Привет! Мы в QIWI довольно давно применяем микросервисную архитектуру, но ее понимание не всегда было одинаковым: оно менялось со временем и эволюционировало. Наши первые микросервисы были достаточно большие по объему, но сейчас мы создаем сервисы гораздо меньшего размера с более узкой и ограниченной зоной ответственности.
Часто такой сервис отвечает за конкретную небольшую фичу в нашем продукте (или вообще за часть фичи), или же за часть какого-то большого процесса. Нам такой подход нравится, поскольку микросервисы имеют независимые жизненные и релизные циклы, мы можем релизить фичи независимо друг от друга. Кроме того, различные команды могут работать в рамках одного продукта параллельно над разными фичами, не мешая друг другу и не сталкиваясь лбами. Это даёт нам возможность независимо масштабировать микросервисы и гораздо быстрее проверять гипотезы. В общем, плюсов много.
Сейчас будет «Но», правда?
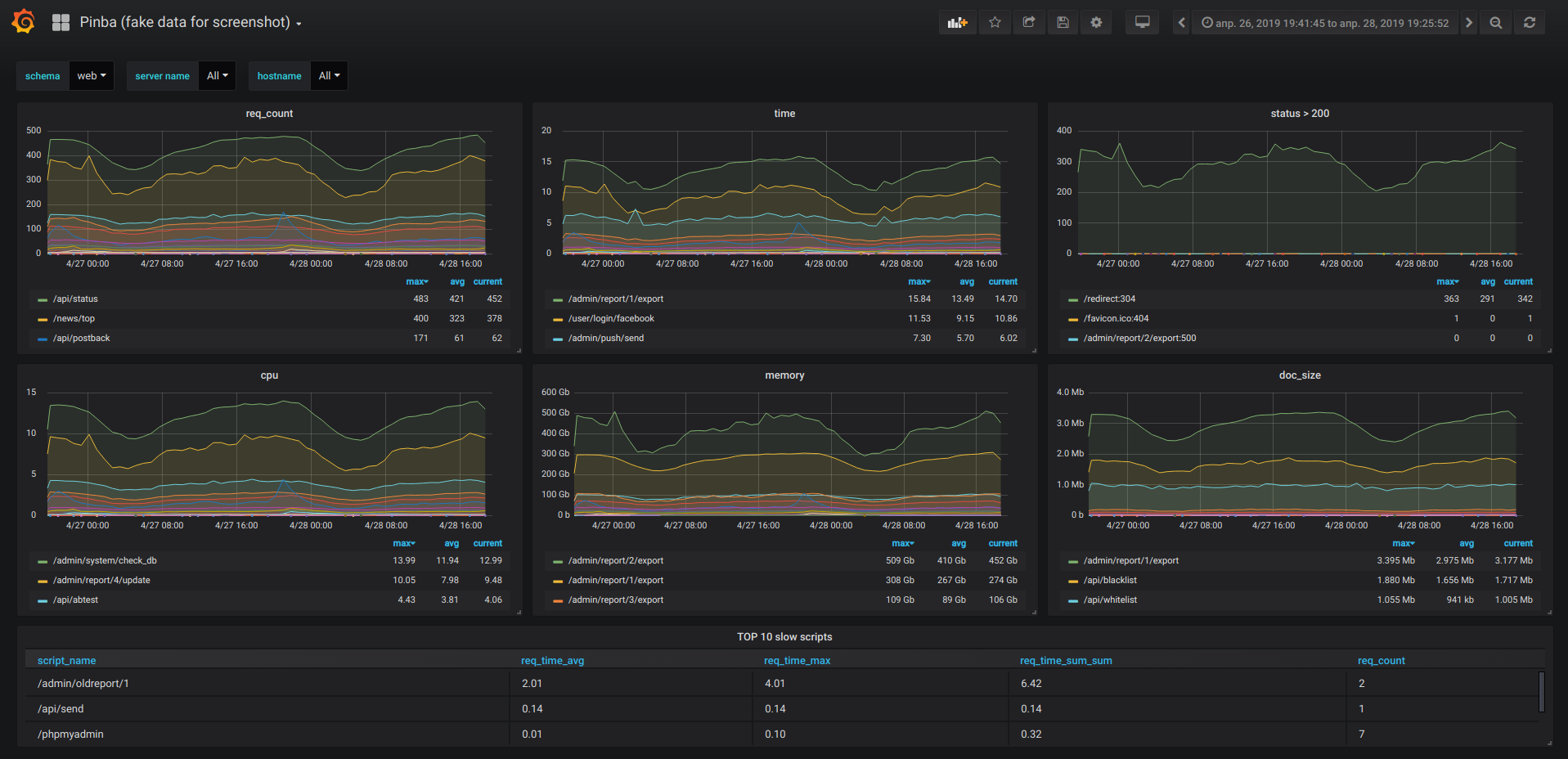
Но в системе, которая состоит из большого количества маленьких взаимодействующих компонентов, становится критически важным такое качество, как наблюдаемость. Нам нужны как некие высокоуровневые метрики, показатели, чтобы видеть, как система живет в целом, так и для каждого компонента, для каждого нашего микросервиса —нужно видеть его текущие рабочие показатели и получать уведомления, если эти показатели выходят за пределы нормы. Поскольку новые фичи мы делаем часто, то и новые микросервисы мы разрабатываем часто, получилось так, что настройка дашбордов и конфигурация алертов превратились в такую рутину, которая отнимает существенную часть времени. Так что всё это хотелось бы автоматизировать.