

Привет! Меня зовут Дмитрий Руденко, я из команды Databases Т-Банка. В последние годы наблюдается тенденция к переходу на Postgres со стороны многих команд и компаний, что приводит к увеличению количества Postgres-баз данных, требующих эффективного мониторинга и управления.
Мы достигли впечатляющего масштаба — почти 10 000 работающих экземпляров PostgreSQL, с которыми работают более 2 000 команд. Каждый из этих инстансов обслуживает уникальные рабочие нагрузки, разработанные командами с различными подходами к архитектуре, используемыми фреймворками и паттернами проектирования.
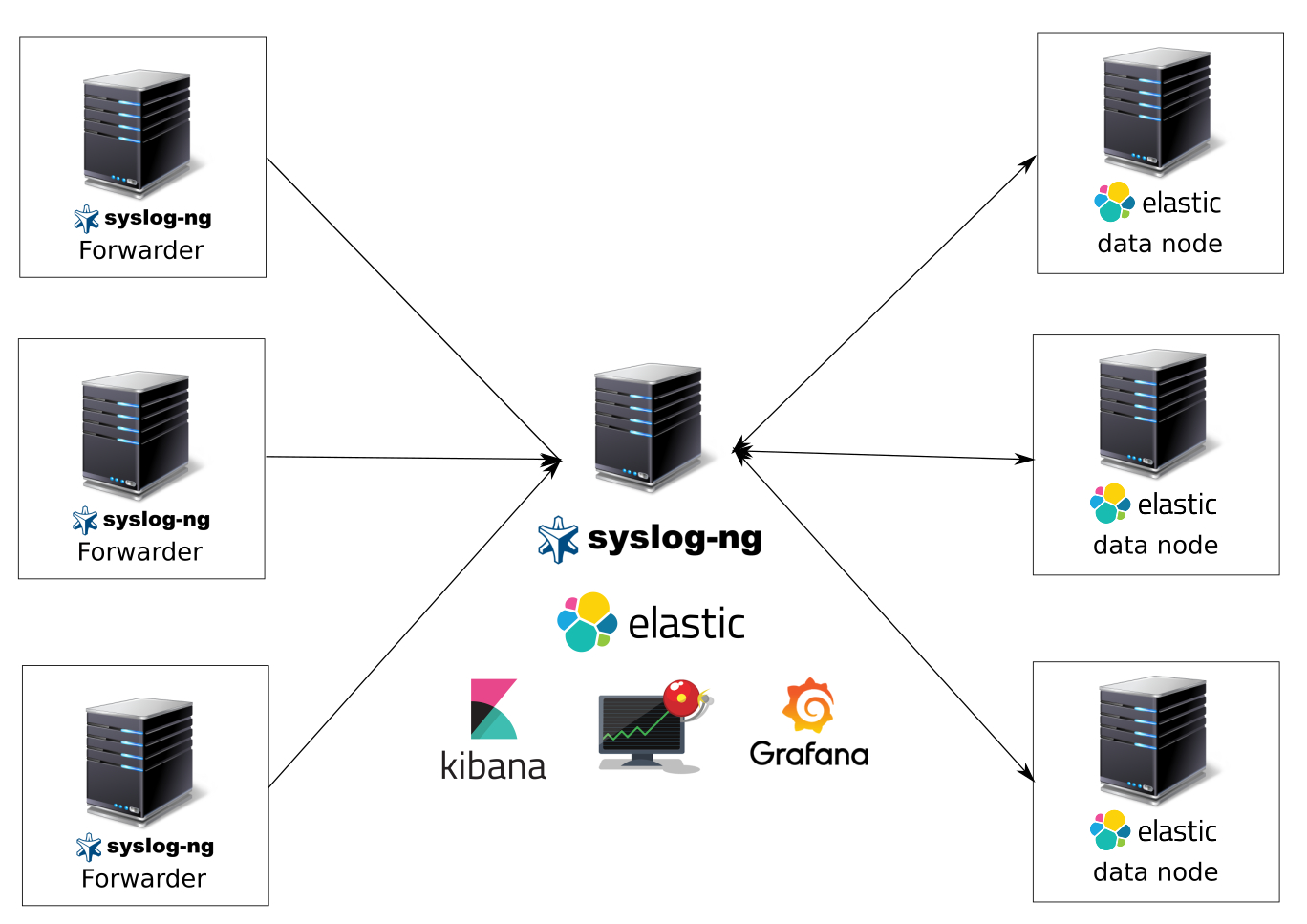
Мы пришли к созданию общей системы мониторинга баз данных Postgres, предоставляющей пользователю в простом и понятном виде данные о состоянии инстанса. В этой статье я расскажу о нашем видении визуального представления информации для пользователя и о созданной нами группе дашбордов для наблюдения за базами данными Postgres. Вы увидите, что накопительная статистика Postgres совместно с Prometheus и Grafana способны творить чудеса.





 » работает под капотом.
» работает под капотом.  , а также отобразить «GHz» как один глиф:
, а также отобразить «GHz» как один глиф:  .
. или семиглазый монстр:
или семиглазый монстр:  . И утка:
. И утка:




 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
