Всем привет! Не так давно, после очень плотного изучения аллокаторов и алгоритмов распределения памяти, а также в последующем применении их на практике мне в голову пришла идея написать статью, в которой будет максимально подробно рассказано о них. Считаю, что данная тема будет достаточно востребованной, так как в сети, особенно в русскоязычной части, на данный момент существует очень мало источников, посвященных этому вопросу.

Пользователь
Создаём сетевую карту на дискретной логике
6 мин
Туториал
Перевод
Этот пост — продолжение моего проекта по созданию завершённой компьютерной системы на компонентах дискретной логики. У меня уже есть компьютер, способный выполнять сетевые приложения, например, HTTP-сервер или игру по LAN.
В прошлом году я изготовил адаптер физического уровня, преобразующий сигнал Ethernet 10BASE-T в SPI и обратно. Тогда для тестирования его работы я использовал микроконтроллер STM32, а теперь реализую модуль слоя MAC, чтобы подключить его к своему самодельному компьютеру.
Оба адаптера полнодуплексные и имеют отдельные передатчик и приёмник.

Компьютер целиком. Новый модуль находится справа внизу
В прошлом году я изготовил адаптер физического уровня, преобразующий сигнал Ethernet 10BASE-T в SPI и обратно. Тогда для тестирования его работы я использовал микроконтроллер STM32, а теперь реализую модуль слоя MAC, чтобы подключить его к своему самодельному компьютеру.
Оба адаптера полнодуплексные и имеют отдельные передатчик и приёмник.
Компьютер целиком. Новый модуль находится справа внизу
Как в Google выполняют ревью кода
Простой
6 мин
Обзор
Перевод

Critique и Gerrit
У Google есть два собственных инструмента для ревью кода: Critique, используемый большинством инженеров, и Gerrit, — опенсорсный, который продолжают применять в публичных проектах.
(Вы можете сами поэкспериментировать с Gerrit в опенсорсных репозиториях Chromium и Android.)
Дэшборды
Когда инженеры логинятся с утра или когда устраивают перерыв для ревью пул-реквестов, внутри Google называемых change list, или CL, и в Critique, и в Gerrit они работают с дэшбордами, в которых можно легко вкратце просмотреть все актуальные изменения (это похоже на окно пул-реквестов репозитория GitHub, только более сложное и информационно насыщенное).
В дэшборде Gerrit есть единичный поиск, извлекающий такую информацию, как размер изменения и более подробные сведения о статусе CL (три столбца справа).
Специалисты по информатике изобрели новый эффективный способ подсчёта уникальных элементов
4 мин
Перевод

Представьте, что вас отправили в девственный тропический лес, чтобы провести перепись диких животных. Каждый раз, когда вы видите животное, вы делаете снимок. Ваша цифровая камера будет фиксировать общее количество снимков, но вас интересует только количество уникальных животных — всех тех, которых вы ещё не посчитали. Как лучше всего получить это число? «Очевидное решение — запомнить всех животных, которых вы уже видели, и сравнивать каждое новое животное с этим списком», — говорит Лэнс Фортноу, специалист по информатике из Иллинойского технологического института. Но есть и более умные способы, добавил он, потому что если у вас тысячи записей, то очевидный подход далеко не так прост.
Всё становится ещё хуже. Что, если вы — Facebook, и вам нужно подсчитать количество отдельных пользователей, которые заходят на сайт каждый день, даже если некоторые из них заходят с нескольких устройств и в разное время? Теперь мы сравниваем каждый новый вход со списком, который может исчисляться миллиардами.
Возможно, микросервисы вам не нужны
Простой
7 мин
Мнение
Перевод

Писать эту статью было весело. Многие наверняка её захейтят, но …
Дорогие коллеги-разработчики, нам нужно поговорить. Поговорить о микросервисах и ряде нежелательных ситуаций. Да, будет непросто, но это необходимо. Иначе нам не справиться.
Сегодня микросервисы очень популярны. Это прекрасный архитектурный стиль, который помогает масштабировать систему и саму организацию. Их используют многие успешные компании (Netflix, Spotify и прочие). Поэтому вполне нормально, что большинство организаций уже применяют или планируют начать применять этот стиль. Однако не все учитывают сопутствующие затраты.
Хитрый Алгоритм: Решение задачи Continuous Subarray Sum
Простой
2 мин

За последние две недели я занимался различными задачами на Leetcode. И сегодня я наткнулся на интересную задачу: Сумма последовательного подмассива - решением которой хотел бы с вами поделиться.
Почему MVx архитектуры всегда получаются плохо
7 мин
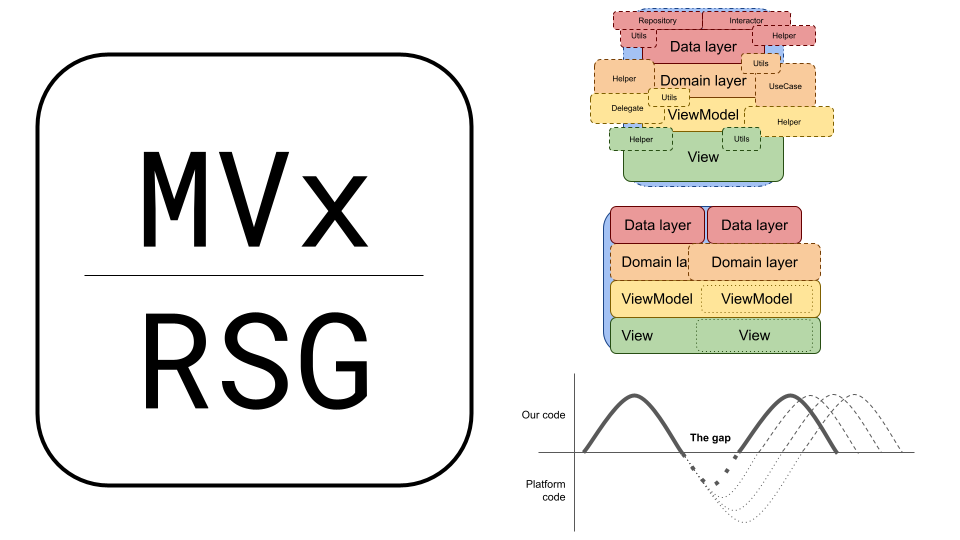
Привет, меня зовут Владимир и у меня есть кое-что что надо обсудить, но сначала позвольте мне быстро рассказать как все это началось.
Я познакомился с понятием “архитектурные паттерны” и MVC в частности еще в 2012, и с тех пор заболел идеей архитектур программного обеспечения. Я восхищался людьми, которые пишут архитектурные фреймворки. Я тратил дни и недели читая их исходники и просматривая видео на YouTube. Но чем больше я в это погружался, тем больше я чувствовал себя в состоянии, которое я называю “начинающий иллюзионист”: пока смотришь на фокусы - это магия, но когда начинаешь их делать, то они становятся банальными.
За годы я попробовал разные существующие паттерны и фреймворки, на разных языках и в разных проектах. Какие-то реализации я писал с нуля, с какими-то знакомился в чужих проектах, но почти каждый раз упирался в их несовершенство. И каждый раз это было очень болезненно. И вот я думал, что в следующий раз все сделаю правильно, но опять что-то шло не так. Тогда я решил разобраться в этом вопросе и сделал своей миссией поиск того самого подхода, который имеют ввиду, когда говорят “нормально делай - нормально будет”.
Нашел ли я его? Возможно. По крайней мере мне есть что показать, но об этом в другой раз.
В своих скитаниях я нашел кое-что не менее интересное: причину почему MVx всегда получается плохо. И вот об этом и пойдет речь сегодня.
Сравнение алгоритмов ограничения частоты запросов
Средний
7 мин
Обзор
Перевод

▍ Зачем ограничивать частоту?
Представьте чат в Twitch со множеством активных пользователей и одним спамером. Без ограничения частоты сообщений единственный спамер может запросто заполнить всю беседу сообщениями. При ограничении частоты у каждого пользователя появляется равная возможность участия.
Видео
Ограничитель частоты позволяет управлять частотой обрабатываемого вашим сервисом трафика, блокируя запросы, превосходящие заданное пороговое значение за период времени. И это полезно не только для борьбы со спамом в чатах. Например, ограничение частоты отправки формы логина позволяет защититься от брутфорс-атак, оставляя при этом пользователю право на ошибку.
Конечные точки API тоже часто ограничивают по частоте запросов, чтобы их ресурсы не монополизировал единственный пользователь. Представьте, что вам нужно, чтобы пользователи могли обращаться к затратной конечной точке не чаще ста раз в минуту. Это можно отслеживать при помощи счётчика, обнуляющегося каждую минуту. Все запросы после сотого в пределах этой минуты будут блокироваться. Это один из простейших алгоритмов ограничения частоты, называющийся fixed window limiter (ограничитель с фиксированным окном). Это распространённый способ управления трафиком к сервису.
Но не всегда всё так просто.
Когда начинается и заканчивается каждое одноминутное окно? Если я запущу поток запросов ближе к концу окна, смогу ли превысить лимит? Ёмкость окна восстанавливается по одному запросу за раз, или сразу на всё количество?
В этом посте мы рассмотрим три самых популярных алгоритма, чтобы ответить на каждый из этих вопросов.
Как потреблять API с ограничением по RPS в .NET приложениях
Простой
11 мин
Туториал

Однажды каждый C# программист получает на работе задачу по разработке интеграции с внешней системой, где ограничена максимальная частота запросов в секунду.
Интернет яростно сопротивлялся предоставить мне инструкцию к написанию такого кода, закидывая туториалами по настройке ограничения RPS на сервере, а не клиенте.
Но теперь на Хабре есть эта статья, которая научит отправлять запросы из
HttpClient так, чтобы не получать 429 Too Many Requests.Как Яндекс создал свою шину данных, чтобы передавать сотни гигабайт в секунду
Простой
7 мин
Роадмэп

10 лет назад сотни серверов Яндекса работали на Apache Kafka®, но в этом продукте нам нравилось далеко не всё. Наши задачи требовали единой шины для передачи всех видов данных: от биллинговых до журналов приложений. Сегодня объёмы достигли уже десятков тысяч именованных наборов сообщений.
При таком количестве данных в Apache Kafka® становилось сложно управлять правами доступа, организовывать распределённую работу нескольких команд и многое другое. Проблемы роста и отсутствие подходящего решения в открытом доступе привели к тому, что мы разработали своё решение YDB Topics и выложили его в опенсорс в составе платформы данных YDB. В этом посте расскажу о предпосылках создания продукта, нашей архитектуре передачи данных, возникающих задачах и возможностях, которые появились вместе с YDB Topics.
LLM как универсальная «отмычка» студента — настолько ли все хорошо?
Средний
7 мин
Кейс

Небольшой эксперимент по применению LLM при решении задач анализа данных на R и краткие выводы по нему.
Логистическая и Softmax-регрессии. Основная идея и реализация с нуля на Python
Сложный
9 мин
Туториал

Начнём с более простого. Логистическая регрессия — линейный бинарный классификатор, основанный на применении сигмоидальной функции к линейной комбинации признаков, результатом которого является вероятность принадлежности к определённому классу. Обычно порог устанавливается 0.5: если вероятность меньше порога — класс относится к 0, а если больше — к 1. В принципе, условия определения логистической регрессии такие же как и у линейной за исключением бинаризации таргета.
Актуально ли сегодня ООП?
Средний
11 мин
Мнение
Перевод

Почти каждый день возникают дискуссии с критикой или восхвалением объектно-ориентированного программирования. «Java устарела!», «Java потрясающая!». В этой статье я проведу прагматичное исследование ООП на 2024 год.
Термин объектно-ориентированное программирование придумал Алан Кэй. Кэй был членом команды PARC, которая изобрела графический интерфейс пользователя, сделавший таким полезным современный Интернет, персональные компьютеры, планшеты и смартфоны. Ещё она изобрела некоторые из объектно-ориентированных языков, на которых мы сегодня реализуем эти GUI.
Если отсечь все эмоции, связанные с ООП, то что останется? По-прежнему ли ООП является эффективным инструментом разработки ПО, или оно превратилось в устаревшее увлечение? Профессионалам важно знать ответ на этот вопрос!
Как я уронил прод на полтора часа (и при чем тут soft delete и partial index)
7 мин

В жизни любого разработчика наступает момент, когда он роняет прод. Представьте: полдень, в Skyeng час пик, тысячи запланированных онлайн-уроков, а наша платформа лежит…
Все упало из-за ошибки в процессе деплоя, которая связана с тонкостью PostgreSQL. К сожалению, на этом моменте у нас прокололась не одна команда. И чтобы такое больше не произошло ни у нас, ни в другой компании — велкам под кат.
Вы за это заплатите! Цена Чистой Архитектуры. Часть 1
Средний
11 мин

Всем привет, меня зовут Артемий, я работаю старшим Android-разработчиком в команде пользовательского профиля в RuStore. Мой опыт в индустрии уже 8 лет. За это время я успел поработать в разных проектах и компаниях. У меня был опыт работы в проекте, в котором было свыше 300 модулей и больше 60 Android-разработчиков. Такие условия заставляют задуматься о масштабируемости на принципиально ином уровне.
Сегодня я расскажу о способах обеспечения масштабируемости проекта и как этому может навредить неправильное восприятие Чистой Архитектуры (далее — ЧА). Предупреждаю сразу, это лонгрид в двух частях!
Задача двумерной упаковки интервалов
13 мин
Перевод

Упаковка интервалов — это классическая задача SQL, которая подразумевает переупаковку групп пересекающихся интервалов в соответствующие им непрерывные интервалы. В математике интервал — это подмножество всех значений данного типа, например целых чисел, между двумя некоторым разными значениями. В базах данных интервалы могут проявляться в виде интервалов даты и времени, представляющие такие вещи, как сеансы, периоды назначения, периоды госпитализации, расписания или числовых интервалов, представляющие такие вещи, как диапазоны мильных столбов на дороге, диапазоны температур и т.д.
Лучшие практики для надёжной работы с RabbitMQ
Простой
13 мин
Туториал

Привет, Хабр! Я Женя, архитектор интеграционной платформы в Точке, отвечаю за асинхронный обмен сообщениями между внутренними сервисами, за ESB и за брокеры сообщений.
В этой статье я постарался кратко и последовательно изложить основные моменты, о которых полезно помнить при использовании RabbitMQ, если важны стабильность обмена и сохранность данных.
В первую очередь материал рассчитан на разработчиков, которым ещё не приходилось погружаться в тонкости работы с RabbitMQ или использовать его вообще. Более опытным читателям статья может пригодиться в качестве компактной и упорядоченной выжимки из уже знакомых статей, вебинаров и многочисленных страниц документации.
Основные типы распределений вероятностей в примерах
Средний
15 мин
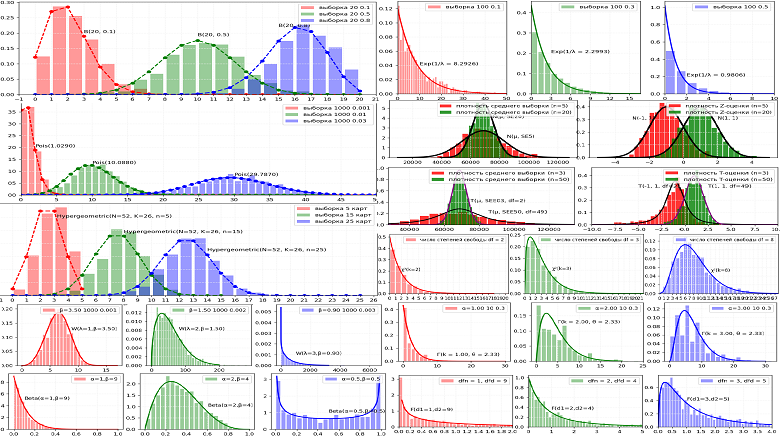
Статистические исследования и эксперименты являются краеугольным камнем развития любой компании. Особенно это касается интернет-проектов, где учёт количества пользователей в день, времени нахождения на сайте, нажатий на целевые кнопки, покупок товаров является обычным и необходимым явлением. Любые изменения в пользовательском опыте на сайте компании (внешний вид, структура, контент) приводят к изменениям в работе пользователя и, как результат, изменения наблюдаются в собираемых данных. Важным элементом анализа изменений данных и его фундаментом является использование основных типов распределений случайных величин, от понимания которых напрямую зависит качество оценки значимости наблюдаемого изменения. Рассмотрим их подробнее на наглядных примерах.
Блеск и нищета паттерна «Спецификация» в С#. Оцениваем планы запросов
Сложный
23 мин

О паттерне «Спецификация», который позволяет улучшить структуру приложения, и, следовательно, увеличить гибкость, уменьшив при этом объем кода, а значит — сократить количество ошибок, но это не точно. Почему? - читаем ниже.
Правило трех и пяти в C++: что это такое и зачем они нужны?
Простой
5 мин
Обзор

Привет, Хабр!
Сегодня я хочу поговорить о двух правилах С++: правиле трех и правиле пяти.
Правильное понимание этих правил способно уберечь код от утечек и неопределенных поведений.