
 Alyson La, Data science в GitHub: В октябре этого года я отпраздновала свой пятилетний юбилей работы в GitHub. 5 лет назад я была бухгалтером, который ничего не знал о программировании, не говоря уже об использовании Git и GitHub.
Alyson La, Data science в GitHub: В октябре этого года я отпраздновала свой пятилетний юбилей работы в GitHub. 5 лет назад я была бухгалтером, который ничего не знал о программировании, не говоря уже об использовании Git и GitHub.Теперь я энтузиаст Data Scientist, который знает некоторые вещи о написании кода с помощью Git & GitHub. Частично благодаря изучению этих технологий я сделала этот карьерный переход.
Но даже работая в GitHub, изучать Git и GitHub было сложно! Поэтому я хочу поделиться 5-ью советами по использованию GitHub с другими людьми, новичками программирования.
Совет № 1: Измените редактор по умолчанию
Для многих людей текстовый редактор при использовании Git через терминал — VIM. VIM может быть ужасным, страшным для нового или казуального хакера. Или даже для ветеранов-хакеров как @haacked.
Если вы когда-нибудь столкнетесь с конфликтами слияния (а вы их встретите, см. совет №4), вы попадете в VIM, чтобы исправить конфликт, и вам нужно будет знать конкретные команды VIM для редактирования документа иначе вам захочется плакать. Больше года у меня была заметка на мониторе для напоминания основных команд VIM, таких как i (для редактирования) и: wq (для сохранения и выхода). Чтобы избежать боли, вы можете просто выбрать другой текстовый редактор.

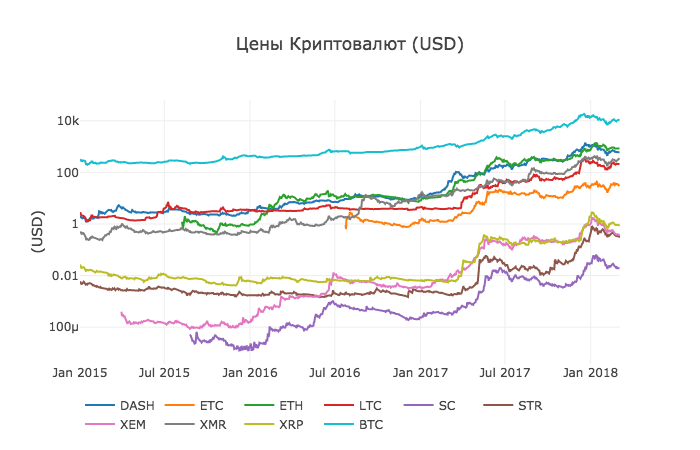


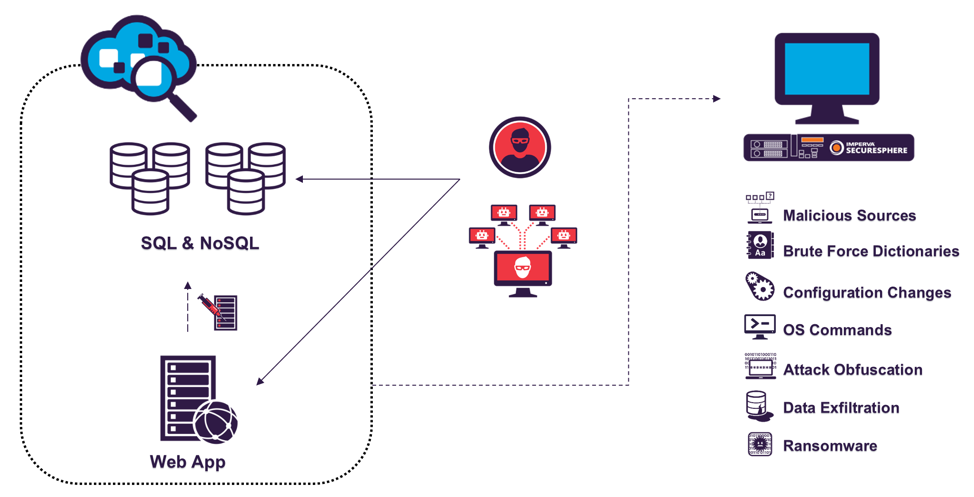




 Добрый день/вечер/ночь/утро! Есть один экспериментальный курс по операционным системам. Есть он в Стэнфордском университете. Но часть материалов доступно всем желающим. Помимо слайдов доступны полные описания практических занятий.
Добрый день/вечер/ночь/утро! Есть один экспериментальный курс по операционным системам. Есть он в Стэнфордском университете. Но часть материалов доступно всем желающим. Помимо слайдов доступны полные описания практических занятий. 
