
It is an efficient searching technique. Searching is a widespread operation on any data structure. Hashing is used to search specific records from a large domain of records. If we can efficiently search a record out of many records, we easily perform different operations on that data. Hashing is storing and retrieving data from the database in the order of O(1) time. We can also call it the mapping technique because we try to map smaller values into larger values by using hashing.
Following are the significant terminologies related to hashing
Search Key
In the database, we usually perform searching with the help of some keys. These keys are called search keys. If we take the student data, then we search by some registration number. This registration number is a search key. We have to put the search keys in hash tables.
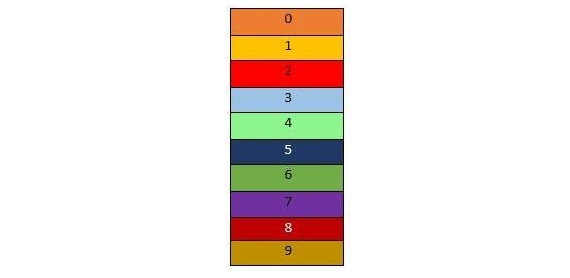
Hash Table
It is a data structure that provides us the methodology to store data properly. A hash table is shown below. It is similar to an array. And we have indexes in it also like an array.







 Эдвард Мэтью Ворд.
Эдвард Мэтью Ворд. 
{kind=link}