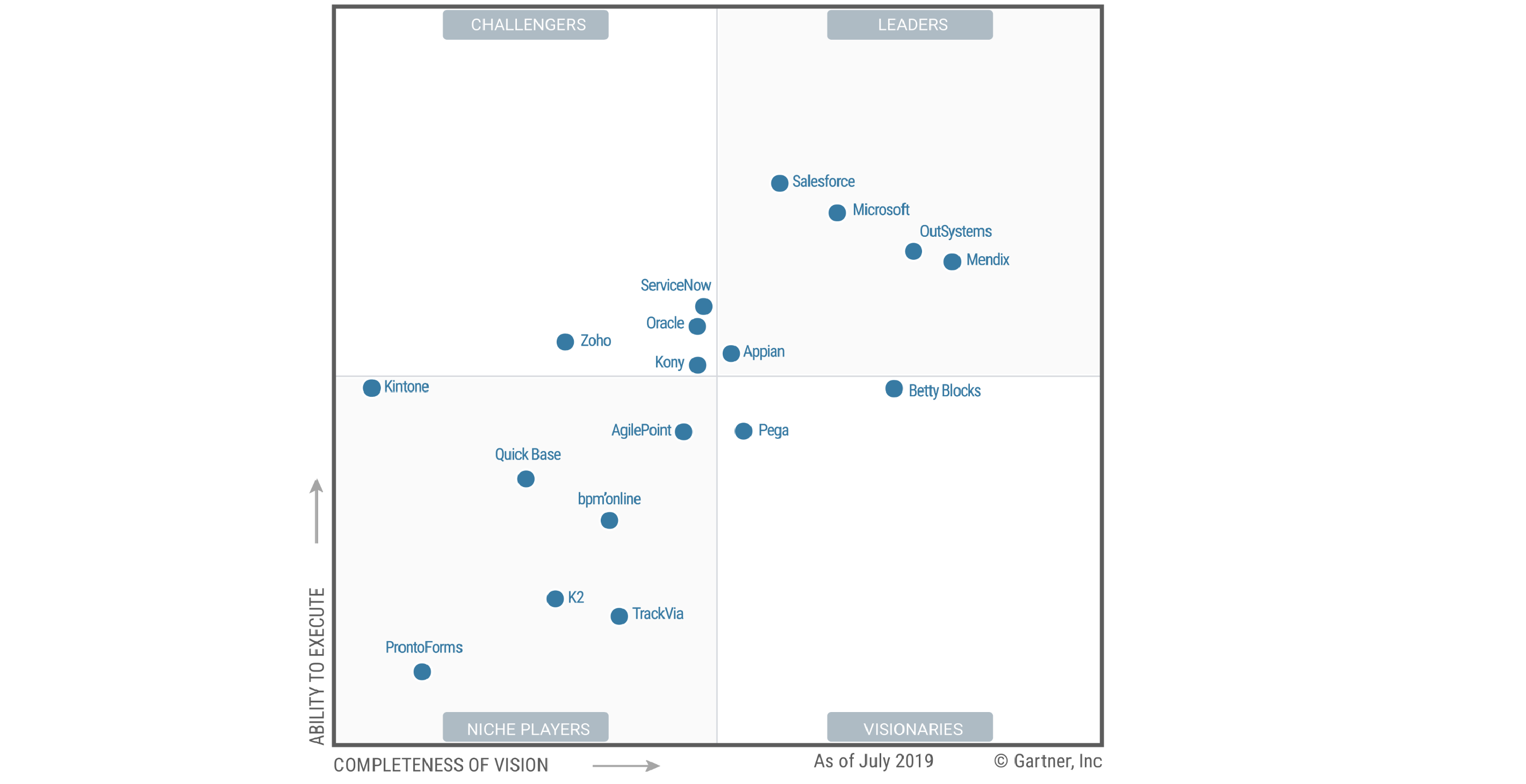
Все мы в последнее время довольно много слышим о платформах low-code/no-code. Платформы без кода обещают сделать разработку программного обеспечения столь же простой, как использование Word’а или PowerPoint’а, чтобы обычный бизнес-пользователь смог продвигать проекты без дополнительных затрат (денег и времени) на команду инженеров. В отличие от платформ без кода, low-code по-прежнему требует определенных навыков программирования, однако обещает ускорить разработку программного обеспечения, позволяя разработчикам работать с предварительно написанными компонентами кода.