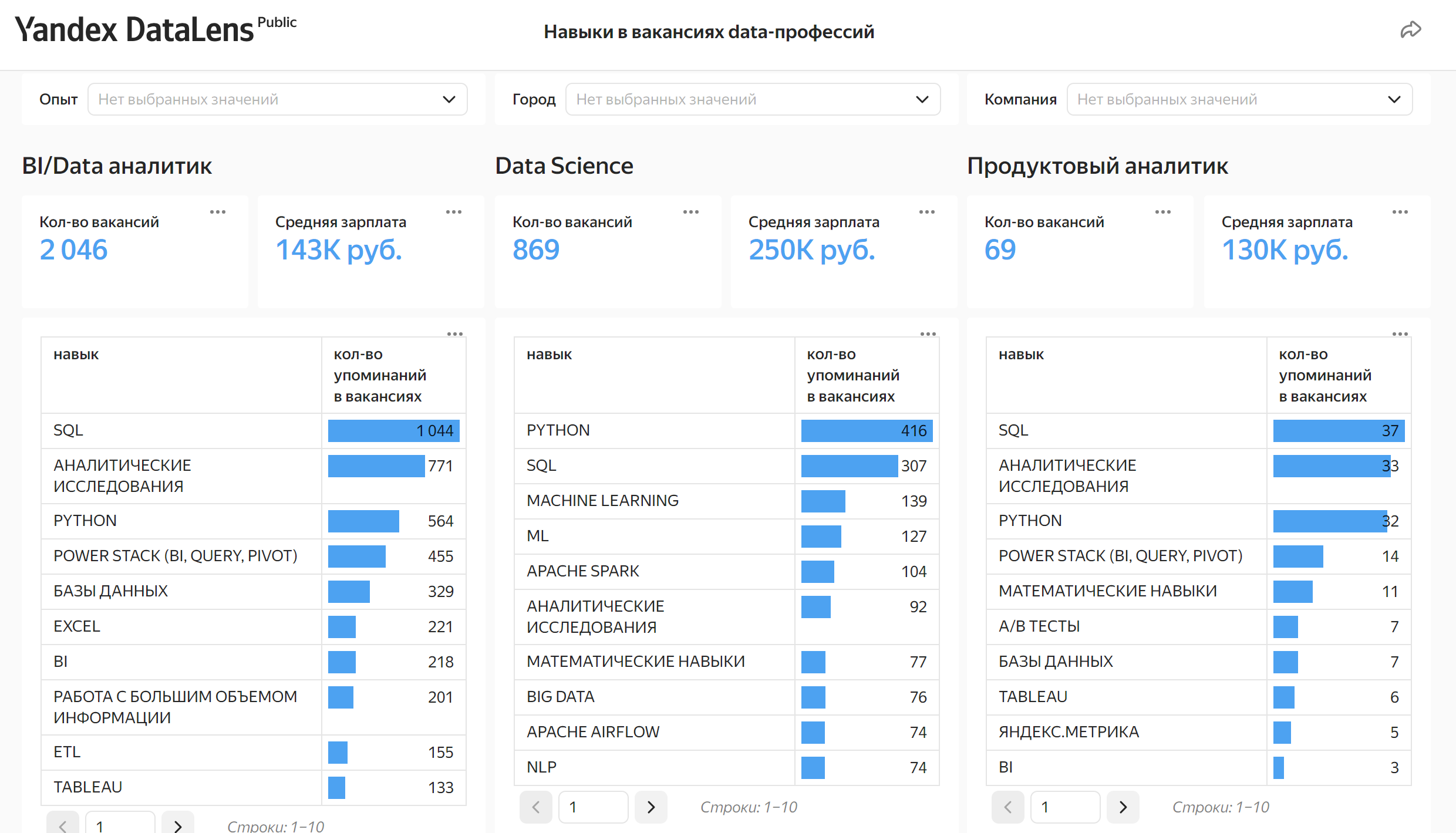
Одной из самых распространённых задач аналитики является формирование суждений о большой совокупности (например, о миллионах пользователей приложения), опираясь на данные лишь небольшой части этой совокупности - выборке. Можно ли сделать вывод о миллионной аудитории крупного мобильного приложения, собрав данные 100 пользователей? Или стоит собрать данные о 1000 пользователях? Какую вероятность ошибиться при анализе мы можем допустить: 5% или 1%? Относятся ли две выборки к одной совокупности, или между ними есть ощутимая значимая разница и они относятся к разным совокупностям? Точность прогноза и вероятность ошибки при ответе на эти и другие вопросы поддаются вполне конкретным расчётам и могут корректироваться в зависимости от потребностей продукта и бизнеса на этапе планирования и подготовки эксперимента. Рассмотрим подробнее, как параметры эксперимента и статистические критерии оказывают влияние на результаты анализа и выводы обо всей совокупности, а для этого смоделируем тысячу A/A, A/B и A/B/C/D тестов.