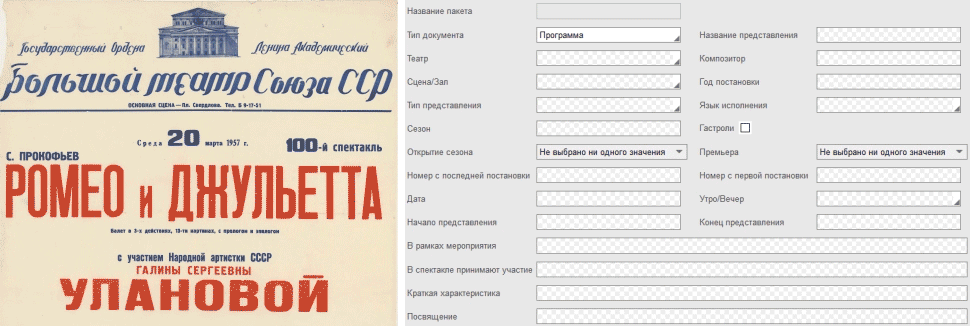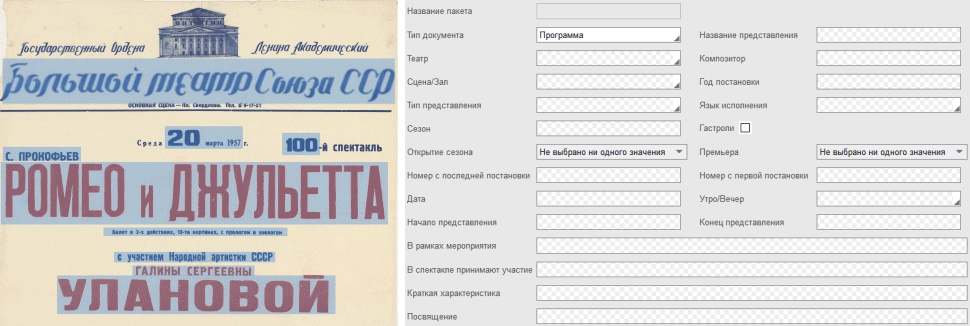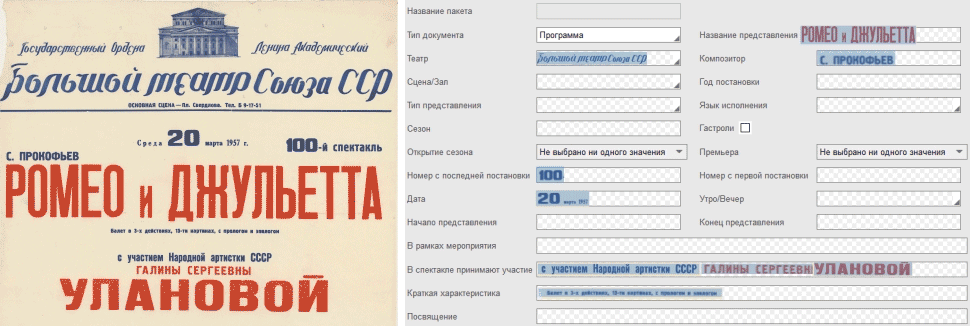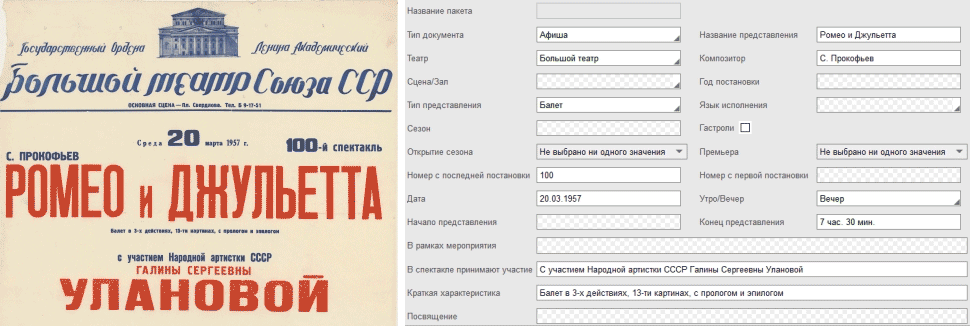
Привет! Меня зовут Вадим Щемелинин, я владелец продукта по видеоаналитике в СИБУРе.
Как мы уже неоднократно писали, наши объекты — это довольно большие производства, как с точки зрения занимаемой площади, так и количества различных установок и узлов. Чтобы всё это работало и не возникало каких-то ситуаций, способных вызвать остановку производственного процесса, за каждым узлом нужно следить. Поэтому у нас есть и специальные люди, которые этим занимаются, и приложение для мобильных обходов, которое существенно упрощает этим людям жизнь.

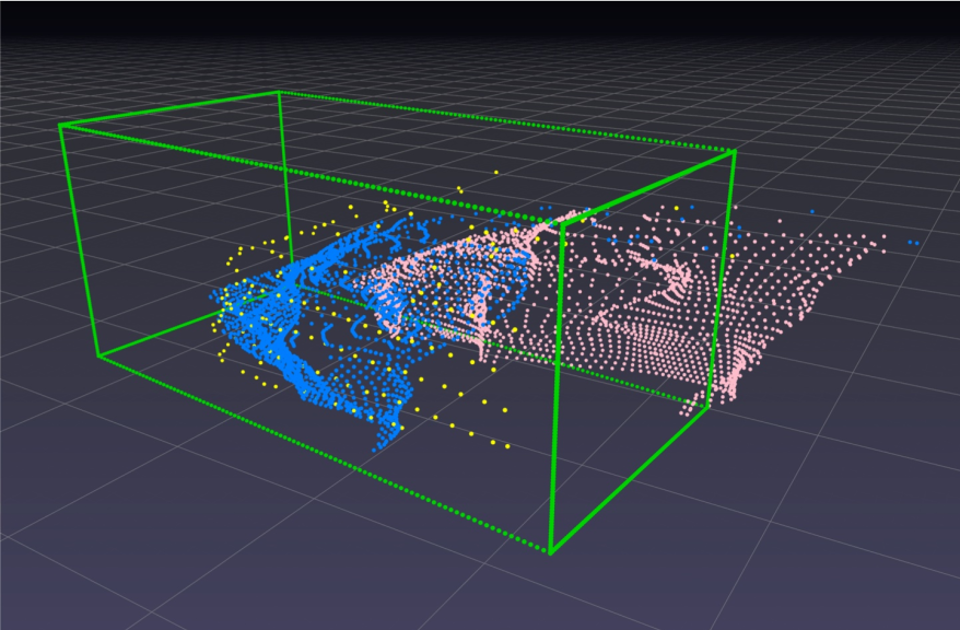
Отдельно здесь стоит рассказать про видеоаналитику. Она может решать разные задачи — повышать качество продукции благодаря автоматическому контролю и отбраковке, помогать исключить внезапные остановы производственных линий, своевременно предупреждая оператора о необходимости вмешаться, контролировать соблюдение правил промышленной безопасности, что для промышленного объекта является задачей номер один. Что в принципе можно анализировать, просматривая видео с объектов (и нужно ли его просматривать), как видеоаналитика помогает экономить время и средства, на чем у нас все работает — об этом под катом.
Как мы уже неоднократно писали, наши объекты — это довольно большие производства, как с точки зрения занимаемой площади, так и количества различных установок и узлов. Чтобы всё это работало и не возникало каких-то ситуаций, способных вызвать остановку производственного процесса, за каждым узлом нужно следить. Поэтому у нас есть и специальные люди, которые этим занимаются, и приложение для мобильных обходов, которое существенно упрощает этим людям жизнь.
Отдельно здесь стоит рассказать про видеоаналитику. Она может решать разные задачи — повышать качество продукции благодаря автоматическому контролю и отбраковке, помогать исключить внезапные остановы производственных линий, своевременно предупреждая оператора о необходимости вмешаться, контролировать соблюдение правил промышленной безопасности, что для промышленного объекта является задачей номер один. Что в принципе можно анализировать, просматривая видео с объектов (и нужно ли его просматривать), как видеоаналитика помогает экономить время и средства, на чем у нас все работает — об этом под катом.






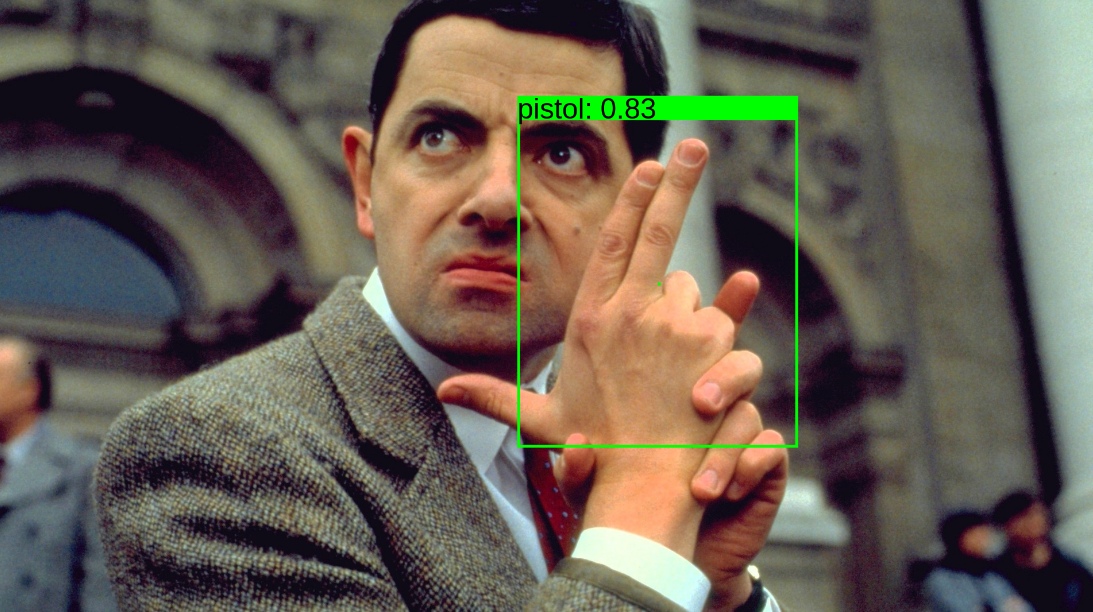

 Мы регулярно обучаем
Мы регулярно обучаем