

Меня зовут Денис (tg: @chckdskeasfsd), и это история о том почему в опенсурсе нет TTS с нормальными ударениями и как я пытался это исправить.
Меня зовут Денис (tg: @chckdskeasfsd), и это история о том почему в опенсурсе нет TTS с нормальными ударениями и как я пытался это исправить.

Планировщик движения беспилотного автомобиля — это алгоритм-помощник, который общается с другими участниками движения посредством манёвров. То есть он действует так, чтобы другим было понятно, куда поедет беспилотник, и сам по действиям других пытается определить, кто куда будет двигаться и почему.
В диалоговых системах совсем недавно произошла революция из-за появления ChatGPT. В беспилотных автомобилях революции, к сожалению, пока не произошло, но если это случится, то как раз в той области, про которую будет мой рассказ.
Под катом — детальный разбор логики движения беспилотника, примеры свёрточных и трансформерных архитектур моделей для предсказания движения и много формул для расчёта вероятных траекторий других машин и пешеходов. А ещё я расскажу, в чём преимущества машинного обучения перед эвристиками и чем может помочь Reinforcement Learning.



DeepNude — это технология, использующая нейросети для создания изображений обнаженных тел на основе одетых фотографий или видео. Суть этой технологии заключается в том, чтобы "снять" одежду с изображения человека с помощью искусственного интеллекта и показать, как, предположительно, выглядит тело человека под одеждой.
Итак, в данной статье поговорим о пикантных и для некоторых людей непристойных темах, которые больше всего интересуют наше общество - обнаженное тело. Сделаем обзор таких сервисов как: Deepnude.ai, Deepfake.com, DeepSwap.ai, SoulGen и прочих.



Эта история началась в начале марта этого года. ChatGPT тогда был в самом расцвете. Мне в Telegram пришёл Саша Кукушкин, с которым мы знакомы довольно давно. Спросил, не занимаемся ли мы с Сашей Николичем языковыми моделями для русского языка, и как можно нам помочь.
И так вышло, что мы действительно занимались, я пытался собрать набор данных для обучения нормальной базовой модели, rulm, а Саша экспериментировал с существующими русскими базовыми моделями и кустарными инструктивными наборами данных.
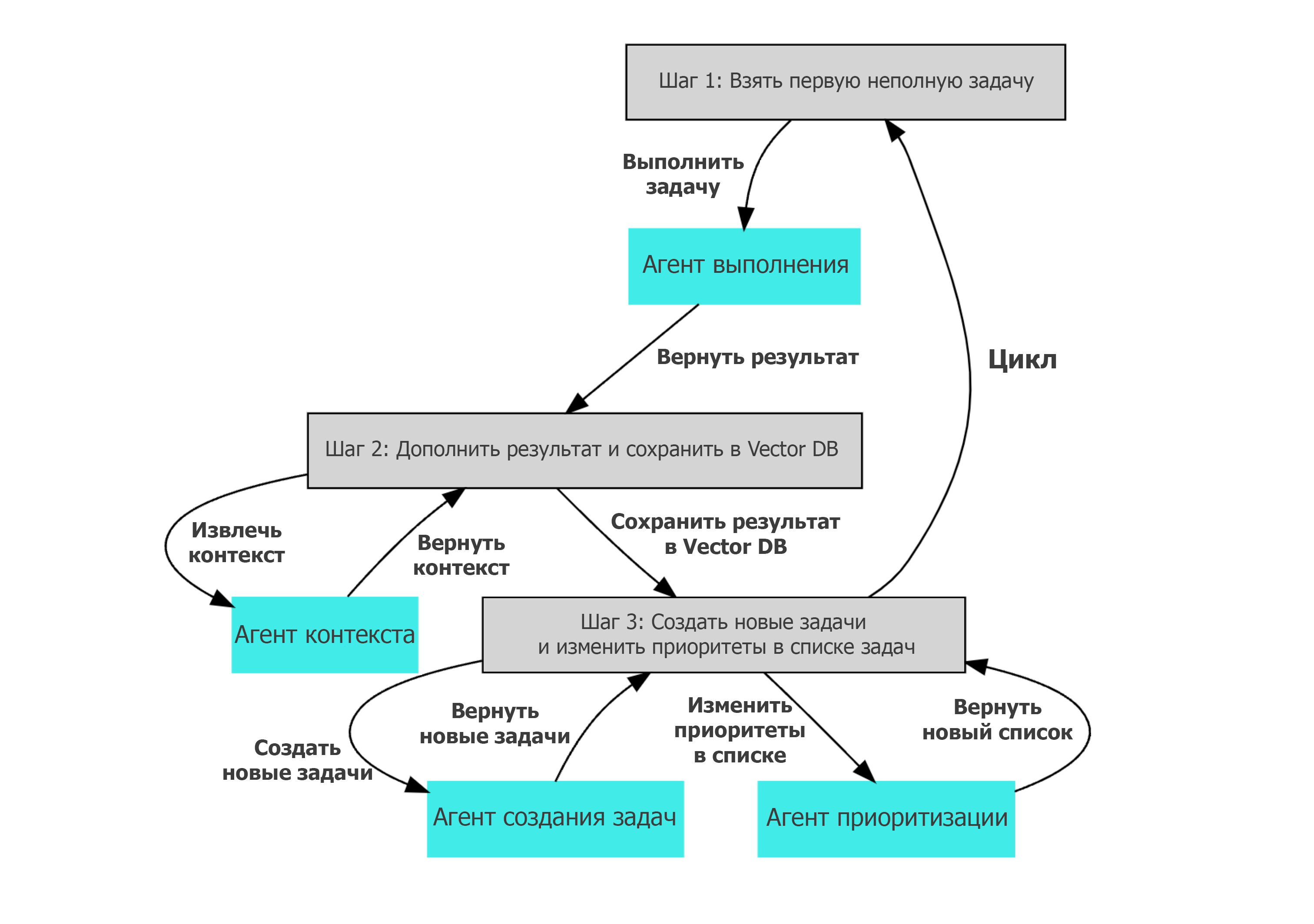
После этого мы какое-то время продолжали какое-то время делать всё то же самое. Я потихоньку по инерции расширял rulm новыми наборами данных. Посчитав, что обучить базовую модель нам в ближайшее время не светит, мы решили сосредоточиться на дообучении на инструкциях и почти начали конвертировать то, что есть, в формат инструкций по аналогии с Flan. И тут меня угораздило внимательно перечитать статью.

Поскольку ChatGPT последних версий недосягаем для честной российской белошвейки, все мы возлагаем огромные надежды на отечественного производителя.

2023 год можно смело называть годом бурного развития генеративного искусственного интеллекта. Это касается не только привычной нам модальности изображений (Kandinsky 2.1, Stable Diffusion XL, IF, Шедеврум и др.), но и текстовой (ChatGPT, LLaMA, Falcon и др.), и даже модальности видео (GEN-2, CogVideo и др.). При этом ни в одном из направлений выделить объективного лидера почти невозможно — все команды стараются равномерно двигаться вперёд и повышать качество синтеза. Текстовые чат‑боты научились взаимодействовать с внешними системами посредством плагинов, синтез изображений вышел на уровень фотореалистичных генераций, длина генерируемых видео постепенно увеличивается с сохранением сюжетной связности между кадрами. И такой прогресс обусловлен уже не только наращиванием вычислительных мощностей, но и большим числом неординарных архитектурных решений, которые позволяют добиваться лучшего качества.
С момента выхода Kandinsky 2.1 (4 апреля 2023 года) прошло чуть больше трёх месяцев, и вот сегодня мы анонсируем новую версию модели в линейке 2.X. И если архитектурно модель не претерпела кардинальных изменений, то в части расширения функционала получила существенное развитие. В первую очередь, мы сделали упор на повышение качества генераций и их разрешении, а также новых возможностях синтеза изображений.

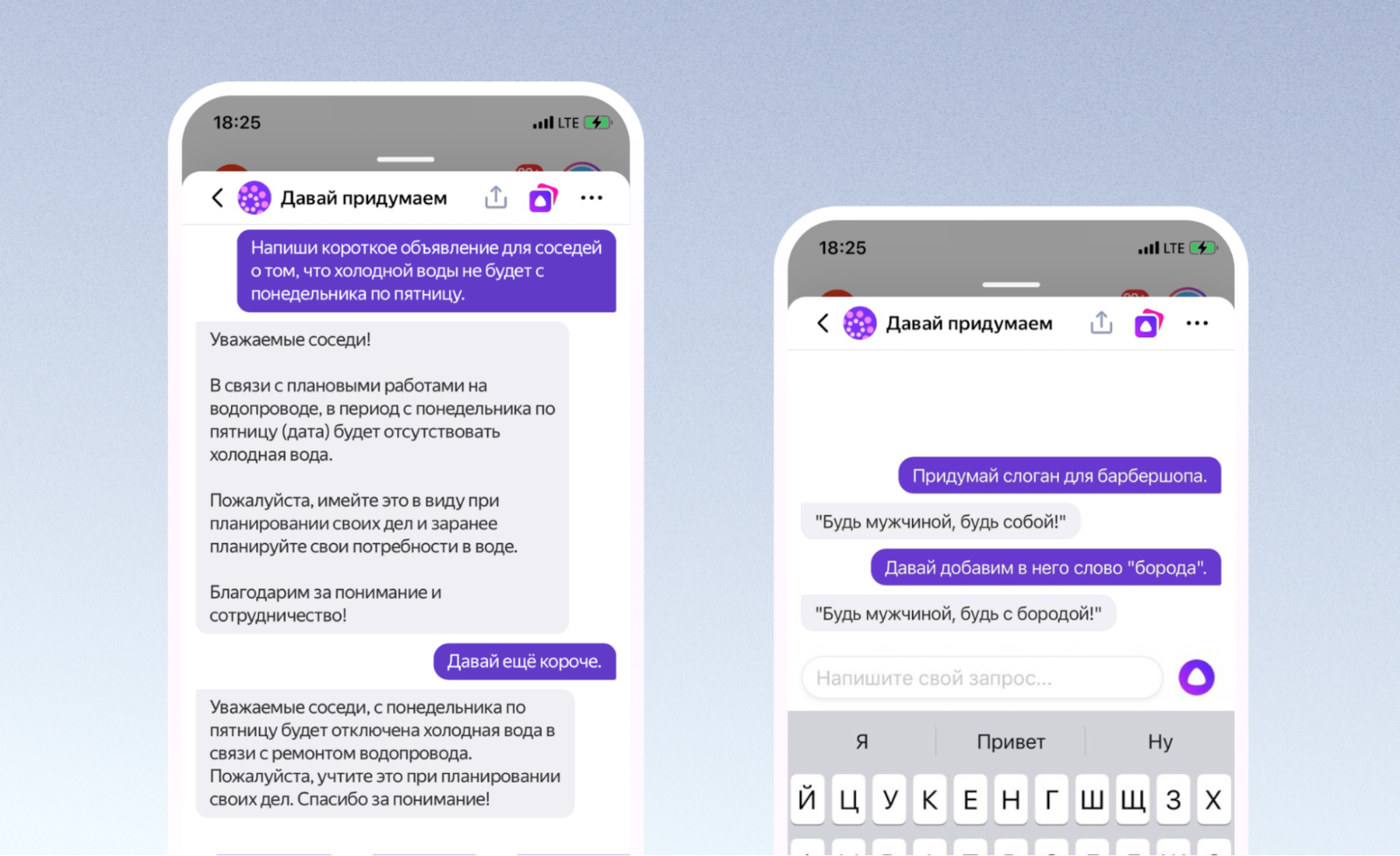
Искусственный интеллект (ИИ) проникает во все сферы нашей жизни, и одним из ярких примеров такого прогресса является ChatGPT, разработанный OpenAI. Сегодня более 100 000 000 пользователей уже вовлечены в использование этого интеллектуального чат-бота, а число его возможных применений продолжает расти. Благодаря своим навыкам в обработке естественного языка и пониманию контекста, ChatGPT успешно зарекомендовал себя в образовательных проектах, бизнесе, научных исследованиях и многих других областях. На дискуссии Artezio мы собрали экспертов, чтобы обсудить, как ChatGPT меняет наш подход к общению, его преимущества и некоторые опасения, возникающие в связи с использованием ИИ в повседневной жизни. Представляем краткий обзор дискуссии в блоге ЛАНИТ.

Ранее мы рассказывали о своих впечатлениях и результатах тестирования приложений на основе нейросети. В своей работе на платформе «РСХБ в цифре» мы активно используем Midjourney и искусственный интеллект. В новой статье хотим поделиться советами, которые позволят с нуля разобраться в основных функциях и командах, чтобы приступить к созданию интересных изображений с помощью этого приложения.
То, что ChatGPT может автоматически генерировать что-то, что хотя бы на первый взгляд похоже на написанный человеком текст, удивительно и неожиданно. Но как он это делает? И почему это работает? Цель этой статьи - дать приблизительное описание того, что происходит внутри ChatGPT, а затем исследовать, почему он может так хорошо справляться с созданием более-менее осмысленного текста. С самого начала я должен сказать, что собираюсь сосредоточиться на общей картине происходящего, и хотя я упомяну некоторые инженерные детали, но не буду глубоко в них вникать. (Примеры в статье применимы как к другим современным "большим языковым моделям" (LLM), так и к ChatGPT).

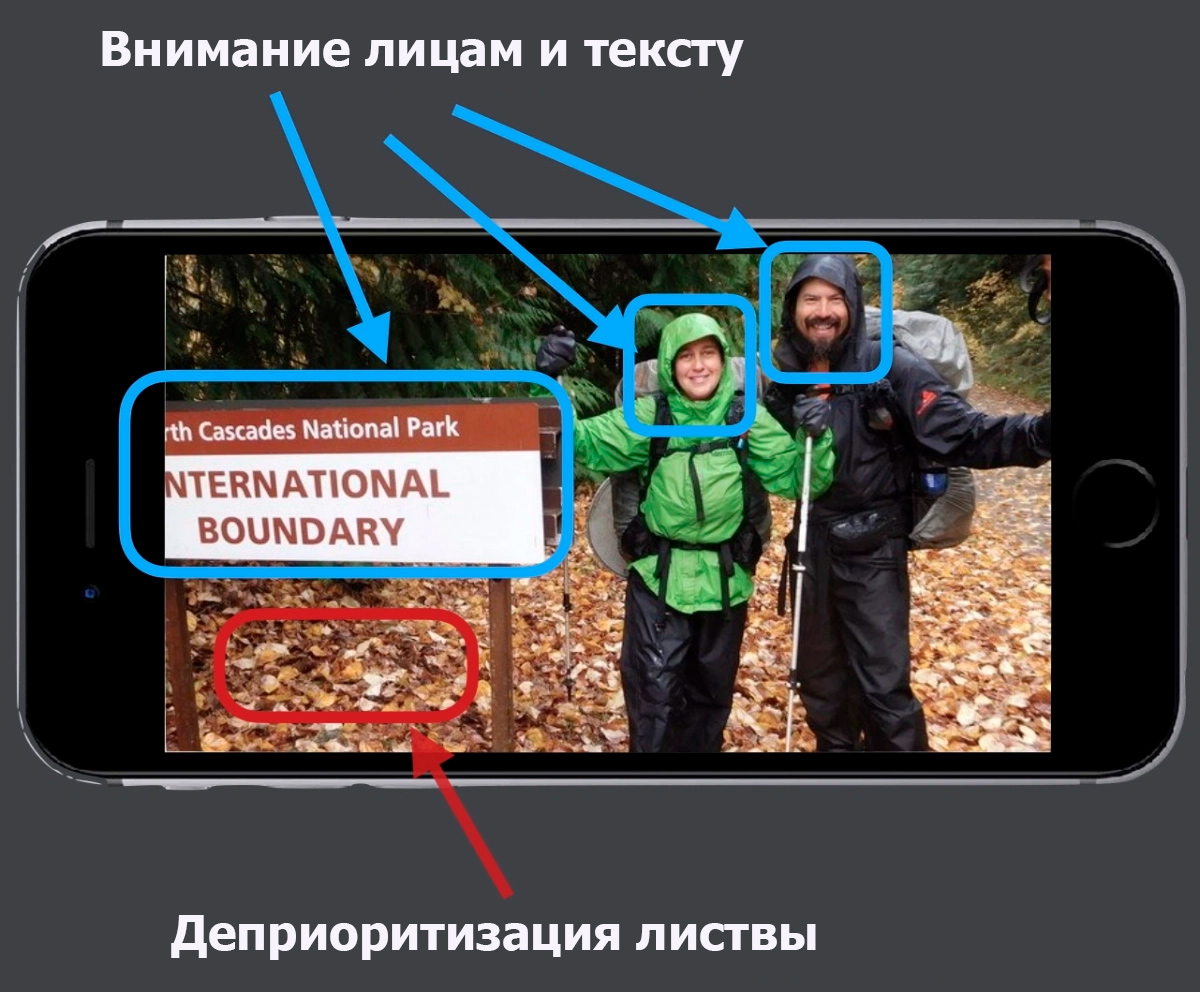
В мае 2015 года Google выпустила отдельное приложение «Фотографии». Люди были поражены тем, что оно способно анализировать изображения, разбирать их на детали, а потом маркировать людей, места и вещи. Даже переводить текст!
Была только одна проблема. Google внедрил «категоризацию фотографий» — все фотографии автоматически размечались и организовывались в папках на основании того, что на них было. И через пару месяцев 22-летний программист-фрилансер Джеки Альсине обнаружил, что все фотографии, на которых был изображен он и его девушка, оба чернокожие, были помечены как «гориллы». Причем если на фотографиях был виден белый человек или человек со светлой кожей, Google маркировал их правильно — например, «выпускной» или «поход в бар». М-да.
История сразу разгорелась в Твиттере. После шквала негатива Google поклялась больше не позволять своему приложению классифицировать каких-либо людей как «горилл» и пообещала решить эту проблему. Восемь лет спустя — эта история, оказывается, всё еще не затухла, и влияет на развитие современных ИИ больше, чем можно было бы ожидать.

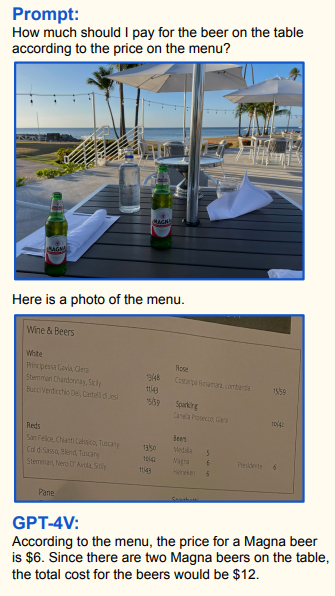
С помощью GPT-4 можно решать самые разнообразные задачи по преобразованию текста, включая перевод на разные языки.
Мне стало интересно, кто переводит лучше: GPT-4 или специализированные нейронки для перевода, такие как Google Translate и DeepL?
Сегодня мы сравним качество перевода от различных нейросетей на 24 языковых парах.

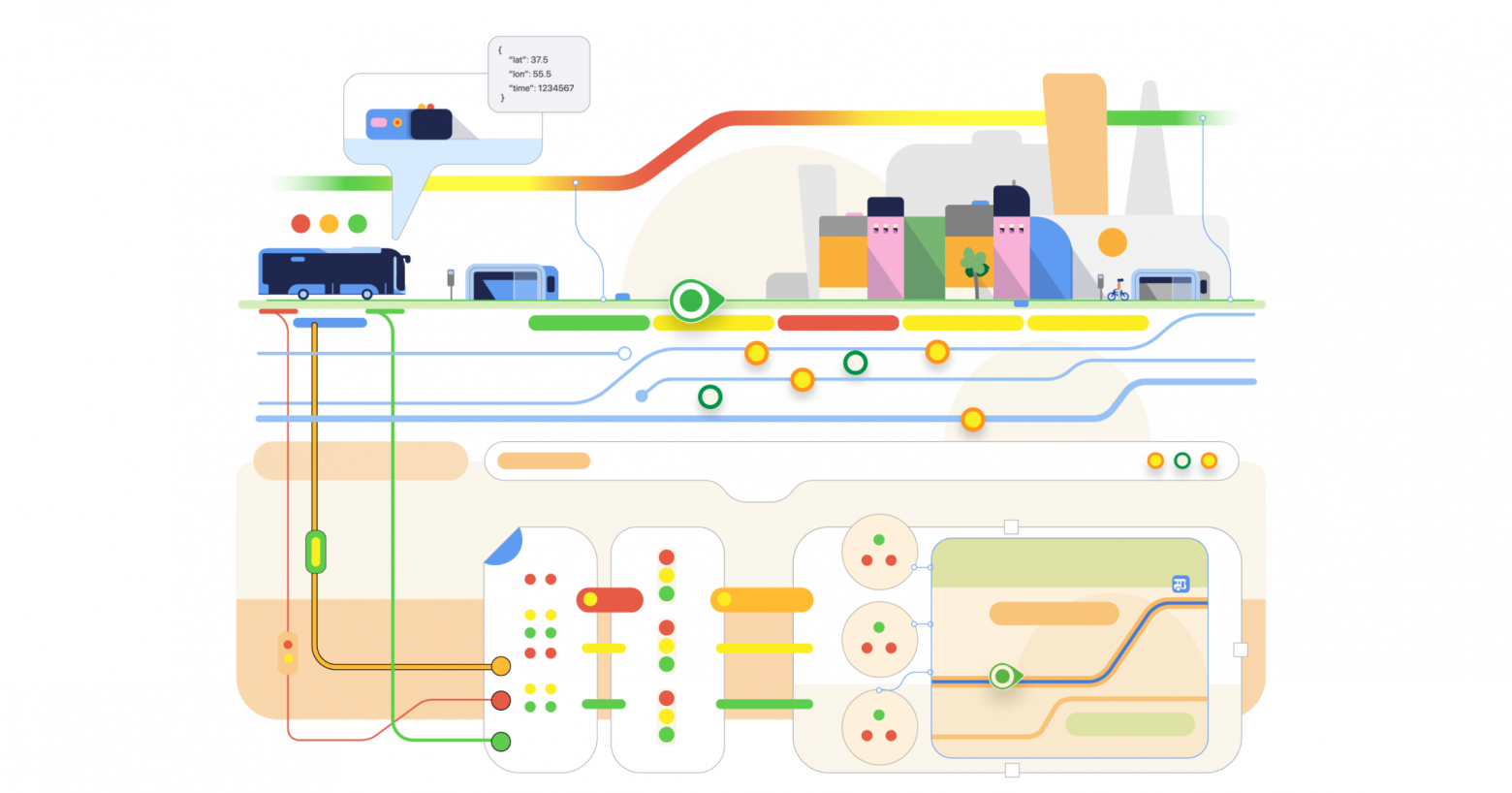
Раздел «Транспорт» — один из самых популярных в Яндекс Картах: там автобусы, троллейбусы и трамваи перемещаются прямо по карте в реальном времени, а для каждой остановки есть виртуальное табло. Можно посмотреть, сколько ещё ждать транспорт, или понять, когда лучше выходить из дома, чтобы его не пропустить. А если оказались в незнакомом районе — узнать, как быстрее добраться домой, и сразу найти ближайшую остановку или станцию метро.
Меня зовут Антон Овчинкин, я руководитель группы разработки пешеходной и транспортной навигации. Сегодня я расскажу, что у «Транспорта» под капотом, какие алгоритмы отвечают за то, чтобы автобусы появлялись на карте, двигались по ней плавно и реалистично, а прогноз был максимально точным.