
Cобрала ссылки на ресурсы Harvard, Yale, Stanford, Washington Universities по оформлению резюме под американские и международные вакансии. Подходит для удаленных вакансий, проверено на собственной шкуре.

Пользователь
Cобрала ссылки на ресурсы Harvard, Yale, Stanford, Washington Universities по оформлению резюме под американские и международные вакансии. Подходит для удаленных вакансий, проверено на собственной шкуре.

Ноутбук — главный девайс в моей жизни, я провожу за ним бо́льшую часть суток. Он должен быть лёгким, компактным и мощным. Долгое время лидером по этим параметрам был Dell XPS 13, но всё поменялось с выходом MacBook Air на процессоре M1.
Air всего на 100 граммов тяжелее XPS 13, но примерно в три раза мощнее, автономнее и не нуждается в активном охлаждении. Никогда не думал, что скажу подобное про технику Apple, но MacBook Air — самое крутое устройство в своей весовой категории на рынке, оставившее конкурентов далеко позади.
Я фанат Линукса, эта операционная система для меня больше, чем просто окружение. Это философия, новостная повестка и постоянный предмет обсуждения. Поэтому сама идея отказа от Linux в пользу другой ОС меня всегда отталкивала. Да и тот эпизодический опыт, когда приходилось что-то делать в macOS, был эмоционально неприятным.
Но появление M1 посеяло во мне зерно сомнений: мой ноутбук больше не был самым крутым и навязчивой мыслью было то, что я отказываю себе в чём-то большем. Это зерно прорастало и проросло: я купил MacBook Air с 16GB ОЗУ и 512GB SSD, с удивлением обнаружив, что он ещё и стоит дешевле моего XPS. Впереди меня ожидали настройка окружения, борьба с Docker, грусть от отсутствия привычного автодополнения в консоли и много чего ещё.

Кадр из фильма «Матрица: Революция»
В этой статье мы подробно рассмотрим детали одной интересной находки: два часто используемых системных вызова (gettimeofday, clock_gettime) в AWS EC2 выполняются очень медленно.
В Linux реализован механизм по ускорению этих двух часто используемых системных вызовов, благодаря которому их код выполняется в пространстве пользователя, что позволяет избежать переключениям в контекст ядра. Это сделано с помощью предоставляемой ядром виртуальной общей библиотеки (virtual shared library), которая отображается в адресное пространство всех запущенных программ.
Два вышеназванных системных вызова не могут использовать vDSO (virtual Dynamic Shared Object) в AWS EC2, поскольку виртуализированный источник временных меток (virtualized clock source) в xen (и некоторых конфигурациях kvm) не поддерживает получение информации о времени через vDSO.
Обойти эту проблему не получится. Можно поменять источник информации о времени на tsc, но это небезопасно. Далее мы рассмотрим вопрос более подробно и проведем сравнительное тестирование с помощью microbenchmark.

14.11.2021 — Upd 7. В японский язык добавил Путь бесхвостой птички Адиля Талышханова (Shinrin), в английский — The Mother Tongue — English And How It Got That Way Билла Брайсона (alexey-m-ukolov) и Приключения английского языка Мелвина Брэгга, Введение в прикладную лингвистику Анатолия Баранова к серьезной лингвистике (darkTux)
Upd 6. Добавил Атомы языка Марка Бейкера (9_pm) и The Language Instinct (Язык как инстинкт) Стивена Пинкера (alex518 и snvtr). Проставил у рекомендаций значок ?
Upd 5. Добавил раздел 'Лингвистические задачи'. Лингвистические задачи Зализняка, "Три склянки пополудни" Бердичевского и Пиперски (книга только вышла!) (middle), и еще одни "Лингвистические задачи" от коллектива авторов, включая Алпатова и Зализняка (AlexKarpan и DinaPy). Спасибо всем, кто рекомендует!
Upd 4. Добавил раздел 'Полевая лингвистика'. Не спи — кругом змеи! Дэниела Эверетта (9_pm), добавил "Слово о словах" Льва Успенского (Temmokan и saboteur_kiev)
Upd 3. Добавил раздел 'Серьезно о лингвистике'. Человек говорящий. Эволюция и язык Хомского и Бервика (alex518) и Значение и структура языка Чейфа Л. Уоллеса (darkTux)
Upd 2. Добавил "The Unfolding of Language" Гая Дойчера и "Our Magnificent Bastard Tongue" Джона Макуортера (etoropov)
Upd 1. Добавил раздел 'Грамотность и стиль'. "Слово живое и мертвое" Норы Галь (darkTux) и "The Sense of Style" Стивена Пинкера (9_pm)
Количество атомов в наблюдаемой Вселенной — где-то 10^80, число Дэвидов на картинке к статье — 2. Количество книг в этой подборке находится между этими ориентирами и будет пополняться (всегда рад рекомендациям). Что же это за книги?
По материалам статьи Craig Freedman: Query Failure with Read Uncommitted
В предыдущих статьях были рассмотрены практически все уровни изоляции, за исключением Read Uncommitted или NOLOCK. Эта статья завершает серию обсуждением того, что может приключиться, если читать данные ещё не зафиксированных транзакций. О вреде NOLOCK написано уже немало. Например, вы могли об этом почитать у Любора Коллара (Lubor Kollar) из «SQL Server Development Customer Advisory Team» и в (ныне уже недоступном) блоге Тони Роджерсона (Tony Rogerson).
В дополнение к многочисленным аргументам, ниже будет продемонстрирована еще одна опасность NOLOCK. Начнём с создания двух таблиц:
Опубликовано 23 марта 2019 г., впервые опубликовано в MSDN 12 июня 2007 г.



Вторая статья цикла "Природа музыкальных ощущений". В ней продолжение вскрытия внутреннего содержания музыки - обоснование и объяснение эмпирических ощущений которые производят лады, звуки и музыкальные интервалы. Также подробно объясняю происхождение и логику названий звуков(нот) и интервалов.

 Привет, Хаброжители! Когда дело доходит до выбора, использования и обслуживания базы данных, важно понимать ее внутреннее устройство. Как разобраться в огромном море доступных сегодня распределенных баз данных и инструментов? На что они способны? Чем различаются?
Привет, Хаброжители! Когда дело доходит до выбора, использования и обслуживания базы данных, важно понимать ее внутреннее устройство. Как разобраться в огромном море доступных сегодня распределенных баз данных и инструментов? На что они способны? Чем различаются?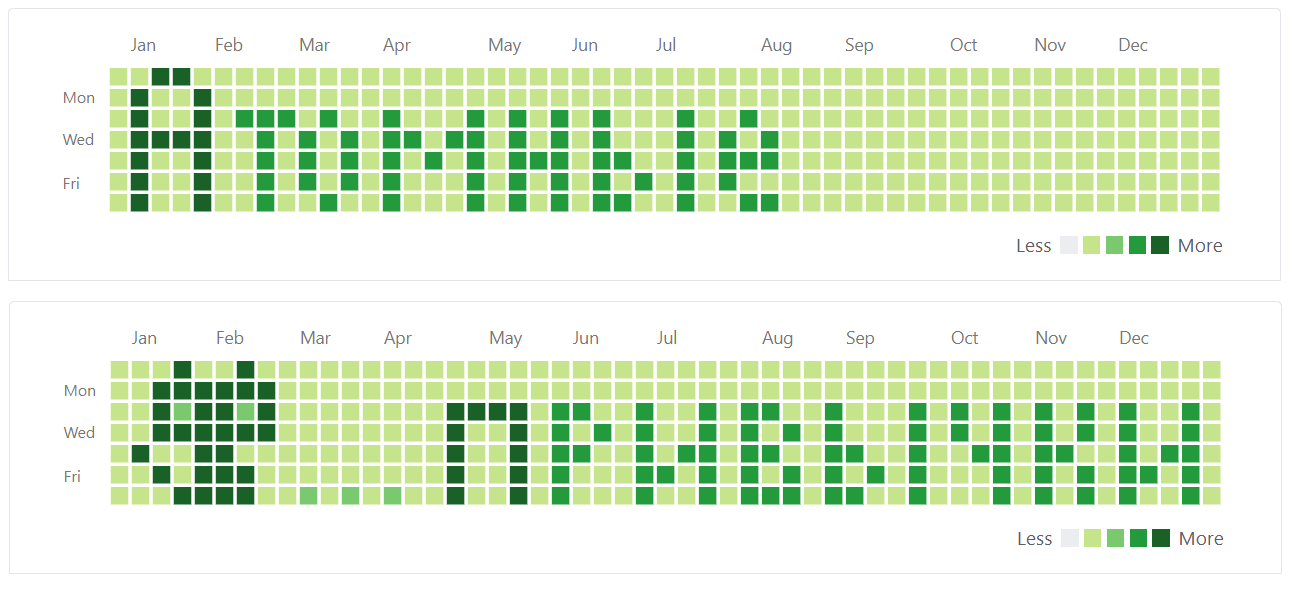
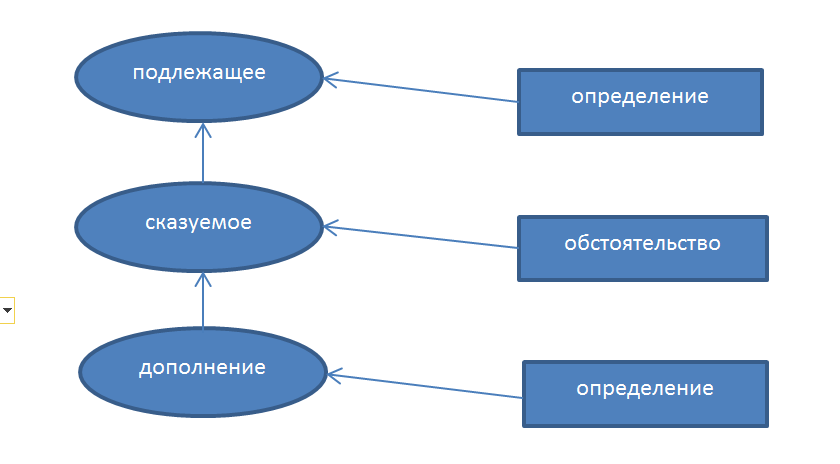
В данной статье приводится краткое описание основных особенностей, проблем и сложностей, которые автору пришлось решать при реализации программы морфологической и синтаксической обработки текстов на русском языке.
Была поставлена задача создания программы морфологической и синтаксической обработки грамотно составленных текстов на русском языке с перспективой последующего объединения с семантическим анализатором. В связи с тем, что русский язык имеет некоторую логику построения, то виделось возможным обработать данную языковую логику классическим программным способом (без использования нейросетей), при этом учитывались следующие соображения. Классическая программа обладает максимальной гибкостью при создании изощренных алгоритмов обработки; сами алгоритмы ориентируются на формализованные конструкции словосочетаний, обрабатывают не конкретные слова, а типы слов, что позволяет легко справляться с новыми словами, возникающими в языке достаточно часто. Данный подход видится целесообразным и при дальнейшем развитии программы – включение семантического анализатора в общий сквозной процесс обработки текстов.
В результате данная задача была в целом выполнена (пока без семантической обработки). Резюмируя пройденный этап, важно отметить ключевые технические задачи в рамках синтаксического разбора, которые требовали решения: выделение из всего множества единственно верной (наиболее вероятной) связи главного и зависимого слова плюс параллельный с этим выбор единственной морфологической формы слова среди множества возможных омонимов.

Не так давно в качестве хобби решил погрузиться в изучение embedded разработки на Rust и через какое-то время мне захотелось сделать себе логгер, который бы просто писал логи через UART, но который бы при этом не знал какая конкретно реализация используется. И вот тут я быстро осознал, именно в этом конкретном случае я не могу полагаться на статический полиморфизм и мономорфизацию, ведь компилятор не знает сколько нужно памяти выделять под конкретную реализацию. Фактически это означает, что нам нужно как-то уметь сохранять типы, размер которых неизвестен на этапе компиляции, и такой способностью обладает тип Box и для решения этой проблемы как раз и возникла идея написать свой аналог типа Box, но который сохраняет обьект не в куче, а в предоставленном пользователем буфере.

При реализации потоковых алгоритмов часто возникает задача подсчёта каких-то событий: приход пакета, установка соединения; при этом доступная память может стать узким местом: обычный  -битный счётчик позволяет учесть не более
-битный счётчик позволяет учесть не более  событий.
событий.
Одним из способов обработки большего диапазона значений, используя то же количество памяти, является вероятностный подсчёт. В этой статье будет предложен обзор известного алгоритма Морриса, а также некоторых его обобщений.
Другой способ уменьшить количество бит, необходимое для хранения значения счётчика, — использование распада. Об этом подходе мы рассказываем здесь, а также собираемся в ближайшее время опубликовать ещё одну заметку по теме.
Мы начнём с разбора простейшего алгоритма вероятностного подсчёта, выделим его недостатки (раздел 2). Затем (раздел 3) опишем алгоритм, впервые преложенный Робертом Моррисом в 1978 году, укажем его важнейшие свойства и приемущества. Для большинства нетривиальных формул и утверждений в тексте присутствуют наши доказательства — интересующийся читатель сможет найти их во вкладышах. В трёх последующих разделах мы изложим полезные расширения классического алгоритма: вы узнаете, что общего у счётчиков Морриса и экспоненциального распада, как можно уменьшить ошибку, пожертвовав максимальным значением, и как эффективно обрабатывать взвешенные события.
Ниже представлен перевод одной из частей серии статей Rust Crash Course от Майкла Сноймана, которая посвящена механизмам передачи параметров, итераторам и замыканиям относительно того, как передаётся владение, и соотносится с мутабельностью и временами жизни.
Так же постарался переводить максимально близко к авторскому стилю, но сократил немного междомедий и восклицаний, не сильно значимых для смысла.


Мне самому не верится в то, что я сейчас пишу. Еще только пять лет назад я жил в небольшом провинциальном городе Пенза и работал программистом в среднего размера геймдев-компании за очень небольшие деньги. Жил я так сказать не тужил - я потихоньку работал, учился, строил какие-то планы, но особых амбиций не имел, а плыл так сказать по течению. Пока одним холодным осенним вечером не познакомился с человеком, навсегда изменившим мою жизнь.
Он был на несколько лет старше меня и тоже работал программистом, но в отличии от меня он работал на западных заказчиков и получал за свою работу гораздо больше, чем я. Но это было не главное, что меня поразило - впервые я встретил человека, который был настолько активен, столько всего знал и занимался сразу кучей интереснейших проектов. К счастью для меня, он с радостью поделился со мной секретами своей продуктивности, которые оказались совсем не секретами, а информацией, которой просто переполнен интернет. Так я познакомился с миром инструментов и техник личной эффективности.
Это дало мне сильнейший толчок и изменило мою жизнь до неузнаваемости. За прошедшие пять лет я попутешествовал по куче стран, полтора года прожил в солнечной Черногории, переехал в Израиль, несколько раз менял работу на компании с гораздо лучшими условиями, в последний раз устроившись на работу, на которой мой доход в более чем 15 раз превышает мой доход пять лет назад, и на которой я делаю продукты для всемирно известных корпораций и организаций, создал три более-менее успешных open-source проекта на Github и написал множество статей на Хабрахабр, некоторые из которых имели ошеломительный успех у читателей.
В течение этих пяти лет я перепробовал множество техник и инструментов личной продуктивности. Какие-то из них работали плохо, какие-то оказались весьма эффективными. Я собрал все зарекомендовавшие себя методы в единый фреймворк, помогающий мне определять свои желания и направления для развития, ставить четкие цели, разбивать путь к ним на отдельные шаги и достигать их. Этим самым фреймворком я и хочу с вами поделиться.
Для кого-то этот пост может показаться сборником давно знакомых инструментов, а кто-то найдет здесь кладезь полезной информации. Ну что ж, поехали...
Статей о TDD достаточно много, и я обратил внимание на то, что все они затрагивают преимущественно техническую составляющую этого подхода, и практически никак не описывают ментальные принципы, лежащие в основе TDD.
Поэтому я не хотел писать еще одну статью с описанием техники Red-Green-Refactor. Мне хотелось взглянуть на TDD немного глубже и описать, как и почему TDD влияет на поведение человека.
В статье речь пойдет о неких абстракциях, которые применимы на разных слоях мировоззрения и, вне зависимости от контекста, помогают достигать хорошего результата. Универсальность этих абстракций и факт, что они применимы даже к процессу написания кода, сделали меня ярым приверженцем как TDD подхода, так и этих абстракций.