Двое на самокате, не считая кучи разных датчиков: как мы учились определять поездки вдвоем

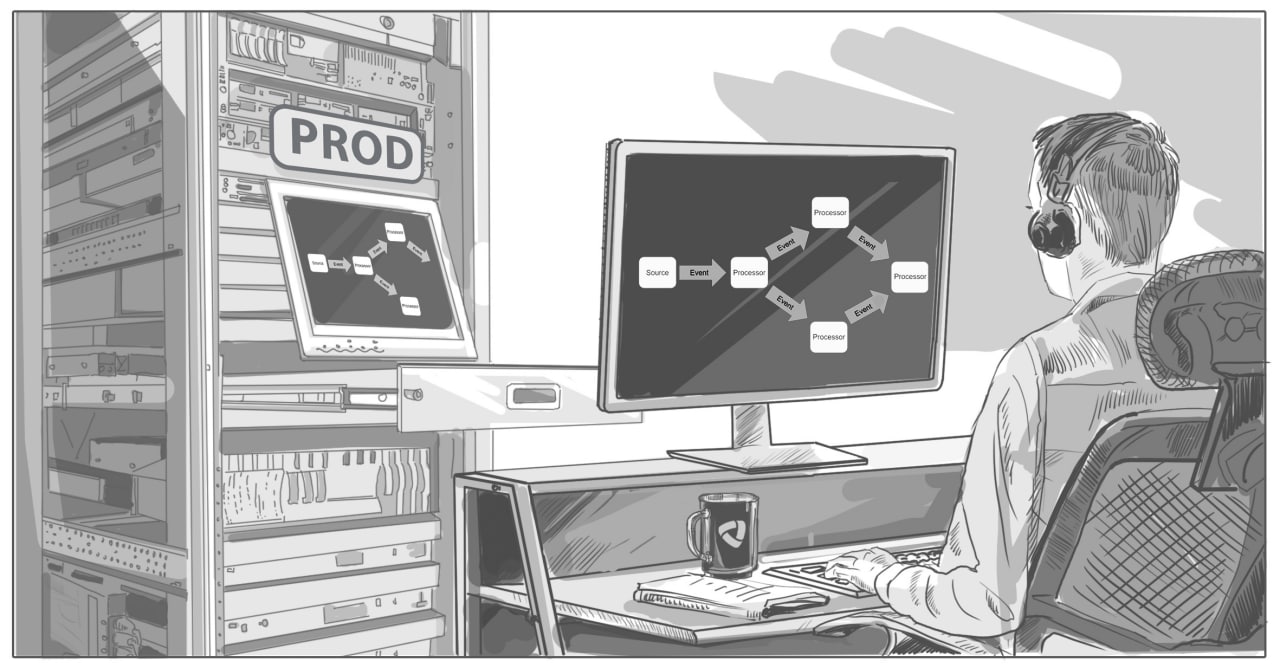
Всем привет, на связи Фарук, инженер-разработчик электроники и встроенного ПО в Whoosh (читается как ВУШ, ощущается как вжууух). Работаю я в embedded отделе (хардкорные программисты, что пишут прошивку на C для различных железок и проектируют эти самые железки), но в основном занимаюсь анализом различных данных от нашего IoT модуля и разработкой алгоритмов для работы с этими данными.
Наша компания — сервис аренды электросамокатов (а местами еще и электровелосипедов) или, иными словами, кикшеринг. О том, как мы к этому пришли и что из себя представляем можно почитать здесь.
Одно из отличий использования шерингового самоката от личного — наличие определенных правил. Например, вы видели когда-нибудь парочку влюбленных, вдвоем на самокате, исчезающих в закате? Или может наблюдали троих парней, которые в обнимку, преодолев смущенье, едут навстречу новым приключеньям? А может быть вы видели как чей-то отец, словно швец, жнец и на самокате ездец, с одним ребенком подмышкой а с другим на шее смело едет по парковой аллее?
Вызывают ли у вас эти картины гнев и праведное негодование? А может быть вы и сами не прочь прокатиться с другом/подругой на одном самокате? У нас для вас есть две новости.
Во-первых, так нельзя. А во-вторых, добро пожаловать под кат.