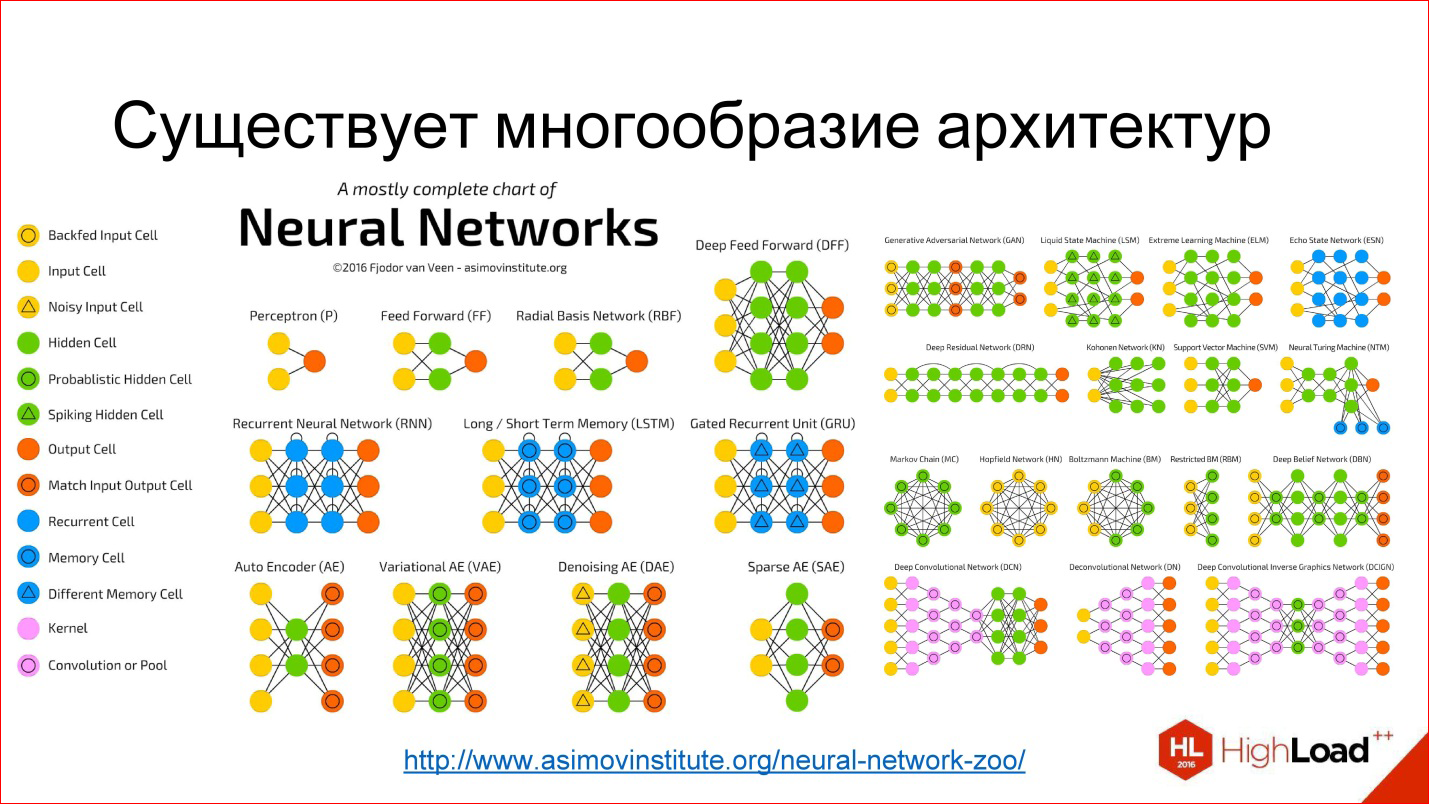
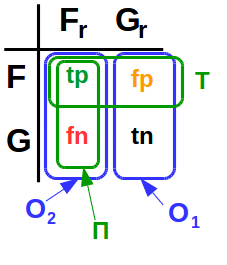
Введение в теорию
Обучение на ассоциативных правилах (далее Associations rules learning — ARL) представляет из себя, с одной стороны, простой, с другой — довольно часто применимый в реальной жизни метод поиска взаимосвязей (ассоциаций) в датасетах, или, если точнее, айтемсетах (itemsests). Впервые подробно об этом заговорил Piatesky-Shapiro G [1] в работе “Discovery, Analysis, and Presentation of Strong Rules.” (1991) Более подробно тему развивали Agrawal R, Imielinski T, Swami A в работах “Mining Association Rules between Sets of Items in Large Databases” (1993) [2] и “Fast Algorithms for Mining Association Rules.” (1994) [3].


 Это будет длиннопост. Я давно хотел написать этот обзор, но
Это будет длиннопост. Я давно хотел написать этот обзор, но