
Рассмотрим то как можно в одиночку быстро создать сервер и UI для ML приложения на Python с перспективой вывода в prod. Исследуем PyTriton и немного Gradio.

Пользователь
Рассмотрим то как можно в одиночку быстро создать сервер и UI для ML приложения на Python с перспективой вывода в prod. Исследуем PyTriton и немного Gradio.
 В ходе тестирования некоторых продуктов компании Positive Technologies возникла необходимость проведения быстрых стресс-тестов одного веб-сервиса. Эти тесты должны были быть простыми и быстрыми в разработке, нетребовательными к аппаратным ресурсам и одновременно с этим давать значительную нагрузку однотипными HTTP-запросами, а также предоставлять статистические данные для анализа системы под нагрузкой.
В ходе тестирования некоторых продуктов компании Positive Technologies возникла необходимость проведения быстрых стресс-тестов одного веб-сервиса. Эти тесты должны были быть простыми и быстрыми в разработке, нетребовательными к аппаратным ресурсам и одновременно с этим давать значительную нагрузку однотипными HTTP-запросами, а также предоставлять статистические данные для анализа системы под нагрузкой.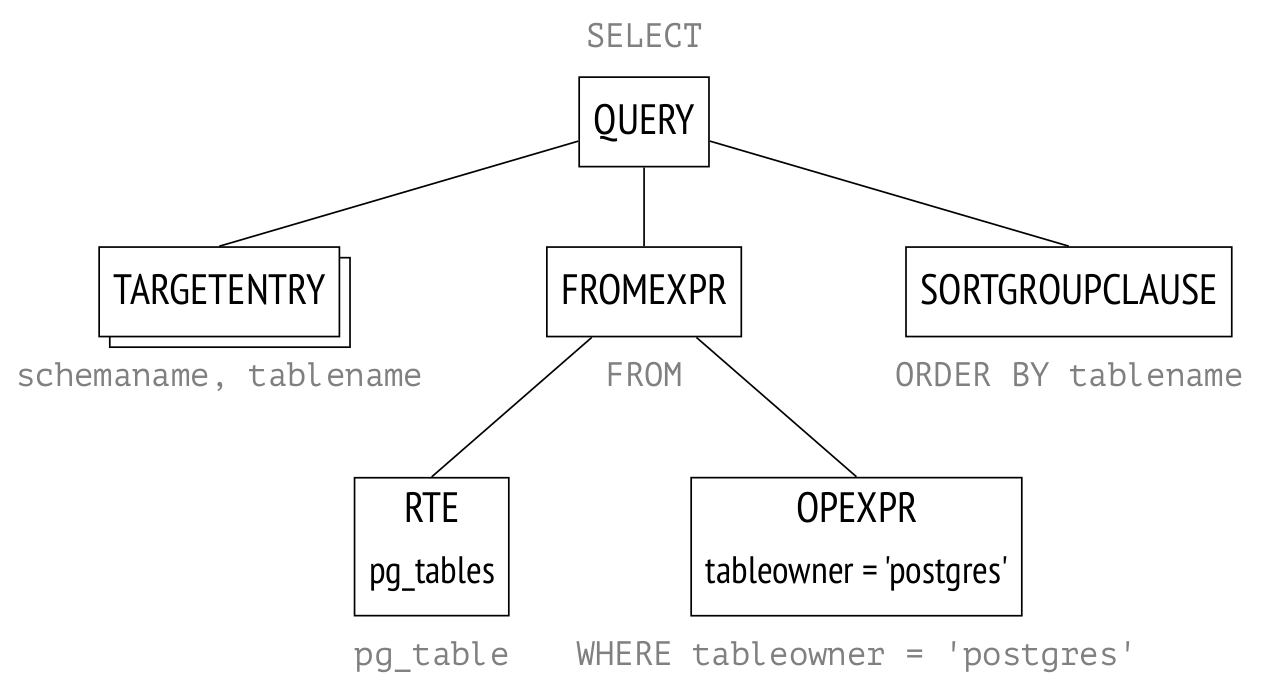
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
Предыдущие циклы были посвящены изоляции и многоверсионности, журналированию и блокировкам.
В этом цикле я собираюсь рассмотреть этапы выполнения запросов, статистику, последовательное сканирование, индексное сканирование, соединение вложенным циклом, соединение хешированием, сортировку и соединение слиянием.
Материал перекликается с нашим учебным курсом QPT «Оптимизация запросов», но ограничивается только подробностями внутреннего устройства и не затрагивает оптимизацию как таковую. Кроме того, я ориентируюсь на еще не вышедшую версию PostgreSQL 14. А курс мы тоже скоро обновим (правда, на версию 13; приходится бежать со всех ног, чтобы только оставаться на месте).
Рано или поздно аналитик сталкивается с проблемой организации данных. Их становится все больше, структура перестает быть прозрачной, а одни и те же SQL-запросы приходится переписывать по несколько раз. Решить эту проблему можно с помощью dbt – инструмента, который открывает новый подход к трансформации и моделированию данных. Под катом – перевод отличной статьи Дэвида Кревитта о том, что такое dbt, и как этот инструмент помогает аналитикам облегчить свою работу.

В последнее время в области компьютерного зрения произошло много революционных событий, но есть ряд классических задач, решение которых остается актуальным. Одна из них — матирование, которое применяется для редактирования изображений и видео через извлечение нужных объектов с субпиксельной точностью. Решения этой задачи вы можете видеть в программах для кинопроизводства и фоторедакторах. В этой статье мы хотим познакомить вас с нашим новым подходом к матированию изображений. Изначально мы в SberDevices стремились решить задачу для портретов, но обобщающая способность модели позволяет использовать её и для изображений, выполненных в полный рост, для картинок с животными и так далее.

Автор: Дмитрий Косаревский
Привет, Хабр! 👋
Меня зовут Дима Косаревский, я инженер данных (DE), увлеченный Data Science и всем, что связано с этим направлением.
Data Science позволяет извлекать ценную информацию из огромных объемов данных при помощи статистических и вычислительных методов.
В последнее время эти ИИ, вроде ChatGPT, врываются прямо во все сферы. И вот благодаря увлечению Data Science можно использовать этих ботов, чтобы помогать людям, да ещё и пообщаться с ними на разные темы. Здорово, правда?
ChatGPT действительно впечатляет. Он не только общается на разные темы, но еще и стихи сочинять умеет.
Вот один из примеров, которые я получил недавно:
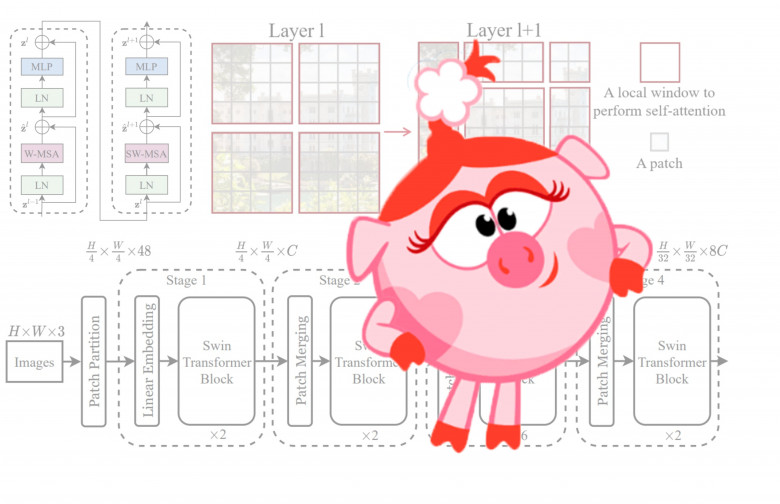
Трансформеры шагают по планете! В статье вспомним/узнаем как работает visual attention, поймём что с ним не так, а главное как его поправить, чтобы получить на выходе best paper ICCV21.
Когда возникла необходимость понять, что из себя представляет триангуляции (не визуализация поверхности, а реконструкция), к моему удивление найти удалось не так много материалов. После изучения темы было решено собрать все, что мне удалось накопать, в одну статью, в надежде, что кому-то это может пригодится и поможет в будущем.

Не так давно перед нами стояла задача найти и извлечь печати с документов. Зачем? Например, для проверки наличия печатей в договорах с двух сторон (участников договора). У нас в закромах уже был прототип для их поиска, написанный на OpenCV, но он был сыроват. Решили откопать данный реликт, стряхнуть с него пыль и на его основе сделать рабочее решение.
Большинство приемов, описанных здесь, можно применить и вне задачи поиска печатей. Например:
В итоге, у нас было два варианта: решать с помощью нейронных сетей или же воскресить прототип на OpenCV. Почему мы решили взять OpenCV? Ответ в конце статьи.
Обзор построения и анализа парной линейной регрессионной модели с использованием библиотеки statsmodels

Кривая эластичности спроса по цене – это то, как продажи зависят от цены.Чем меньше цена, тем больше продаж и наоборот.
В этой статье рассказывается про ML методы получения кривых спроса сразу для сотен тысяч товаров (нейросети, pyTorch), а также как, имея кривые спроса, решать бизнес задачу про баланс оборота и прибыли – в этом нам поможет метод множителей Лагранжа. Что первично – ограничение на прибыль или множитель Лагранжа? Как инженерам объяснить, что такое kvi-товары и товары-герои? Это и многое другое
 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
 Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.
Это реальная история. События, о которых рассказывается в посте, произошли в одной теплой стране в 21ом веке. На всякий случай имена персонажей были изменены. Из уважения к профессии всё рассказано так, как было на самом деле.
Привет, Хабр. В этом посте речь пойдет про пресловутое А/Б тестирование, к сожалению даже в 21ом веке его не избежать. В онлайне уже давно существуют и процветают альтернативные варианты тестирования, в то время, как в офлайне приходится адаптироваться по ситуации. Об одной такой адаптации в массовом офлайн ритейле мы и поговорим, приправив историю опытом взаимодействия с одной топовой консалтинговой конторой, в общем го под кат.

Всем привет! Меня зовут Гриша Стерлинг, я занимаюсь синтезом речи в SberDevices. Недавно прошла конференция AI Journey, где я рассказал, как сделал синтез своего голоса. За 15 минут выступления я не успел рассказать все, поэтому решил написать большой пост с деталями. Он будет интересен датасаентистам, людям из бизнеса и ai‑энтузиастам. Приглашаю всех под кат.

Вокруг так много фреймворков для инференса нейронных сетей, что сложно понять, какой именно подойдет тебе лучше всего. Я решил, что реализую одну и ту же задачу на нескольких разных технологиях. Так и родился этот туториал по Nvidia Triton Inference Server.

О математических нюансах АБ-тестирования есть много замечательной литературы, но почти нигде нет информации о том, каким образом в компаниях выстраивать сам процесс применения АБ-тестирования. За исключением отдельных отраслей (игры, интернет-коммерция), где уже сформировались зрелые практики.
При этом для офлайн-бизнеса внедрение АБ-тестирования во многом организационная, а не математическая проблема. На практике правильно выстроить бизнес-процесс применения АБ и позиционирования его внутри компании едва ли не сложнее, чем создать правильную статистическую методологию.
В этой статье я поделюсь своим опытом и советами о том, как это сделать.

Вероятно, все уже слышали о Stable Diffusion - модели, способной создавать фотореалистичные изображения на основе текста. Благодаря библиотеке diffusers от HuggingFace, использование этой модели очень просто.
Однако организация проекта и зависимостей для его запуска независимо от среды (будь то локально или в облаке), все еще может быть сложной задачей.
В этой статье, я на простом примере расскажу о том, как решать эту проблему с помощью diffusers и dstack.
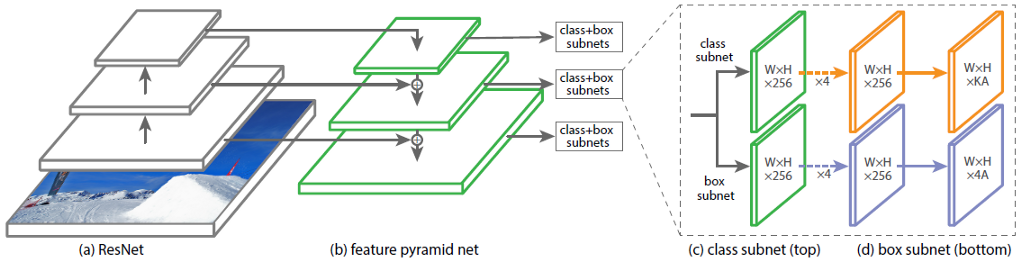
Привет, меня зовут Михаил Ройзнер. Недавно я выступил перед студентами Малого Шада Яндекса с лекцией о том, что такое рекомендательные системы и какие методы там бывают. На основе лекции я подготовил этот пост.
План лекции: