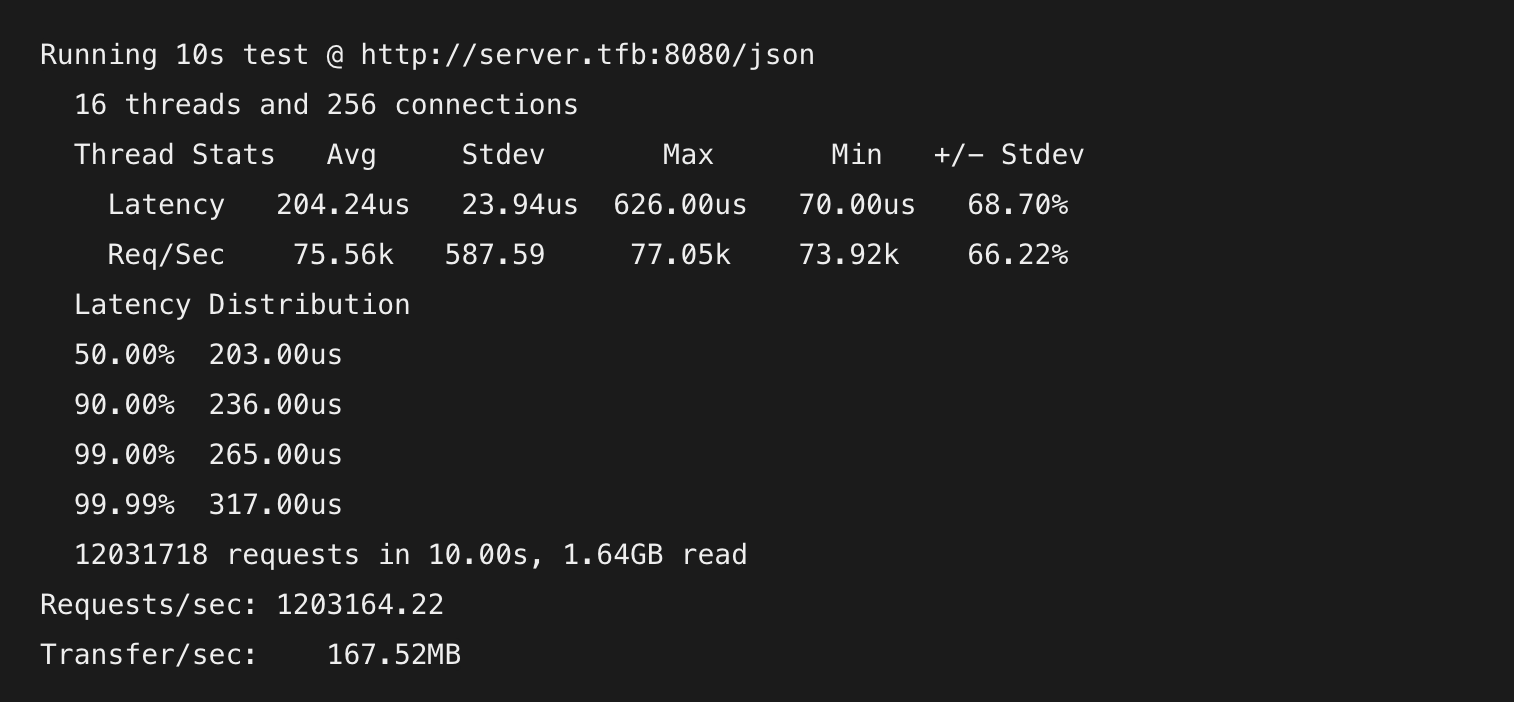
На протяжении сотен лет, начиная со времен Ньютона и Лагранжа, ученые предлагали множество ответов на вопрос о точной скорости гравитации. Два основных предположения, вокруг которых крутились дебаты, состояли в том, что гравитация или бесконечно быстра и пронизывает всё пространство, или распространяется со скоростью света.
Например, Лаплас в 1805 году, используя формулы Ньютона, посчитал, что скорость гравитации должна быть минимум в 7·106 раз выше скорости света — иначе орбиты планет не совпадали бы с тем, что мы видим на небе. Расчеты Лапласа используются до сих пор, и были одним из аргументов противников теории относительности Эйнштейна, предложенной на сотню лет позже.
Дебаты продолжались ещё долгое время, регулярно находились новые аргументы, подтверждающие ту или иную сторону (например, работы Лоренца об инвариантности статических полей, показавшие, что именно в своих расчетах не учел Лаплас). Но окончательный ответ на вопрос о скорости гравитации был найден только 5 лет назад.