Перед нами стояла задача сравнения изображений (image matching) для поиска изображения максимально подобного данному изображению из коллекции. В этой статье я расскажу как мы использовали для этой задачи подход на основе нейронных сетей под названием AffNet. Кому интересно, прошу под кат.

Пользователь
Base64, Base32 и Base16 кодировки в .NET
3 мин

BaseN кодировки используются для кодирования двоичных данных в текстовый вид. Где N это размер текстового алфавита используемого для кодирования. Применяются BaseN кодировки для "подготовки данных" к передаче по текстовым протоколам (HTTP, SMTP) или нецифровым каналам (напр. печать на бумаге).
Самый популярный вариант такой кодировки это Base64. Сравниться по частоте применения может только Base16 известный как hexadecimal или просто hex. Инструменты для работы с ними есть в .NET еще с первых версий, но они не очень удобные.
Утки, Таиланд и T-SQL… или что может подстерегать программистов при работе с SQL Server?
33 мин
Туториал
Все начиналось довольно обыденно… Зачитывался Рихтером и усиленно штудировал Шилдта. Думал, что буду заниматься разработкой под .NET, но судьба на первом месяце работы распорядилась иначе. Один из сотрудников неожиданно покинул проект и во вновь образовавшуюся дыру докинули свежего людского материала. Именно тогда и началось мое знакомство с SQL Server.
С тех пор прошло чуть меньше 6 лет и вспомнить можно многое…
Про бывшего клиента Джозефа из Англии, который переосмыслил жизнь, за время отпуска в Таиланде, и в моем скайпе стал подписываться Жозефиной. Про веселых соседей по офису, с которыми приходилось сидеть в одной комнате: один страдал от аллергии на свежий воздух, а другой маялся от неразделенной любви к С++ дополняя это аллергией на солнечный свет. Один раз по команде свыше пришлось на время стать Александром отцом двух детей, чтобы изображать из себя обросшего скилами сениора по JS.
Docker в работе. Взгляд на его использование в Badoo (год спустя)
19 мин
Антон Турецкий (Badoo)

Сегодня я приглашу вас на такую внутреннюю кухню Badoo расскажу о том, нужен ли Docker нам. Вы попробуете сделать выводы для себя, нужен ли он вам. Этой информации на просторах Интернета, соответственно, нет, потому что она вся вот такая – в нашем тесном узком кругу.

В течение доклада я расскажу про самую значимую вещь, которая касается того, с чего надо начинать выполнение любой задачи. Надо решить, зачем вы ее делаете, зачем вы за это беретесь?
Для себя мы на эти вопросы ответили, без проблем у нас не было бы никакого внедрения. Какую-то часть проблем мы решаем. Я выделил основные из них, я расскажу вам о них и о том, как мы с ними справились. В конце я порекламирую нас, какие мы замечательные, как мы любим всякие-разные новые велосипеды, как мы их делаем, смотрим, изобретаем. Я вам их покажу, про них расскажу, вы составите какое-то свое мнение. Итак, поехали!
Тёплые ламповые грабли малого бизнеса на примере отдельно взятого магазина во Владимире
12 мин
Возможно, вам будет интересна история малого бизнеса на конкретном примере магазина во Владимире. Потому что это аккурат тот размер, когда процессы, модель и прочее важны менее, чем умение импровизировать в рамках здравого смысла. Как и всё в малом бизнесе. Ну и развеиваются многие иллюзии.

Наша «старая гвардия», владельцы франшиз во Владивостоке, Воронеже, Нижнем Новгороде, Новосибирске — они начинали почти с нуля, когда слово «Мосигра» ещё не было на слуху. Это люди, которые уже имели огромный опыт работы, и твёрдо знали, что и как надо делать с помещением, как реагировать на бесконечные звонки рекламщиков и как считать деньги. У них воровали в магазинах (в том числе сами сотрудники), они ссорились с конкурентами и задавливали их, они теряли деньги на неэффективной рекламе, сами подменяли заболевших аниматоров и продавцов, часто сами разбирались в отчётности и юридических вопросах. И иногда брали джек-пот на праздники.
Владимиру всё это только предстояло.
Наша «старая гвардия», владельцы франшиз во Владивостоке, Воронеже, Нижнем Новгороде, Новосибирске — они начинали почти с нуля, когда слово «Мосигра» ещё не было на слуху. Это люди, которые уже имели огромный опыт работы, и твёрдо знали, что и как надо делать с помещением, как реагировать на бесконечные звонки рекламщиков и как считать деньги. У них воровали в магазинах (в том числе сами сотрудники), они ссорились с конкурентами и задавливали их, они теряли деньги на неэффективной рекламе, сами подменяли заболевших аниматоров и продавцов, часто сами разбирались в отчётности и юридических вопросах. И иногда брали джек-пот на праздники.
Владимиру всё это только предстояло.
30 легковесных JavaScript плагинов и библиотек
5 мин
В это обзоре мы познакомимся с 30 бесплатными JavaScript плагинами и библиотеками, которые сфокусированы на определенных задачах. Это простые, полезные и легкие решения, которые помогут сделать процесс веб-дизайна и разработки гораздо проще и быстрее.
Как и следовало ожидать ниже вы найдете много плагинов для создания ползунков, галерей с изображениями, адаптивных меню, а также много других полезных плагинов и библиотек. Также в списке представлены плагины, которые предлагают действительно уникальные функциональные возможности. Давайте взглянем на список!
Как и следовало ожидать ниже вы найдете много плагинов для создания ползунков, галерей с изображениями, адаптивных меню, а также много других полезных плагинов и библиотек. Также в списке представлены плагины, которые предлагают действительно уникальные функциональные возможности. Давайте взглянем на список!
10 особенностей Webpack
8 мин
Перевод
Webpack считается лучшим инструментом для сборки приложений на React и Redux. Полагаю, многие из тех, кто сегодня использует Angular 2 и другие фреймворки, не обходят вниманием и Webpack. И поскольку начинать работу с данным инструментом всегда непросто, я решил посвятить этой теме несколько публикаций в надежде облегчить старт другим разработчикам и заодно продемонстрировать некоторые особенности Webpack.

Когда «О» большое подводит
8 мин
Перевод
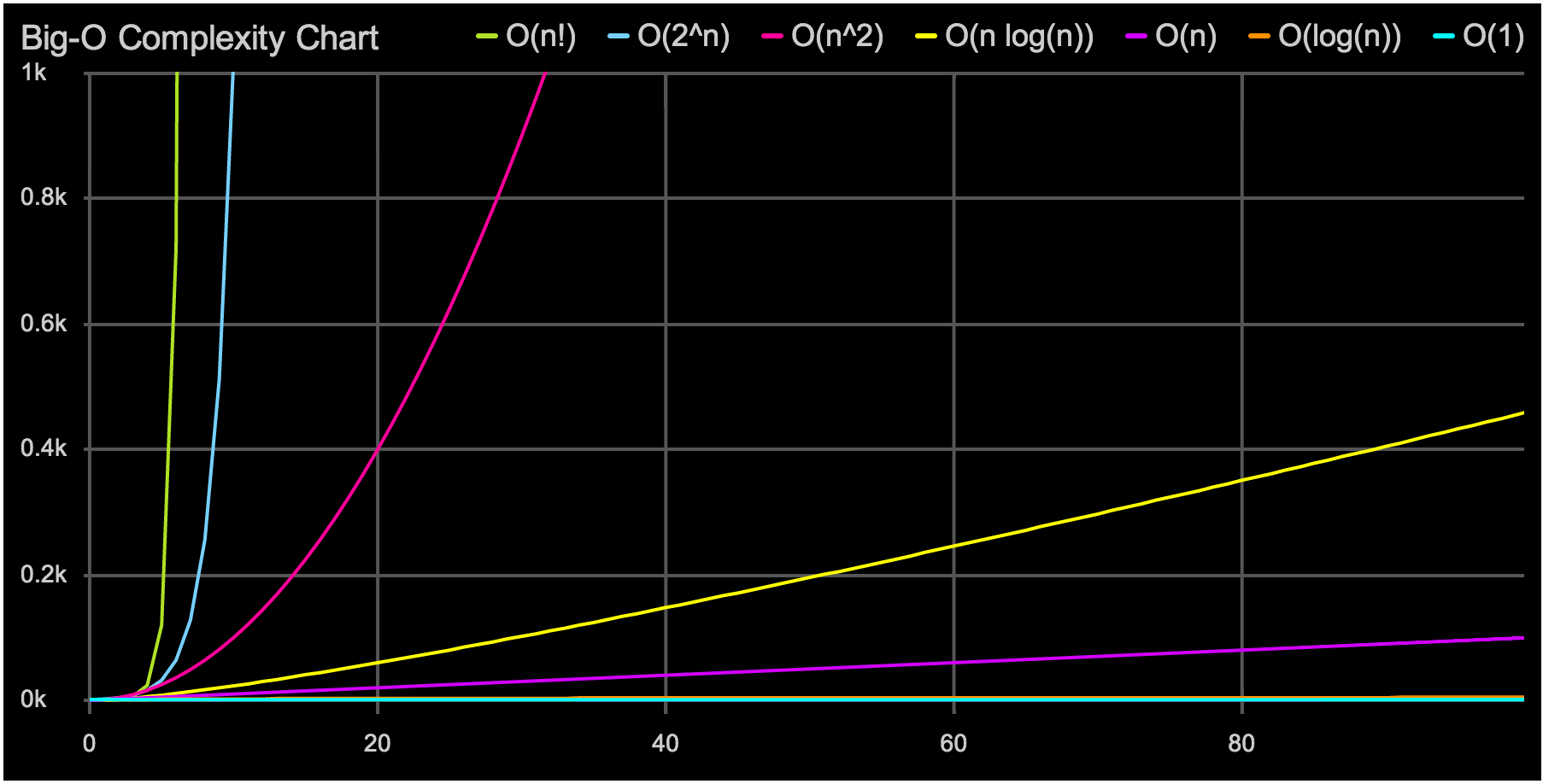
"О" большое — это отличный инструмент. Он позволяет быстро выбрать подходящую структуру данных или алгоритм. Но иногда простой анализ "О" большого может обмануть нас, если не подумать хорошенько о влиянии константных множителей. Пример, который часто встречается при программировании на современных процессорах, связан с выбором структуры данных: массив, список или дерево.
Память, медленная-медленная память
В начале 1980-х время, необходимое для получения данных из ОЗУ и время, необходимое для произведения вычислений с этими данными, были примерно одинаковым. Можно было использовать алгоритм, который случайно двигался по динамической памяти, собирая и обрабатывая данные. С тех пор процессоры стали производить вычисления в разы быстрее, от 100 до 1000 раз, чем получать данные из ОЗУ. Это значит, что пока процессор ждет данных из памяти, он простаивает сотни циклов, ничего не делая. Конечно, это было бы совсем глупо, поэтому современные процессоры содержат несколько уровней встроенного кэша. Каждый раз когда вы запрашиваете один фрагмент данных из памяти, дополнительные прилегающие фрагменты памяти будут записаны в кэш процессора. В итоге, при последовательном проходе по памяти можно получать к ней доступ почти настолько же быстро, насколько процессор может обрабатывать информацию, потому что куски памяти будут постоянно записываться в кэш L1. Если же двигаться по случайным адресам памяти, то зачастую кэш использовать не получится, и производительность может сильно пострадать. Если хотите узнать больше, то доклад Майка Актона на CppCon — это отличная отправная точка (и отлично проведенное время).
Frontend Dev Conf 2016: герои, события и сюрпризы конференции
3 мин
Чуть переведя дыхание после прошедшего события, а именно 2 недели, мы готовы в красках рассказать, как же прошла традиционная конференция Frontend Dev Conf.
16 апреля в Минске состоялась международная конференция Frontend Dev Conf! Уже в четвертый раз нам удалось объединить под ее началом более 300 участников и сделать FDConf громким событием во frontend-тусовке.

Expressions в C# — impress yourself!
9 мин
.NET 4.0 уже не за горами и принесет кучу всего нового, нужного и не очень, крутого и суперкрутого. Однако и в старом добром .NET 3.5 есть много разных интересных фич, которые не используются в повседенвной работе, но иногда здорово облегчают жизнь разработчикам. Одна из таких замечательных штук — это Expressions.
Random User-Agent — версия вторая
9 мин
Прошло два года с того момента, как вышла первая версия этого расширения для Chromium-based браузеров (работает в Google Chrome, Yandex.Browser и т.д.), задача которого проста и понятна — скрывать настоящий User-Agent. На данный момент это расширение работает у +6.000 пользователей (что очень скромно), и несколько дней назад получил на почту письмо с просьбой его немного доработать. Оценив состояние кода, к которому два года никто не притрагивался, было решено — переписывать его с нуля. Четыре дня работы, и вуаля — встречаем свежую мажорную версию, значительно улучшенную и с новым функционалом.

Под катом будут некоторые мысли как по поводу чуть-более анонимного веб-серфинга, так и настройке браузера Google Chrome, и почему это расширение может быть полезно. Чуть-чуть опытные анонимусы не найдут в посте для себя чего-либо интересного, поэтому как для них, так и для самых нетерпеливых, традиционно — исходники на GitHub и расширение в Google Webstore.
Начало перевода «legacy» Angular JS проекта на Angular 1.5 Components / ES6 и TypeScript
12 мин
Туториал
В статье я хотел поделиться уже работающим в продакшене вариантом начала постепенной миграции «legacy» Angular JS проекта на все хорошее, что дал нам Angular 1.5 и связку ES6/TypeScript.
Итак дано: стандартный проект, разработка которого началась еще на бородатом Angular 1.2 (человеком, далеким от мира фронтенда), представленный в более или менее стандартном виде — отдельно по директориям сгруппированы модули с роутами, сервисы, директивы и невероятно жирные контроллеры, функционал из которых потихоньку выделяестся в отдельные директивы. Адский поток фич к реализации, полное отсутствие моделей, доступ к объектам и их модификации — как бог на душу положит.
Также в проекте уже присутствует более или менее налаженный и прописанный процесс сборки/минификации и деплоя всего этого добра при помощи gulp, CI и прочее.
Задача — не уйти в себя на поддержке проекта в таком виде, в каком он есть, начать писать хороший, поддерживаемый код, научиться чему-то новому.
Итак дано: стандартный проект, разработка которого началась еще на бородатом Angular 1.2 (человеком, далеким от мира фронтенда), представленный в более или менее стандартном виде — отдельно по директориям сгруппированы модули с роутами, сервисы, директивы и невероятно жирные контроллеры, функционал из которых потихоньку выделяестся в отдельные директивы. Адский поток фич к реализации, полное отсутствие моделей, доступ к объектам и их модификации — как бог на душу положит.
Также в проекте уже присутствует более или менее налаженный и прописанный процесс сборки/минификации и деплоя всего этого добра при помощи gulp, CI и прочее.
Задача — не уйти в себя на поддержке проекта в таком виде, в каком он есть, начать писать хороший, поддерживаемый код, научиться чему-то новому.
Перехват функций .NET/CLR
16 мин
Иногда при разработке программного обеспечения требуется встроить дополнительную функциональность в уже существующие приложения без модификации исходного текста приложений. Более того, зачастую сами приложения существуют только в скомпилированном бинарном виде без наличия исходного текста. Широко известным способом решения указанной задачи является т.н. “сплайсинг” – метод перехвата функций путем изменения кода целевой функции. Обычно при сплайсинге первые байты целевой функции перемещаются по другим адресам, а на их исходное место записывается команда безусловного перехода (jmp) на замещающую функцию. Поскольку сплайсинг требует низкоуровневых операций с памятью, то он осуществляется с использованием языка ассемблера и С/C++, что также накладывает определенные ограничения на реализацию замещающих функций – они обычно также реализованы на С/C++ (реже на ассемблере).
Метод сплайсинга для перехвата API-функций в Windows широко описан в Интернете и в различных литературных источниках. Простота указанного перехвата определяется следующими факторами:
Реализация замещающих функций на C/C++ при перехвате API-функций является оптимальным вариантом, поскольку Windows API реализовано, как известно, на языке C, и замещающие функции могут оперировать теми же понятиями, что и заменяемые.
Метод сплайсинга для перехвата API-функций в Windows широко описан в Интернете и в различных литературных источниках. Простота указанного перехвата определяется следующими факторами:
- целевая функция является статической – она сразу присутствует в памяти загруженного модуля;
- адрес целевой функции легко определить (через таблицу экспорта модуля или функцию GetProcAddress).
Реализация замещающих функций на C/C++ при перехвате API-функций является оптимальным вариантом, поскольку Windows API реализовано, как известно, на языке C, и замещающие функции могут оперировать теми же понятиями, что и заменяемые.
Список полезных ресурсов по Microsoft SQL Server
5 мин
Список из 147 бесплатных и платных интернет ресурсов для изучения и работы с Microsoft SQL Server.
Статья в формате markdown на английском языке доступна на Github
SSD + raid0 — не всё так просто
6 мин
Вступление
Коллеги с соседнего отдела (UCDN) обратились с довольно интересной и неожиданной проблемой: при тестировании raid0 на большом числе SSD, производительность менялась вот таким вот печальным образом:
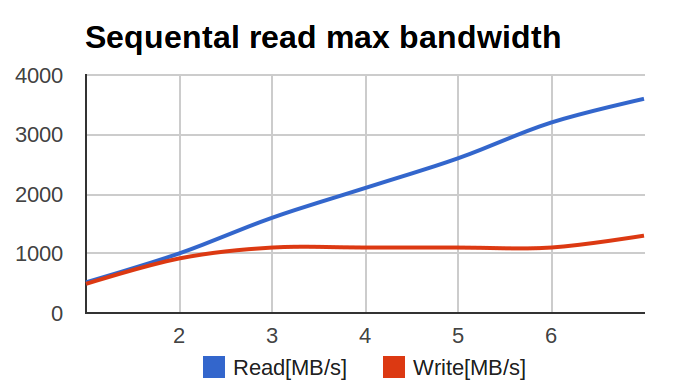
По оси X — число дисков в массиве, по оси Y — мегабайтов в секунду.
Я начал изучать проблему. Первичный диагноз был простой — аппаратный рейд не справился с большим числом SSD и упёрся в свой собственный потолок по производительности.
После того, как аппаратный рейд выкинули и на его место поставили HBA, а диски собрали в raid0 с помощью linux-raid (его часто называют 'mdadm' по названию утилиты командной строки), ситуация улучшилась. Но не прошла полностью -цифры возросли, но всё ещё были ниже рассчётных. При этом ключевым параметром были не IOPS'ы, а многопоточная линейная запись (то есть большие куски данных, записываемых в случайные места).
Ситуация для меня была необычной — я никогда не гонялся за чистым bandwidth рейдов. IOPS'ы — наше всё. А тут — надо многомногомного в секунду и побольше.
Адские графики
Я начал с определения baseline, то есть производительности единичного диска. Делал я это, скорее, для очистки совести.
Вот график линейного чтения с одной SSD.
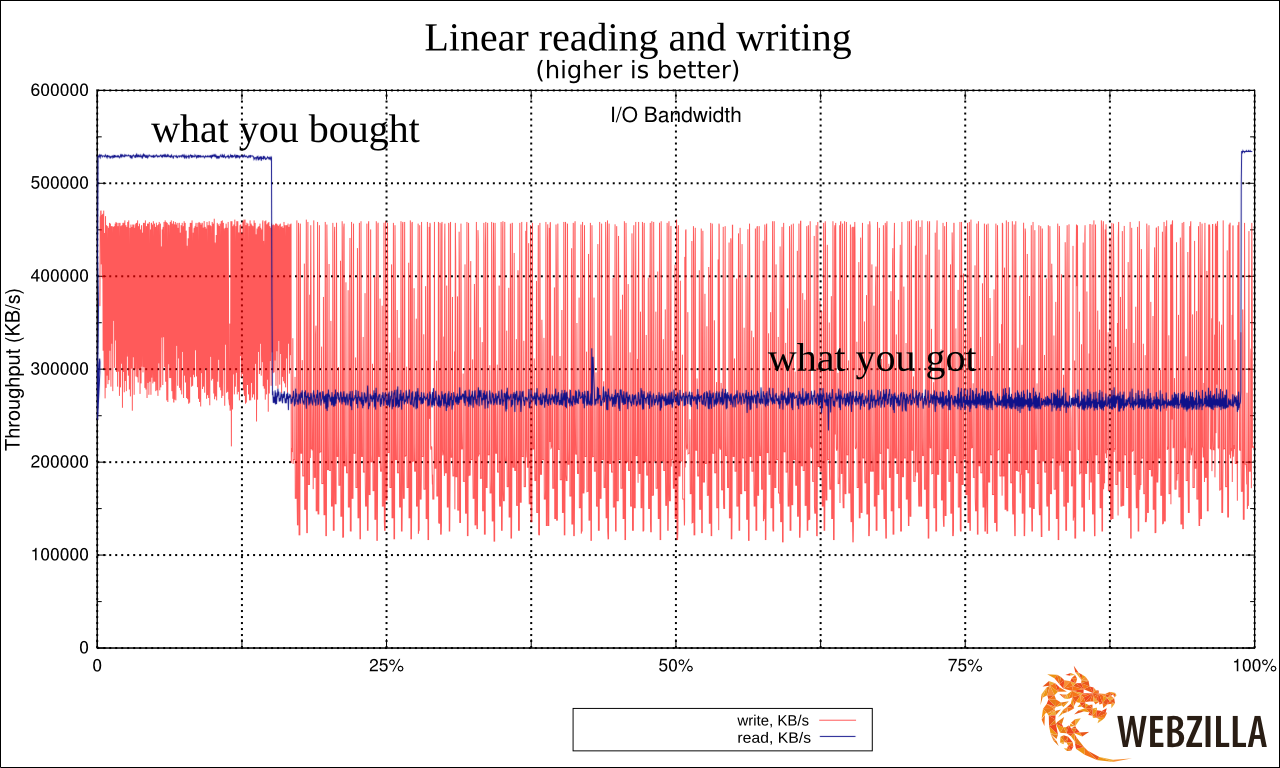
Увидев результат я реально взвился. Потому что это очень сильно напоминало ухищрения, на которые идут производители дешёвых USB-флешек. Они помещают быструю память в районы размещения FAT (таблицы) в FAT32 (файловой системе) и более медленную — в район хранения данных. Это позволяет чуть-чуть выиграть по производительности при работе с мелкими операциями с метаданными, при этом предполагая, что пользователи, копирующие большие файлы во-первых готовы подождать, а во вторых сами операции будут происходить крупными блоками. Подробнее про это душераздирающее явление: lwn.net/Articles/428584
Как на самом деле работает протокол Биткоин
28 мин
Перевод
(Замечательное объяснение принципов работы сети Bitcoin авторства Michael Nielsen. Много текста, немного картинок. Обо всех корявостях перевода — в личку, буду исправлять по мере обнаружения)
Много тысяч статей было написано для того, чтобы объяснить Биткоин — онлайн, одноранговую (p2p) валюту. Большинство из этих статей поверхностно рассказывают суть криптографического протокола, опуская многие детали. Даже те статьи, которые «копают» глубже, часто замалчивают важные моменты. Моя цель в этой публикации — объяснить основные идеи, лежащие в протоколе Биткоин в ясной, легкодоступной форме. Мы начнем с простых принципов, далее пойдем к широкому теоретическому пониманию, как работает протокол, а затем копнем глубже, рассматривая сырые (raw) данные в транзакции Биткоин.
Много тысяч статей было написано для того, чтобы объяснить Биткоин — онлайн, одноранговую (p2p) валюту. Большинство из этих статей поверхностно рассказывают суть криптографического протокола, опуская многие детали. Даже те статьи, которые «копают» глубже, часто замалчивают важные моменты. Моя цель в этой публикации — объяснить основные идеи, лежащие в протоколе Биткоин в ясной, легкодоступной форме. Мы начнем с простых принципов, далее пойдем к широкому теоретическому пониманию, как работает протокол, а затем копнем глубже, рассматривая сырые (raw) данные в транзакции Биткоин.
Короткая шпаргалка по блокировкам при чтении и изменении данных в зависимости от уровня изоляции транзакции в MSSQL
3 мин
Read Uncommitted
Read Committed + read_committed_snapshot off
(alter database xxx set read_committed_snapshot off)
- если в одной транзакции поменять данные — селект этих данных (в другой транзакции или без транзакции) не будут ждать окончания первой транзакции и вернут записанные данные незакомиченных транзакций
- если в одной транзакции считать данные — апдейты этих данных в другой транзакции не будут ждать окончания первой транзакции
- шаред локи не используются. Что аналогично установке NOLOCK хинта во все селекты в Read Commited
- эксклюзивные локировки устанавливаются в процессе выполнения стейтмента и снимаются по окончанию транзакции
(alter database xxx set read_committed_snapshot off)
- если в одной транзакции поменять данные — селект этих данных (в другой транзакции или без транзакции) будут ждать окончания первой транзакции. Селект с NOLOCK хинтом вернёт изменённые, но не закомиченные данные.
- если в одной транзакции считать данные — апдейты этих данных в другой транзакции не будут ждать окончания первой транзакции
- шаред локировки устанавливаются в процессе работы стейтмента и снимаются по окончанию стейтмента
- эксклюзивные локировки устанавливаются в процессе выполнения стейтмента и снимаются по окончанию транзакции
Целесообразность и преимущества применения серверных накопителей, построение RAID-массивов, стоит ли экономить и когда?
7 мин
На рынке доступно большое количество накопителей различных скоростей, различных производителей. Далеко не все четко понимают, какой диск лучше приобрести и для какой задачи и зачем порой лучше заплатить больше, а когда можно сэкономить. В этой статье я постараюсь прояснить основные моменты и сделать проблему выбора более простой. Статья будет полезна не только тем, кто хочет купить/арендовать выделенный сервер, но и тем, кто хочет получить надежное хранилище информации дома. После прочтения материала станет понятным, почему не всегда целесообразно арендовать desktop-решения в low-cost дата-центрах и лучше остановить выбор на более надежном, серверном железе.
Как мы рассылали SMS со старой Nokia и телефона на Android
4 мин
Примерно год назад мы запустили свой маленький проект с оповещениями о поломках Московского метро.
Самой главной проблемой в нем оказалась рассылка смс. Мы не ожидали, что проект понравится и у нас будет 1500+ регистраций. В самом лучшем случае мы расчитывали человек на 300. Этим мы были приятно удивлены.
Полный список флагов трассировки Microsoft SQL Server
64 мин
Microsoft SQL Server Флаги Трассировки
Полный список Microsoft SQL Server флагов трассировки (359 флагов трассировки на текущий момент).
ПОМНИТЕ: Будьте предельно осторожны с флагами трассировки, проверяйте их влияние в первую очередь в тестовой среде.