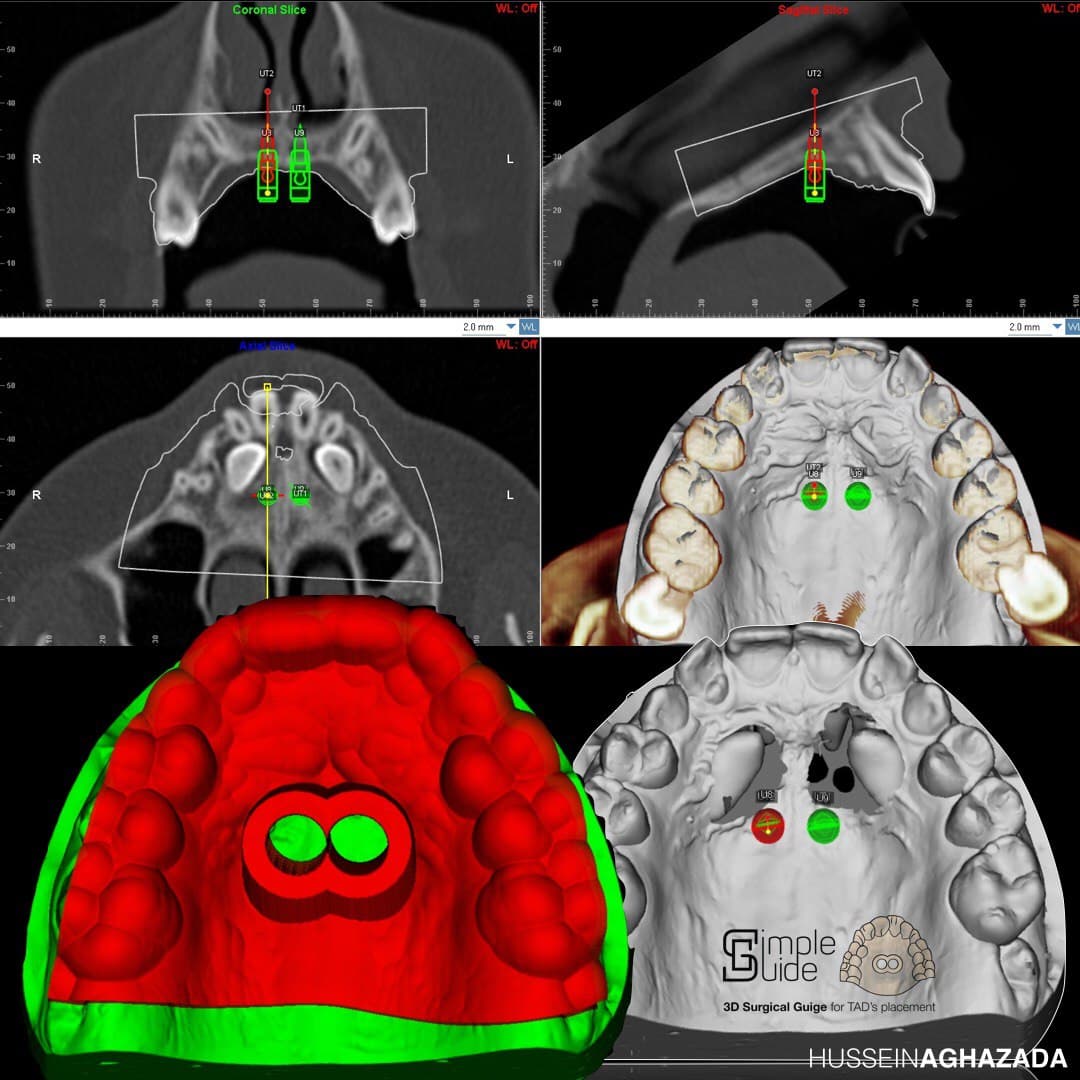
 Этими винтами хочется попадать в нужное место кости очень точно и под очень правильным углом.
Этими винтами хочется попадать в нужное место кости очень точно и под очень правильным углом.
Привет, Хабр! Меня зовут Гусейн, я стоматолог, который специализируется на сложной ортодонтии — перемещении зубов. В общем, я в соавторстве ещё с парой итальянских коллег и одним немецким изобрёл математическую модель расчёта оптимального места под винты, которые мы вкручиваем в нёбо, используя их как опору для аппаратов. И такой метод их вкручивания, что врачу не остаётся почти никакого шанса на ошибку. И техническую реализацию всего этого.
Коротко это выглядит так: делаем оптический слепок рта внутриротовым сканером изнутри, накладываем поверх этого данные КТ, загоняем в аналог Архикада для ортодонтов (Dolphin), совмещаем, рассчитываем оптимальное место для имплантов — мини-винтов, печатаем навигационный шаблон из пластика и выпекаем лазером аппарат, потом вставляем одно в другое, потом вкручиваем это в пациента и радуемся. Получается идеальная точность. А это, знаете ли, важно, когда вы решаете взять и раздвинуть кости черепа ребёнку.
Зачем раздвигать нёбо ребёнку? Потому что так получилось, что детям нужно дышать. И иногда из-за неправильного развития мышц или генетики нёбо получается не той формы, чтобы кислород в достаточном количестве попадал к мозгу. Ребёнок начинает отставать в развитии и приобретает вид юного алкоголика (я имею в виду мешки под глазами).
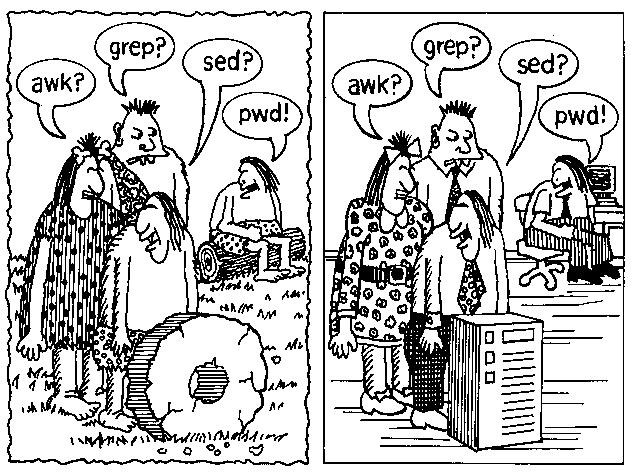
Раньше винты вкручивали на глаз, и это было более травматично и немного неточно. Чуточку. Раз в пять. Под катом будет несколько фотографий фрагментов головы человека с не совсем привычных ракурсов, поэтому, если вы кушаете, то, возможно, стоит сначала доесть, а потом открывать пост.